大型分布式C++框架《四:netio之buffer管理器 下》
每周一篇又来了。这次主要介绍netio的buffer管理器。 首先buffer管理是每一个网络层不可回避的问题。怎么高效的使用buffer是很关键的问题。这里主要介绍下我们的netio是怎么处理。说实话 这是我见过比较蛋疼buffer管理。 反正我是看了好几天 才看明白的。
最近看了下Qcon2016的视频.里面很多大牛介绍分布式平台。 感觉特别牛逼~~。 感觉我们的分布式相比他们的这些还是简陋了点。感兴趣的同学可以去看看
http://daxue.qq.com/content/special/id/20
1.1 我们先看下 一次系统调用recv就能收到完整包的情况

int CNetHandleMng::_RetrievePkgData(int nHandle,char* pRcvBuf,int nBufLen)
{
......
//当前数据包已经读取完成
m_pSink->OnRecv(nHandle,pRcvBuf+TPT_HEAD_LEN,dwPkgLen);
return (dwPkgLen + TPT_HEAD_LEN);
}
int CNetHandleMng::OnRecv(int nHandle,char* pRcvBuf,int nBufLen)
{
stConn* pConn = _GetConn(nHandle);
if( NULL == pConn )
{
std::stringstream oss;
oss<<"reactor report recv data for connection handle"<<nHandle<<" but we cann't found the connection data"<<std::endl;
m_pSink->ReportTptError(__FILE__,__LINE__,__func__,oss.str().c_str());
return ;
} int nReadLen =;
if( == pConn->m_pRcvBuf->m_nDataLen )
{ nReadLen = _RetrievePkgsData(nHandle,pRcvBuf,nBufLen);
if( nReadLen < )
return nReadLen;//reactor层会自动关闭连接 if( nReadLen >= nBufLen )
return ;//数据已经处理完毕
.....
}
我们发现在一次recv能收完整个数据包的时候。平台没用字节的buf管理器。而是直接就给netio app类来处理了
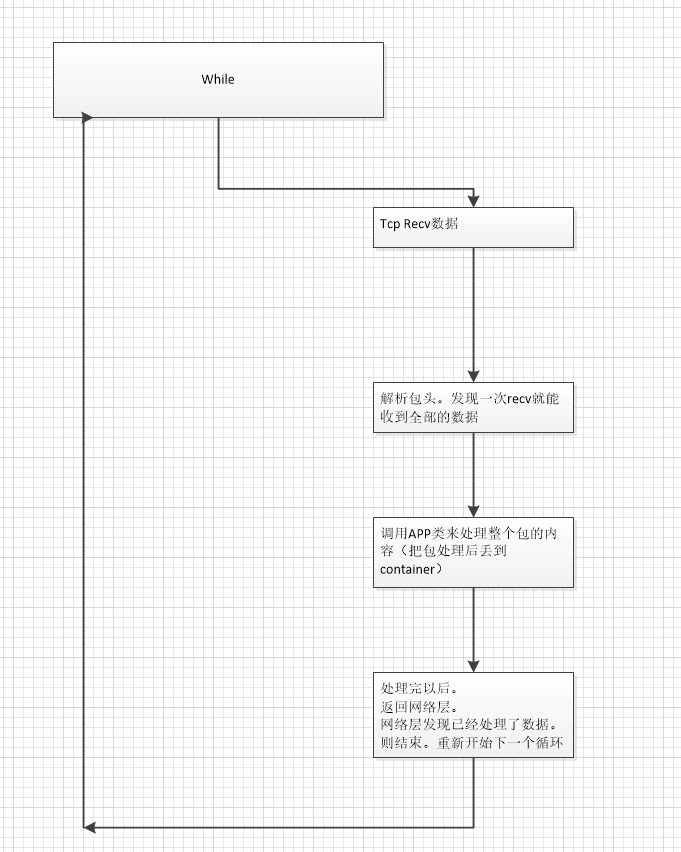
1.2 我们先看下 一次系统调用recv收不完包的情况。

CNetioApp::CNetioApp():CNetMsgqSvr(4096*5,1024*1024,4*1024)规定了一个最大请求包是 1024*1024
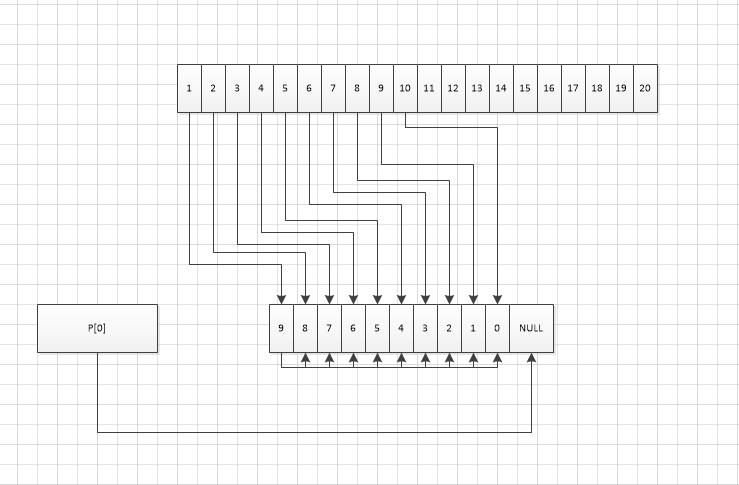
所以初始化的时候 会设置一个大小为256的二维指针。注意这里只是创建二维指针。当时并没有给每个指针指向的对象分配空间。
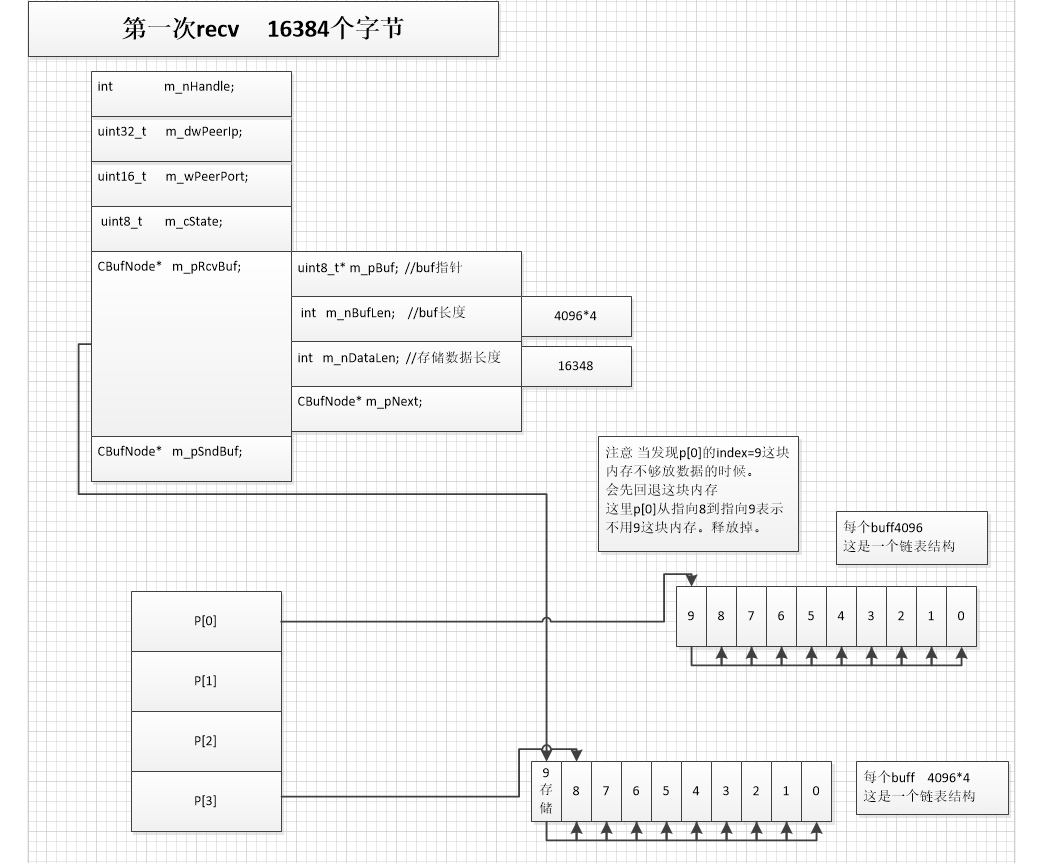
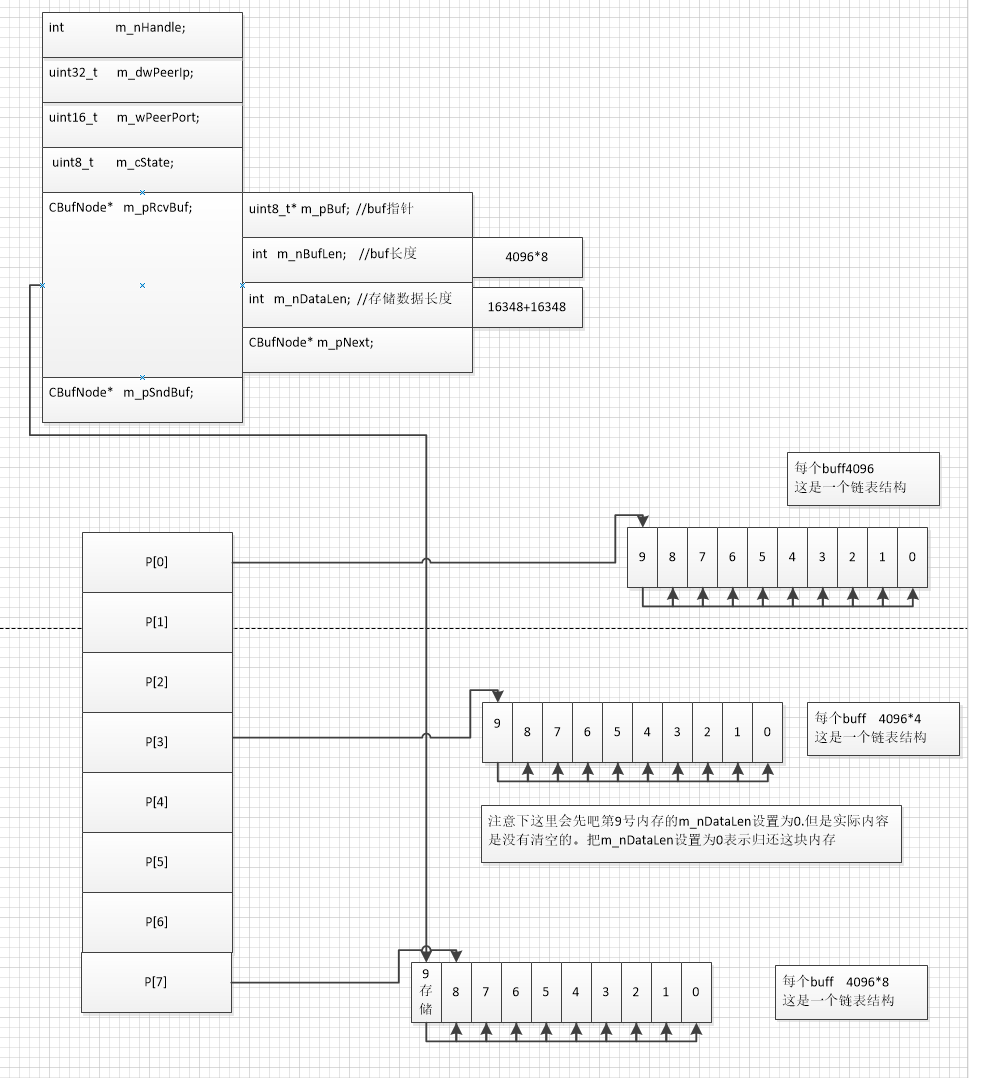
1.2.2 . 正常情况下的buffer总大小

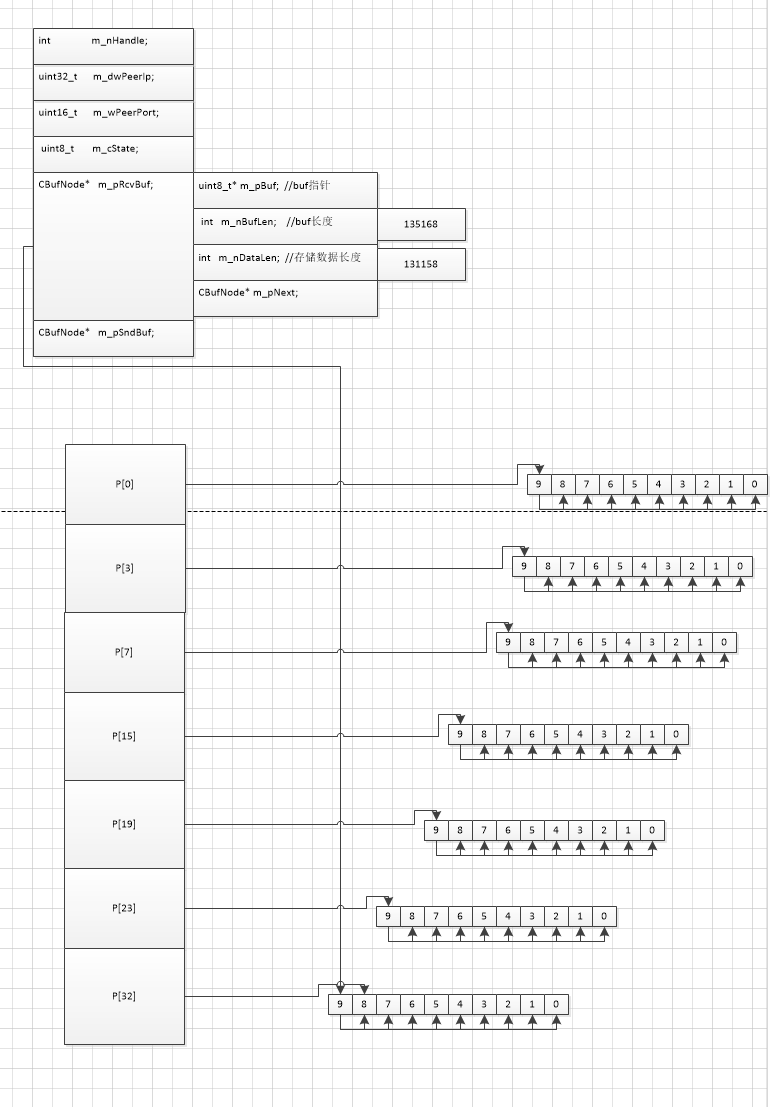
1.2.3 . 高并发场景下 buffer的总大小


大型分布式C++框架《四:netio之buffer管理器 下》的更多相关文章
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
- 开源分享 Unity3d客户端与C#分布式服务端游戏框架
很久之前,在博客园写了一篇文章,<分布式网游server的一些想法语言和平台的选择>,当时就有了用C#做网游服务端的想法.写了个Unity3d客户端分布式服务端框架,最近发布了1.0版本, ...
- Django准备知识-web应用、http协议、web框架、Django简介
一.web应用 Web应用程序是一种可以通过web访问的应用程序(web应用本质是基于socket实现的应用程序),程序的最大好处是用户很容易访问应用程序,用户只需要有浏览器即可,不需要再安装其他软件 ...
- Unity 游戏框架搭建 2018 (一) 架构、框架与 QFramework 简介
约定 还记得上版本的第二十四篇的约定嘛?现在出来履行啦~ 为什么要重制? 之前写的专栏都是按照心情写的,在最初的时候笔者什么都不懂,而且文章的发布是按照很随性的一个顺序.结果就是说,大家都看完了,都还 ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎
Python分布式爬虫必学框架Scrapy打造搜索引擎 部分课程截图: 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/1-wHr4dTAxfd51M ...
- Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌
Python分布式爬虫必学框架Scrapy打造搜索引擎 ✌✌ (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 第1章 课程介绍 介绍课程目标.通过课程能学习到 ...
- Django框架-目录文件简介
Rhel6.5 Django1.10 Python3.5 Django框架-目录文件简介 1.介绍Django Django:一个可以使Web开发工作愉快并且高效的Web开发框架. 使用Django, ...
- Net框架下-ORM框架LLBLGen的简介
>对于应用程序行业领域来说,涉及到Net框架的,在众多支持大型项目的商用ORM框架中,使用最多的目前了解的主要有三款: 1.NHibernate(从Java版移植来的Net版). 2.微软的EF ...
- Unity3d&C#分布式游戏服务器ET框架介绍-组件式设计
前几天写了<开源分享 Unity3d客户端与C#分布式服务端游戏框架>,受到很多人关注,QQ群几天就加了80多个人.开源这个框架的主要目的也是分享自己设计ET的一些想法,所以我准备写一系列 ...
- asp.Net Core免费开源分布式异常日志收集框架Exceptionless安装配置以及简单使用图文教程
最近在学习张善友老师的NanoFabric 框架的时了解到Exceptionless : https://exceptionless.com/ !因此学习了一下这个开源框架!下面对Exceptionl ...
随机推荐
- Task的运行过程分析
Task的运行过程分析 Task的运行通过Worker启动时生成的Executor实例进行, caseRegisteredExecutor(sparkProperties)=> logInfo( ...
- [转] vim 正则表达式 很强大
毋庸多言,在vim中正则表达式得到了十分广泛的应用. 最常用的 / 和 :s 命令中,正则表达式都是不可或缺的. 下面对vim中的正则表达式的一些难点进行说明. 关于magic vim中有个magic ...
- TP框架多表联查
join方法import("@.ORG.Page"); $Form = M('gly'); $where=''; if ($_PO ...
- oracle、db2、sybase大型数据库面试总结
1. oracle数据库单例.多例模式. 数据库创建之后会有一系列为该数据库提供服务的内存空间和后台进程,称为该数据库的实例. 每一个数据库至少会有一个实例为其服务. 2. mysql获取字段的长度用 ...
- c - 水仙花数.
#include <stdio.h> #include <math.h> /* *打印出所有的“水仙花数” ,所谓“水仙花数”是指一个三位数,其各位数字立方和等于该数本身. * ...
- iptables里filter表前面几个数字的意思
一般的linux系统iptables配置文件filter表前面都带下面三行,但是具体是什么意思呢! *filter:INPUT ACCEPT [0:0]:FORWARD ACCEPT [0:0]:OU ...
- gc内存回收机制
判断哪些对象可回收 GC是通过对象是否存活来决定是否进行回收,判断对象是否存活主要有两种算法:引用计数算法.可达性分析算法 引用计数算法 引用计数的算法原理是给对象添加一个引用计数器,每被引用一次计数 ...
- 给控制器添加工具栏(Swift语言)
//懒加载工具条 private lazy var toolBar: UIToolbar = UIToolbar() //设置底部的工具条 private func setToolBar() { // ...
- Mysql 5.7.9 cmake boost.cmake 处理
环境Centos 6.7 x64 mininal 今天突然编译Mysql 5.7.9 按之前的cmake .的方式 发现报错了..提示 需要boost -- BOOST_INCLUDE_DIR /us ...
- 一个使用CSocket类的网络通信实例
http://www.cppblog.com/changshoumeng/archive/2010/05/14/115413.html 3.8 一个使用CSocket类的网络通信实例 本例采用CSoc ...