EUREKA原理总结
Eureka高可用架构
https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance
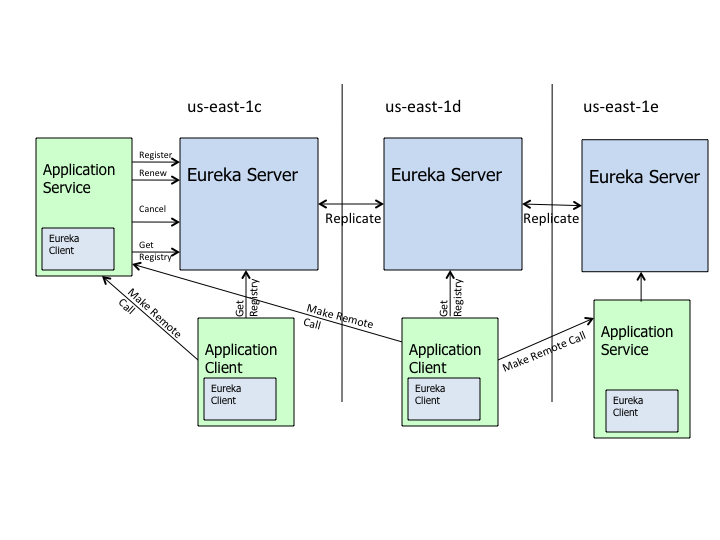
上图中主要的名称说明:
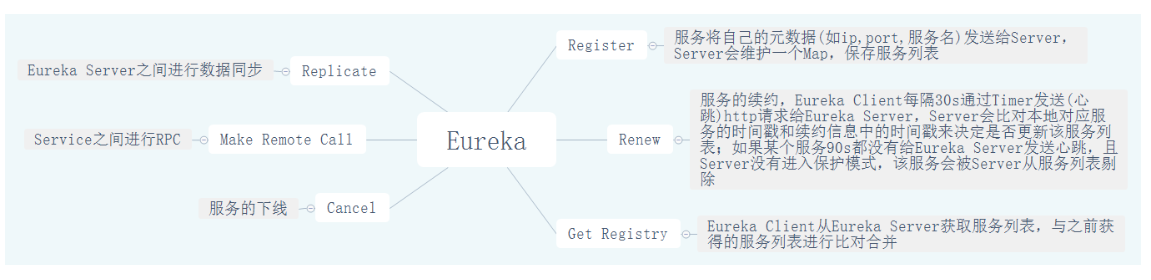
- Register:EurekaClient注册(Http请求)到EurekaServer,EurekaClient会发送自己元数据(ip,port,主页等),EurekaServer会将其添加到服务注册列表ConcurrentHashMap里
- Renew:EurekaClient默认每30秒发送心跳(timer定时任务,发送Http请求)到EurekaServer续约,向EurekaServer证明其活性,EurekaServer将EurekaClient心跳中的时间戳参数与已有服务列表中对应的该服务的时间戳进行比较,不相等就更新对应的服务列表;如果EurekaServer 90秒都没收到某个EurekaClient的续约,并且没有进入保护模式,就会将该服务从服务列表将其剔除(Eviction)
- Get Registry:EurekaClient默认每30秒从EurekaServer获取服务注册列表,并且会与自身本地已经缓存过的服务列表进行比较合并,有点像本地仓库从git仓库进行git pull
- Cancel:EurekaClient服务的下线
- Make Remote Call:EurekaClient服务间进行远程调用,比如通过RestTemplate+Ribbon或Fegin
- us-east-1c:美国东海岸EurekaServer
- Replicate:EurekaServer集群节点之间数据(主要是服务注册列表信息)同步
Eureka源码
1. 是纯正的 servlet 应用,需构建成war包部署
2. 使用了 Jersey 框架(如注解@POST、@Consumers)实现自身的 RESTful HTTP接口
3. peer之间的同步与服务的注册全部通过 HTTP 协议实现
4. 定时任务(发送心跳续约、定时清理过期服务Eviction、节点同步等)通过 JDK 自带的 Timer 实现
5. 内存缓存使用Google的guava包实现
EurekaServer初始化
由于是Servlet应用,所以Eureka需要通过servlet的相关监听器 ServletContextListener 嵌入到 Servlet 的生命周期中。EurekaBootStrap 类实现了该接口,在servlet标准的contextInitialized()方法中完成了EurekaServer初始化工作:
/**
* Initializes Eureka, including syncing up with other Eureka peers and publishing the registry.
*
* @see
* javax.servlet.ServletContextListener#contextInitialized(javax.servlet.ServletContextEvent)
*/
@Override
public void contextInitialized(ServletContextEvent event) {
try {
initEurekaEnvironment();
initEurekaServerContext(); ServletContext sc = event.getServletContext();
sc.setAttribute(EurekaServerContext.class.getName(), serverContext);
} catch (Throwable e) {
logger.error("Cannot bootstrap eureka server :", e);
throw new RuntimeException("Cannot bootstrap eureka server :", e);
}
}
EurekaBootStrap实现了ServletContextListener接口,重写了contextInitialized方法;
initEurekaEnvironment主要做的是读取配置信息,设置eureka的数据中心datacenter和环境environment;
initEurekaServerContext主要是初始化servlet代码如下:
protected void initEurekaServerContext() throws Exception {
...//省略代码
PeerAwareInstanceRegistry registry;
if (isAws(applicationInfoManager.getInfo())) {
...//省略代码,如果是AWS的代码
} else {
registry = new PeerAwareInstanceRegistryImpl(
eurekaServerConfig,
eurekaClient.getEurekaClientConfig(),
serverCodecs,
eurekaClient
);
}
PeerEurekaNodes peerEurekaNodes = getPeerEurekaNodes(
registry,
eurekaServerConfig,
eurekaClient.getEurekaClientConfig(),
serverCodecs,
applicationInfoManager
);
}
与Spring Cloud结合的胶水代码
Eureka是一个纯正的Servlet应用,而Spring Boot使用的是嵌入式Tomcat, 因此就需要一定的胶水代码让Eureka跑在Embedded Tomcat中。
这部分工作是在 EurekaServerBootstrap 中完成的。
与上面提到的EurekaBootStrap相比,它的代码几乎是直接将原生代码copy过来的,虽然它并没有继承 ServletContextListener, 但是相应的生命周期方法都还在,然后添加了@Configuration注解使之能被Spring容器感知:
原生的 EurekaBootStrap 类实现了标准的ServletContextListener接口,Spring Cloud的EurekaServerBootstrap类没有实现servlet接口,但是保留了接口方法的完整实现。
在类EurekaServerInitializerConfiguration中实现了 ServletContextAware(拿到了tomcat的ServletContext对象)、SmartLifecycle(Spring容器初始化该bean时会调用相应生命周期方法):
@Configuration
@CommonsLog
public class EurekaServerInitializerConfiguration
implements ServletContextAware, SmartLifecycle, Ordered {
}
在 start() 方法中:
eurekaServerBootstrap.contextInitialized(EurekaServerInitializerConfiguration.this.servletContext);
在SpringCloud中,Spring容器初始化该组件时,Spring调用其生命周期方法start()从而触发了Eureka的启动:
@Override
public void start() {
new Thread(new Runnable() {
@Override
public void run() {
try {
eurekaServerBootstrap.contextInitialized(EurekaServerInitializerConfiguration.this.servletContext); // 调用 servlet 接口方法手工触发启动
log.info("Started Eureka Server"); // ... ...
}
catch (Exception ex) {
// Help!
log.error("Could not initialize Eureka servlet context", ex);
}
}
}).start();
}
重要的代码入口
1. com.netflix.appinfo.InstanceInfo类封装了服务注册所需的全部信息
2. Eureka Client探测本机IP是通过org.springframework.cloud.commons.util.InetUtils工具类实现的
3. com.netflix.eureka.resources.ApplicationResource类相当于Spring MVC中的控制器,是服务的注册、查询功能的代码入口点
一个服务启动后最长可能需要2分钟时间才能被其它服务感知到
当一个服务A启动后,首先需要注册到某个EurekaServer集群节点上,已经注册到EurekaServer上的服务B此时想要Make Remote Call服务A,最长可能要等两分钟,这是因为三处缓存和一处延迟:
1. Eureka Client对已经获取到的本地的注册信息也做了30s缓存。
即服务通过eureka客户端第一次查询服务注册信息会请求EurekaServer,然后会将请求返回的结果缓存,下次再调用时就不会真正向Eureka发起HTTP请求了,直接查询本地的服务注册信息
2. 负载均衡组件Ribbon也有30s缓存
Ribbon会从Eureka Client本地获取服务列表,然后将结果缓存30s
3. EurekaServer对HTTP响应做了缓存。在EurekaServer的”控制器”类 ApplicationResource的109行可以看到有一行
String payLoad = responseCache.get(cacheKey);
的调用,该代码所在的getApplication()方法的功能是响应客户端查询某个服务信息的HTTP请求:
String payLoad = responseCache.get(cacheKey); // 从cache中拿响应数据
if (payLoad != null) {
logger.debug("Found: {}", appName);
return Response.ok(payLoad).build();
} else {
logger.debug("Not Found: {}", appName);
return Response.status(Status.NOT_FOUND).build();
}
responseCache引用的是ResponseCache类型,该类型是一个接口,其get()方法首先会去缓存中查询数据,如果没有则生成数据返回(即真正去查询注册列表),且缓存的有效时间为30s。
也就是说,客户端拿到Eureka的响应并不一定是即时的,大部分时候只是缓存信息。
4. 如果你并不是在Spring Cloud环境下使用这些组件(Eureka, Ribbon),你的服务一启动(不是启动完成)并不会马上向Eureka注册,而是需要等到第一次发送心跳请求时才会注册
心跳请求的发送间隔也是30s。(Spring Cloud对此做了修改,服务启动后会马上注册)
Eureka保护机制
https://www.cnblogs.com/theRhyme/p/10058988.html
作为注册中心,Eureka比Zookeeper好在哪里
Zookeeper保证CP
注册中心需求分析及关键设计考量: https://www.cnblogs.com/theRhyme/p/10130714.html
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接受服务直接down掉不可用。
也就是说,服务注册功能对可用性的要求要高于一致性。
但是zk会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
在云部署的环境下,因网络问题使得zk集群失去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
Eureka保证AP
Eureka优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。
而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
除此之外,Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
1. Eureka不再从注册列表中移除因为长时间没收到心跳而应该过期的服务
2. Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
3. 当网络稳定时,当前实例新的注册信息会被同步到其它节点中
因此, Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
就算Eureka节点一个都不可用,还有缓存的服务列表,如EurekaClient本地的服务列表。
Service Health Check
使用 ZooKeeper 作为服务注册中心时,服务的健康检测常利用 ZooKeeper 的 Session 活性 Track机制 以及结合 Ephemeral ZNode的机制,简单而言,就是将服务的健康监测绑定在了 ZooKeeper 对于 Session 的健康监测上,或者说绑定在TCP长链接活性探测上了。
这在很多时候也会造成致命的问题,ZK 与服务提供者机器之间的TCP长链接活性探测正常的时候,该服务就是健康的么?答案当然是否定的!注册中心应该提供更丰富的健康监测方案,服务的健康与否的逻辑应该开放给服务提供方自己定义,而不是一刀切搞成了 TCP 活性检测!
健康检测的一大基本设计原则就是尽可能真实的反馈服务本身的真实健康状态,否则一个不敢被服务调用者相信的健康状态判定结果还不如没有健康检测。
A服务是如何访问到B服务的?
首先A和B是注册到EurekaServer上的,每隔30秒会从Eureka注册中心拉取一次服务列表进行比对合并,注册时服务会将自己的元数据比如ip,port,服务名称注册到EurekaServer;
所以A访问B服务是通过服务列表提供的ip,port,服务名访问的。
这里是EurekaClient服务自身通过每隔30s从注册中心拉取服务列表;
而Dubbo的模式是消费者向注册中心订阅服务列表,如果订阅的服务列表变动,注册中心将基于长连接推送变更数据给消费者

参考来源:
https://blog.csdn.net/forezp/article/details/73017664
https://blog.csdn.net/neosmith/article/details/53131023
https://yq.aliyun.com/articles/601745?spm=a2c4e.11153940.blogcont604028.19.6daf2a38OLvUBo
EUREKA原理总结的更多相关文章
- Eureka原理剖析
Eureka作为微服务中的注册中心,为微服务集群间各个服务进行调用提供寻址的功能,有了它集群间的服务只需要指定服务名称就可以了,无需再去关心服务具体部署的服务器IP,即可正常调用.下面来对其中我们开发 ...
- 🔥🔥🔥Spring Cloud进阶篇之Eureka原理分析
前言 之前写了几篇Spring Cloud的小白教程,相信看过的朋友对Spring Cloud中的一些应用有了简单的了解,写小白篇的目的就是为初学者建立一个基本概念,让初学者在学习的道路上建立一定的基 ...
- Eureka原理与架构
一.原理图 Eureka:就是服务注册中心(可以是一个集群),对外暴露自己的地址 提供者:启动后向Eureka注册自己信息(地址,提供什么服务) 消费者:向Eureka订阅服务,Eureka会将对应服 ...
- Spring Cloud Eureka简介及原理
Eureka是Netflix开发的服务发现组件,本身是一个基于REST的服务.Spring Cloud将它集成在其子项目spring-cloud-netflix中,以实现Spring Cloud的服务 ...
- Eureka工作原理及心跳机制
Eureka原理 1.基本原理上图是来自eureka的官方架构图,这是基于集群配置的eureka:处于不同节点的eureka通过Replicate进行数据同步Application Service为服 ...
- 微服务之服务中心—Eureka
Eureka 简介Eureka 是 Spring Cloud Netflix 的一个子模块,也是核心模块之一,用于云端服务发现,是一个基于 REST 的服务,用于定位服务,以实现云端中间层服务发现和故 ...
- spring cloud 之 Eureka 知识点
Eureka原理 当服务消费者想要调用服务提供者的API时,首先会在注册中心中查询当前可用的实例的网络地址(也可能是定时查询可用实例,本地缓存好可用服务列表),然后再使用客户端负载均衡,命中到其中一个 ...
- 0401-服务注册与发现、Eureka简介
一.硬编码问题 解决方案:nginx.或.服务注册与发现 二.服务发现 注册.心跳机制 三.服务发现组件的功能 1.服务注册表:是一个记录当前可用服务实例的网络信息的数据库,是服务发现机制的核心.服务 ...
- SpringCloud-服务的注册与发现(Eureka)
SpringCloud 简介 SpringCloud为开发人员提供了快速构建分布式系统的一些工具,包括配置管理.服务发现.断路器.路由.微代理.事件总线.全局锁.决策竞选.分布式会话等等.它运行环境简 ...
随机推荐
- [十二省联考2019]异或粽子 (可持久化01tire 堆)
/* 查询异或最大值的方法是前缀和一下, 在01trie上二分 那么我们可以对于n个位置每个地方先求出最大的数, 然后把n个信息扔到堆里, 当我们拿出某个位置的信息时, 将他去除当前最大后最大的信息插 ...
- rsyncd
rsync是一个快速.通用的文件复制工具.支持两种工作模式:基于shell的传输.基于服务的传输.1.配置文件 rsyncd.conf文件由模块及其参数构成.模块由方括号包裹模块名称,直到下一个模块结 ...
- 安装nodejs
1.安装epel 是yum的一个软件源,里面包含了许多基本源里没有的软件. yum install epel-release (需要root用户) yum 是一个在Fedora和Red ...
- jq check 复选变单选。
$("input[type='checkbox']").on("click",function(e){ var $checked = $("input ...
- geiUItabBarItem设置图片颜色和title颜色
设置图片颜色 tabBarVCtrl.tabBar.selectedImageTintColor = [UIColor greenColor];//设置tabBarItem选中时的字图颜色,iOS 8 ...
- centos官网下载旧版本办法
https://blog.csdn.net/yu0_zhang0/article/details/78503439 在 /etc/yum.conf 的 [main] 后面添加以下配置即可! exclu ...
- 使用mondorescue将本机linux centos 7服务器制作成光盘
https://blog.csdn.net/wuxianfeng1987/article/details/78059618 没试 重新封装linux系统成iso文件 https://zhidao. ...
- 使用include重用布局
尽管Android 支持各种小部件,来提供小且可以重用的交互元素,你可能还需要更大的,要求一个专门布局的重用组件.为了高效的重用整个布局,你能使用和标签在当前的布局中嵌入别的布局. 重用布局功能特别强 ...
- 汉诺塔问题python
count = 0def hanoi(n,src,mid,dst): global count if n == 1: print("{}:{}->{}".format(1,s ...
- PHP 文件操作类(转载)
<?php class File { /** * 创建多级目录 * @param string $dir * @param int $mode * @return boolean */ publ ...