吴裕雄 python 机器学习-Logistic(1)
import numpy as np def loadDataSet():
dataMat = []
labelMat = []
fr = open('D:\\LearningResource\\machinelearninginaction\\Ch05\\testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat dataMat,labelMat = loadDataSet()
print(dataMat)
print(labelMat)

def sigmoid(z):
sigmoid = 1.0/(1+np.exp(-z))
return sigmoid def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m,n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose()* error
return weights weights = gradAscent(dataMat,labelMat)
print(weights)

def stocGradAscent0(dataMatrix, classLabels):
m,n = np.shape(dataMatrix)
alpha = 0.01
weights = np.ones(n)
for i in range(m):
h = sigmoid(sum(np.array(dataMatrix[i])*weights))
error = classLabels[i] - h
weights = weights + alpha * error * np.array(dataMatrix[i])
return weights weights = stocGradAscent0(dataMat,labelMat)
print(weights)
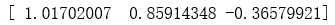
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = np.shape(dataMatrix)
weights = np.ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001
randIndex = int(np.random.uniform(0,len(dataIndex)))
h = sigmoid(sum(np.array(dataMatrix[randIndex])*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * np.array(dataMatrix[randIndex])
del(dataIndex[randIndex])
return weights weights = stocGradAscent1(dataMat,labelMat)
print(weights)
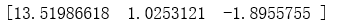
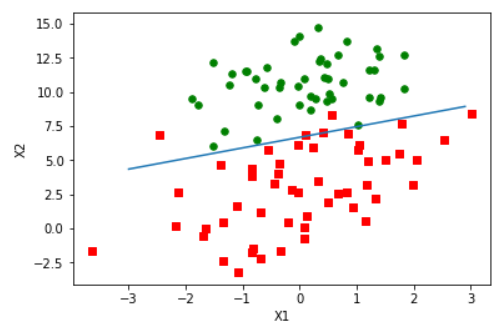
import matplotlib.pyplot as plt def plotBestFit():
dataMat,labelMat=loadDataSet()
weights = gradAscent(dataMat,labelMat)
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = []
for i in range(n):
if(int(labelMat[i])== 1):
xcord1.append(dataArr[i,1])
ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = np.arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
y = np.array(y).reshape(len(x))
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2');
plt.show() plotBestFit()
def classifyVector(z, weights):
prob = sigmoid(sum(z*weights))
if(prob > 0.5):
return 1.0
else:
return 0.0 def colicTest():
frTrain = open('D:\\LearningResource\\machinelearninginaction\\Ch05\\horseColicTraining.txt')
frTest = open('D:\\LearningResource\\machinelearninginaction\\Ch05\\horseColicTest.txt')
trainingSet = []
trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(np.array(trainingSet), trainingLabels, 1000)
errorCount = 0
numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if(int(classifyVector(np.array(lineArr), trainWeights))!= int(currLine[21])):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
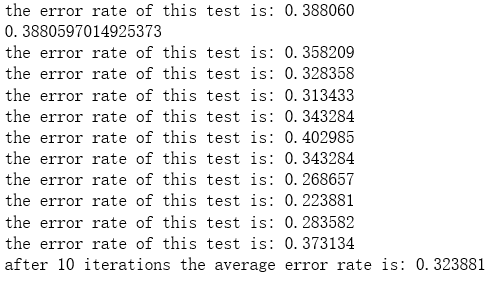
print("the error rate of this test is: %f" % errorRate)
return errorRate errorRate = colicTest()
print(errorRate) def multiTest():
numTests = 10
errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))) multiTest()
吴裕雄 python 机器学习-Logistic(1)的更多相关文章
- 吴裕雄 python 机器学习——人工神经网络感知机学习算法的应用
import numpy as np from matplotlib import pyplot as plt from sklearn import neighbors, datasets from ...
- 吴裕雄 python 机器学习——分类决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- 吴裕雄 python 机器学习——线性判断分析LinearDiscriminantAnalysis
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——Lasso回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——岭回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——线性回归模型
import numpy as np from sklearn import datasets,linear_model from sklearn.model_selection import tra ...
随机推荐
- Ambari集群的搭建(离线安装)
我们先克隆几台机器 我们打开克隆出来的机器 我们先把主机名修改一下 我们把主机名改成am2 下一步我们来配置网卡 把原来的eth0的注释掉,把现在的eth1改成eth0,同时把mac地址记下来 保存退 ...
- tp5 计算两个日期之间相差的天数
//两个日期之间相差的天数 function diffBetweenTwoDays ($day1, $day2) { $second1 = strtotime($day1); $second2 = s ...
- 使用nginx secure_link指令实现下载防盗链
一.安装nginx并检查是否已安装模块 [root@img_server ~]# nginx -V #输出nginx所有已安装模块,检查是否有ngx_http_secure_link_module 二 ...
- Django中的中间件(middleware)
中间件: 在研究中间件的时候我们首先要知道 1 什么是中间件? 官方的说法:中间件是一个用来处理Django的请求和响应的框架级别的钩子.它是一个轻量.低级别的插件系统,用于在全局范围内改变Djang ...
- underscore函数存在两种用法
var _ = require('underscore'); var a = {"a": 1, "b": 2}; console.log(_(a).size() ...
- CSS3帧动画
在前面的文章中也有介绍过css3动画的内容,可见<关于transition和animation>和<webkitAnimationEnd动画事件>,今天又要唠叨一下这个东西了, ...
- [UGUI]Text文字效果
参考链接: http://www.xuanyusong.com/archives/3471 https://www.cnblogs.com/lyh916/p/9162463.html https:// ...
- iar stm32 启动代码片段分析
今天查看了 iar 上面的启动文件,好奇堆栈指针到底是什么时候赋值的,所以就仔细的阅读了代码和相关手册,找到了答案. 首先,芯片启动后,会从ROM的首地址处进行执行,那么我们从 linker 里面找找 ...
- EA Data Modeling 显示别名设置
1.设置 2.效果
- NodeJS + React + Webpack + Echarts
最近画了个简单的前端图,使用百度的echarts,基于原来项目的NodeJS+React+Webpack框架.在此记录一下: 1. 在react里封装echarts组件,并调用后端API. (参考的 ...