tensorflow进阶篇-5(反向传播1)
这里将讲解tensorflow是如何通过计算图来更新变量和最小化损失函数来反向传播误差的;这步将通过声明优化函数来实现。一旦声明好优化函数,tensorflow将通过它在所有的计算图中解决反向传播的项。当我们传入数据,最小化损失函数,tensorflow会在计算图中根据状态相应的调节变量。
这里先举一个简单的例子,从均值1,标准差为0.1的正态分布中随机抽样100个数,然后乘以变量A,损失函数L2正则函数,也就是实现函数X*A=target,X为100个随机数,target为10,那么A的最优结果也为10。
实现如下:
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.python.framework import ops ops.reset_default_graph() # 创建计算图
sess = tf.Session() #生成数据,100个随机数x_vals以及100个目标数y_vals
x_vals = np.random.normal(1, 0.1, 100)
y_vals = np.repeat(10., 100)
#声明x_data、target占位符
x_data = tf.placeholder(shape=[1], dtype=tf.float32)
y_target = tf.placeholder(shape=[1], dtype=tf.float32) # 声明变量A
A = tf.Variable(tf.random_normal(shape=[1])) #乘法操作,也就是例子中的X*A
my_output = tf.multiply(x_data, A) #增加L2正则损失函数
loss = tf.square(my_output - y_target) # 初始化所有变量
init = tf.initialize_all_variables()
sess.run(init) #声明变量的优化器;大部分优化器算法需要知道每步迭代的步长,这距离是由学习控制率。
my_opt = tf.train.GradientDescentOptimizer(0.02)
train_step = my_opt.minimize(loss) #训练,将损失值加入数组loss_batch
loss_batch = []
for i in range(100):
rand_index = np.random.choice(100)
rand_x = [x_vals[rand_index]]
rand_y = [y_vals[rand_index]]
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
print('Step #' + str(i + 1) + ' A = ' + str(sess.run(A)))
print('Loss = ' + str(sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})))
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
loss_batch.append(temp_loss) plt.plot( loss_batch, 'r--', label='Batch Loss, size=20')
plt.legend(loc='upper right', prop={'size': 11})
plt.show()
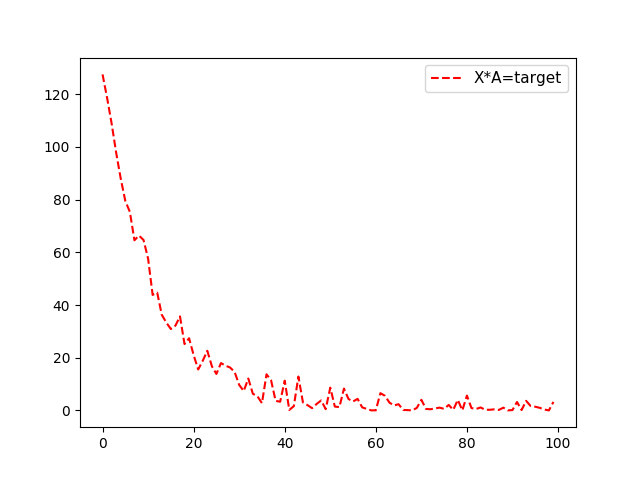
输出结果(输出A以及对应的损失函数):
Step #1 A = [ 0.08779037]
Loss = [ 98.3597641]
Step #2 A = [ 0.48817557]
Loss = [ 90.38272095]
Step #3 A = [ 0.85985768]
Loss = [ 83.92495728]
Step #4 A = [ 1.289047]
Loss = [ 71.54370117]
.........
Step #98 A = [ 10.10386372]
Loss = [ 0.00271681]
Step #99 A = [ 10.10850525]
Loss = [ 0.01301978]
Step #100 A = [ 10.07686806]
Loss = [ 0.5048126]
对于损失函数看这里:tensorflow进阶篇-4(损失函数1),tensorflow进阶篇-4(损失函数2),tensorflow进阶篇-4(损失函数3)
tensorflow进阶篇-5(反向传播1)的更多相关文章
- tensorflow进阶篇-5(反向传播2)
上面是一个简单的回归算法,下面是一个简单的二分值分类算法.从两个正态分布(N(-1,1)和N(3,1))生成100个数.所有从正态分布N(-1,1)生成的数据目标0:从正态分布N(3,1)生成的数据标 ...
- tensorflow学习笔记(2)-反向传播
tensorflow学习笔记(2)-反向传播 反向传播是为了训练模型参数,在所有参数上使用梯度下降,让NN模型在的损失函数最小 损失函数:学过机器学习logistic回归都知道损失函数-就是预测值和真 ...
- 【TensorFlow篇】--反向传播
一.前述 反向自动求导是 TensorFlow 实现的方案,首先,它执行图的前向阶段,从输入到输出,去计算节点值,然后是反向阶段,从输出到输入去计算所有的偏导. 二.具体 1.举例 图是第二个阶段,在 ...
- tensorflow进阶篇-4(损失函数2)
Hinge损失函数主要用来评估支持向量机算法,但有时也用来评估神经网络算法.下面的示例中是计算两个目标类(-1,1)之间的损失.下面的代码中,使用目标值1,所以预测值离1越近,损失函数值越小: # U ...
- tensorflow进阶篇-4(损失函数1)
L2正则损失函数(即欧拉损失函数),L2正则损失函数是预测值与目标函数差值的平方和.L2正则损失函数是非常有用的损失函数,因为它在目标值附近有更好的曲度,并且离目标越近收敛越慢: # L = (pre ...
- tensorflow进阶篇-3
#-*- coding:utf-8 -*- #Tensorflow的嵌入Layer import numpy as np import tensorflow as tf sess=tf.Session ...
- tensorflow进阶篇-4(损失函数3)
Softmax交叉熵损失函数(Softmax cross-entropy loss)是作用于非归一化的输出结果只针对单个目标分类的计算损失.通过softmax函数将输出结果转化成概率分布,然后计算真值 ...
- [2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)
TensorFlow Playground http://playground.tensorflow.org 帮助更好的理解,游乐场Playground可以实现可视化训练过程的工具 TensorFlo ...
- Tensorflow笔记——神经网络图像识别(一)前反向传播,神经网络八股
第一讲:人工智能概述 第三讲:Tensorflow框架 前向传播: 反向传播: 总的代码: #coding:utf-8 #1.导入模块,生成模拟数据集 import t ...
随机推荐
- javascript 根据 两点 经纬度 测出距离
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- git服务器使用
服务器版本:CentOS6.3 root用户密码:123456 服务器地址:192.168.1.125 搭建Git服务器参考:搭建Git服务器 使用git服务器首先要克隆仓库,即添加一个远程仓库,参考 ...
- MIT Molecular Biology 笔记3 DNA同源重组
视频 https://www.bilibili.com/video/av7973580?from=search&seid=16993146754254492690 教材 Molecular ...
- 老树新芽,在ES6下使用Express
要让Express在ES6下跑起来就不得不用转码器Babel了.首先新建一个在某目录下新建一个项目.然后跳转到这个目录下开始下面的操作. 简单走起 安装babel-cli $ npm install ...
- VS2008 + QGIS1.7.1试验
今天试验了一下.结果算是成功了吧.显示Generate done,生成了.但是提示了一个“SVN version不明确”的错误提示,应该无大碍吧.但是打开Build成的.sln也没看出有啥不妥. 用C ...
- JDBC架构
JDBC API支持两层和三层处理模型进行数据库访问,但在一般的JDBC体系结构由两层组成: JDBC API: 提供了应用程序对JDBC的管理连接. JDBC Driver API: 支持JDBC管 ...
- ScheduledExecutorService的使用
http://407827531.iteye.com/blog/1329597 ScheduledExecutorService接口 在ExecutorService的基础上,ScheduledExe ...
- spark的shuffle机制
对于大数据计算框架而言,Shuffle阶段的设计优劣是决定性能好坏的关键因素之一.本文将介绍目前Spark的shuffle实现,并将之与MapReduce进行简单对比.本文的介绍顺序是:shuffle ...
- hdu 5095 多项式模拟+有坑
http://acm.hdu.edu.cn/showproblem.php?pid=5095 就是把ax^2 + by^2 + cy^2 + dxy + eyz + fzx + gx + hy + i ...
- redis-master/slave模式
类似mysql的master-slave模式一样,redis的master-slave可以提升系统的可用性,master节点写入cache后,会自动同步到slave上. 环境: master node ...