Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Split(切片)
1>.MapReduce处理的单位(切片)
想必你在看MapReduce的源码的时候,是不是也在源码中看到了一行注释“//Create the splits for the job”(下图是我跟源码的部分截图),这个切片是MapReduce的最重要的概念,没有之一!因为MapReduce处理的单位就是切片。
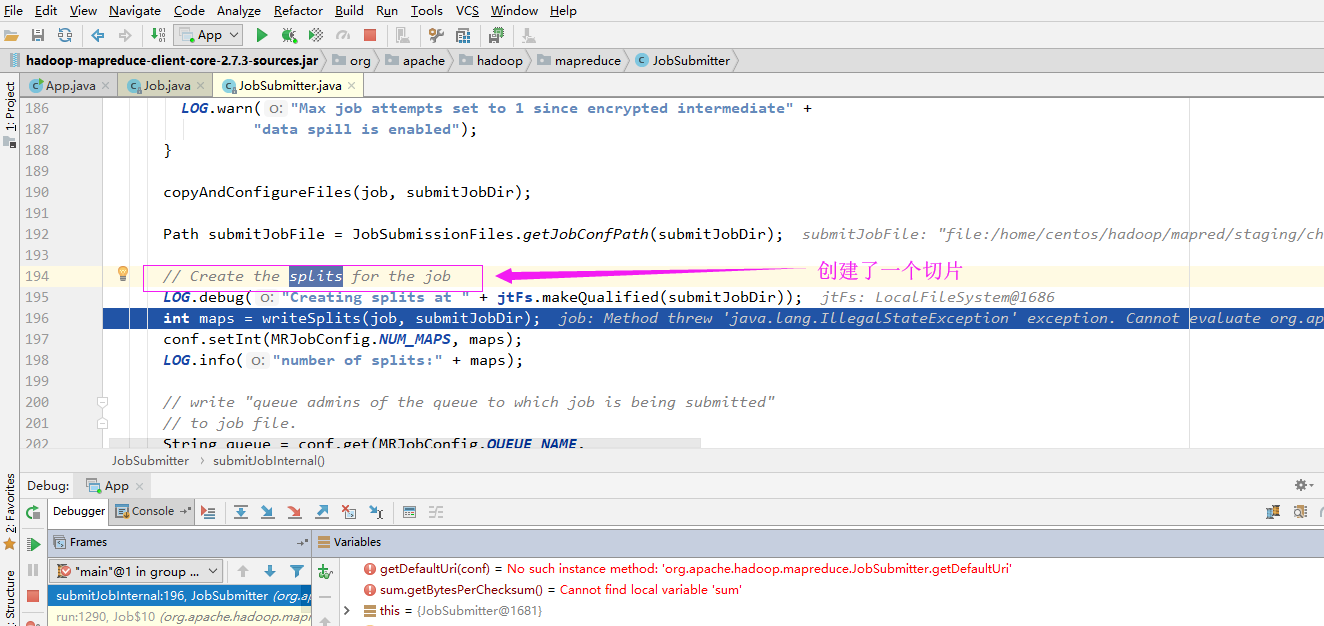
2>.逻辑切割
还记得hdfs存储的默认单位是什么吗?没错,默认版本是块(2.x版本的默认大小是128M),在MapReduce中默认处理的单位就是Split。其实切片本质上来说仍然是块,只不过和hdfs中的块是有所不同的。我们知道hdfs在存储一个大于1G的文件,会将文件按照hdfs默认的大小进行物理切割(将一个文件强行拆开,所有文件都是支持物理切割的!),放在不同的DataNode服务器上,而咱们的MapReduce的Split只是逻辑切割。
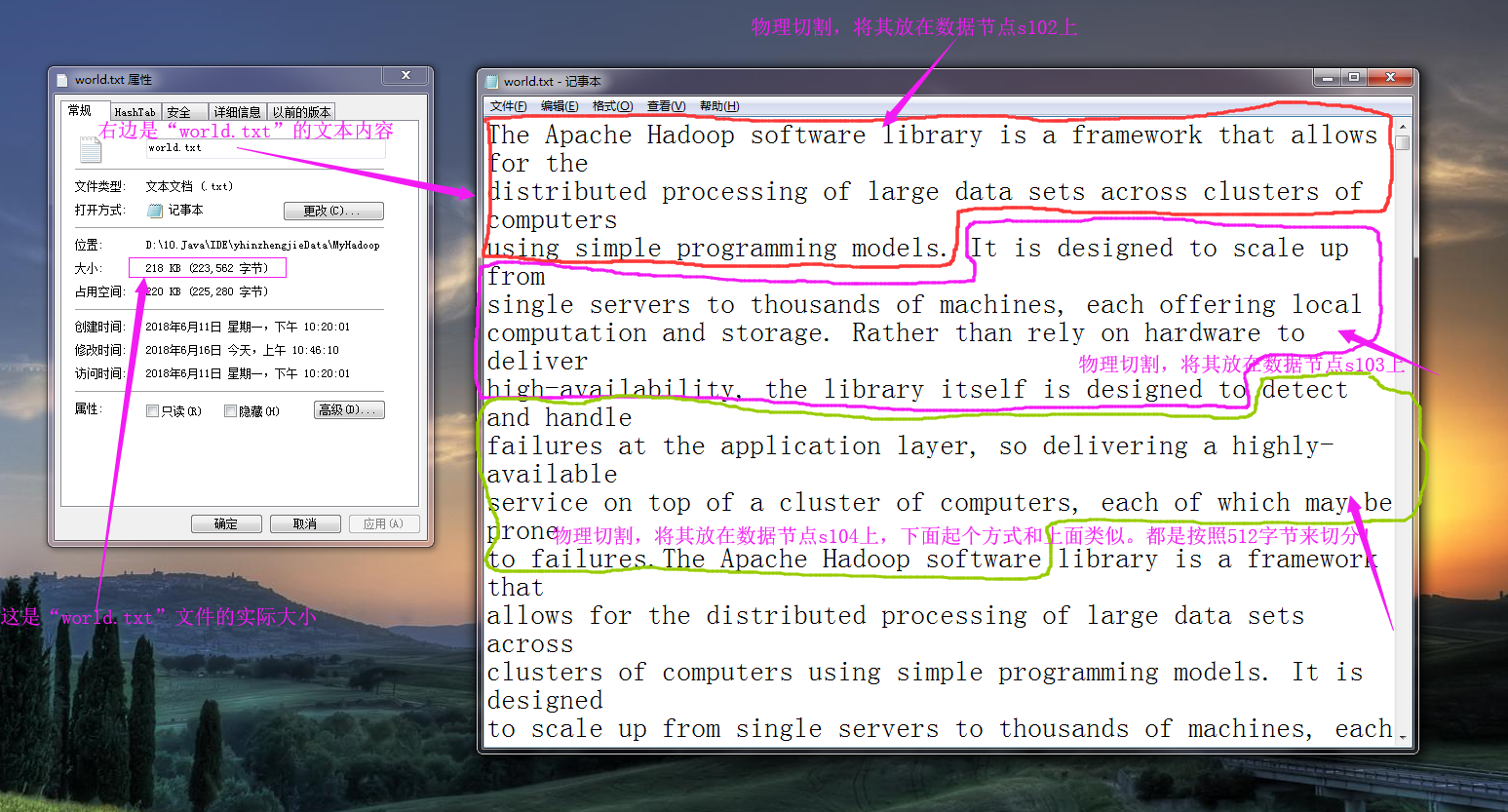
所谓的逻辑切割会判断切割处是否是行分隔符,换句话说,逻辑切割在切割文件的时候并不能像物理切割那样按照指定大小切割,而是按照程序员指定的规则进行切割(Split)。我们来举个例子,还记得我们之前写的一个单词统计的程序吗(https://www.cnblogs.com/yinzhengjie/p/9153256.html)?为了实验方便,我们可以把hdfs默认的128M改为512字节,那么我们在存储“world.txt”文件时,其物理切割大致用下图表示为:
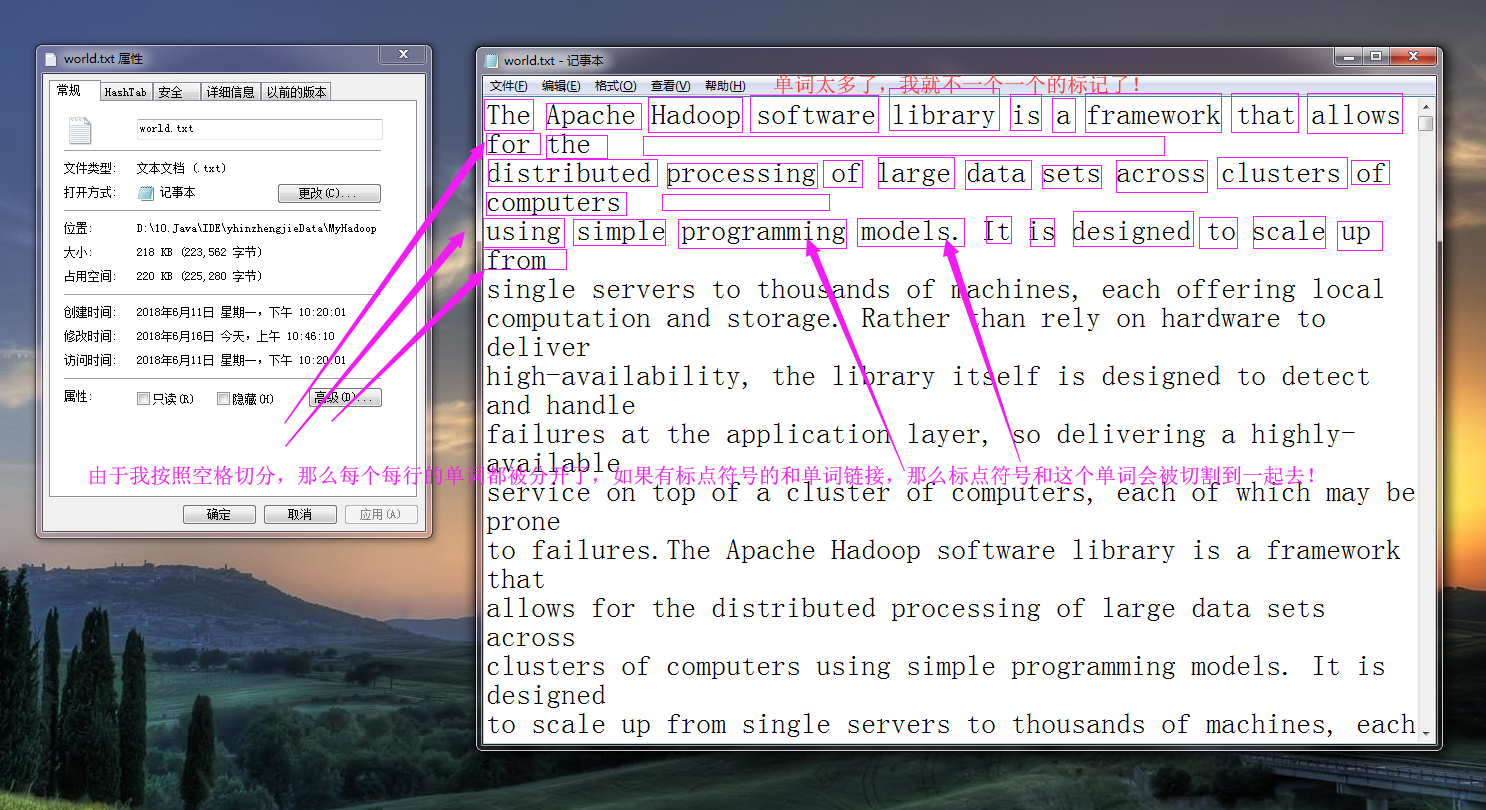
而所谓的逻辑切割是程序员指定规则进行切割的,比如我们将“word.txt”按照空格进行切分,大致逻辑如下图所示:(逻辑切割很灵活的,它可以是按空格切割,也可以按行切割,还可以按照“\t”切割,在SequenceFile的话就直接是key和value的形式取值了,相对来说更正规,推荐使用这类的文件格式,我这里为了演示方便,就直接用文本类型格式进行切割操作。)
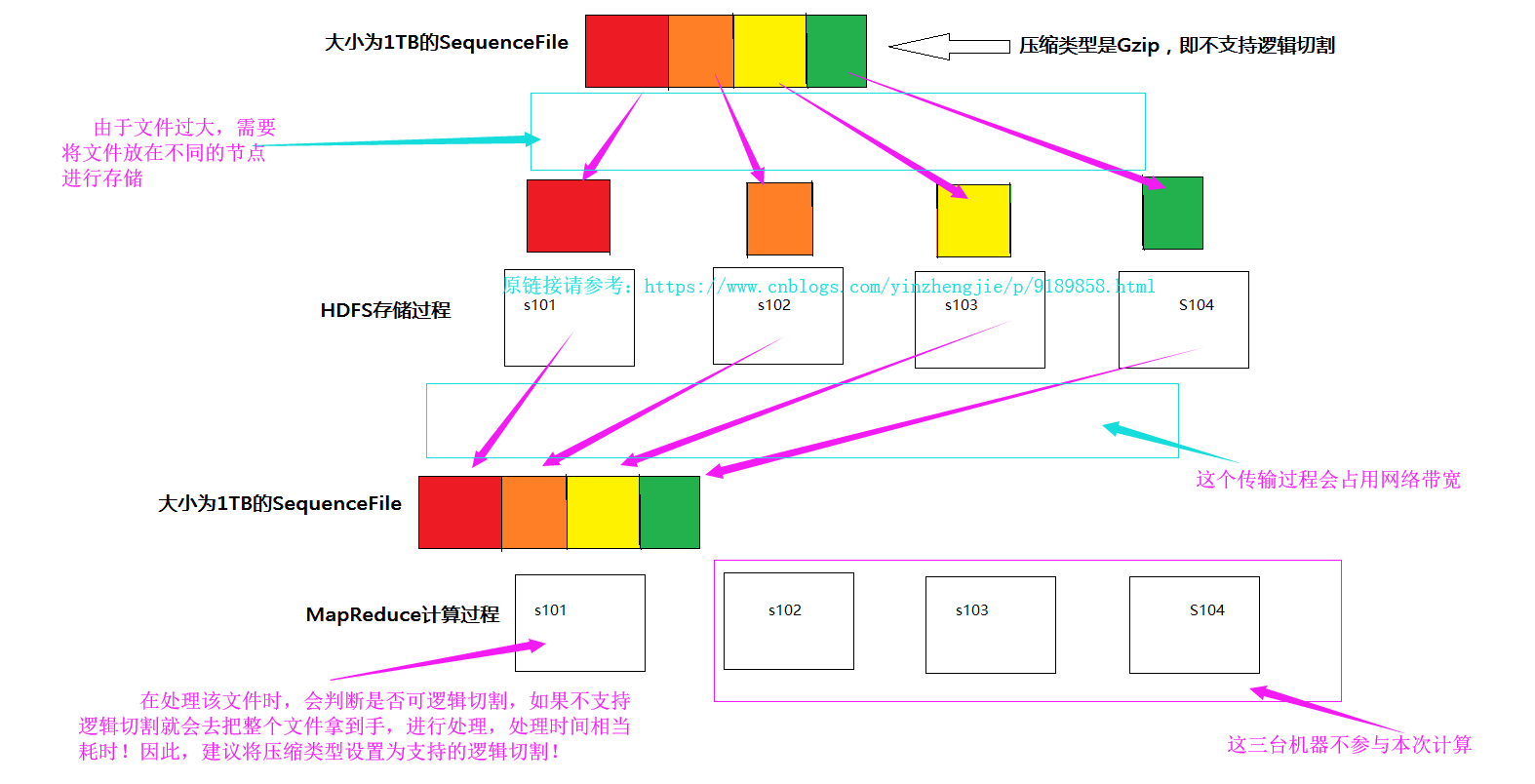
文本文件默认都是可以切割的(如上图所示),由于我们处理的是大数据,处理的数据可能不止是文本,还有视频,图片等等,比如淘宝公司的举行的双十一活动,一天光记录用户访问量就得需要“1PB”的数据量,如果这个时候我们还用文本文件去存储的话就不太合适了,实际上hadoop提供了一种SequenceFile容器文件,它不仅仅可以按照特定的格式存储文本信息,还支持Deflate,Gzip,Bzip2,Lz4,Snappy等压缩算法,其中Bzip2是极致压缩比例,而Lz4,Lzo和Snappy则是优化压缩速度,在生产环境下根据算法相关特性进行技术选型(当然除了hadoop序列化,还有Avro,Protocol Buffers等序列化技术都是可以供你选择的)。
这些算法都是支持物理切割的,注意:Lzo(with index)和Bzip2是可逻辑切割的算法,适合在MR中使用。如果你的SequenceFile不是使用Lzo或是BZip进行压缩的,那就麻烦了,因为他们不支持逻辑切割,就会出现以下的情况。
3>.计算切片数量
从源代码中可以看出,有一个变量为"MinSize",其值为“1”

从源代码中可以看出,有一个变量为"MaxSize",其值为“long.Max_Value”
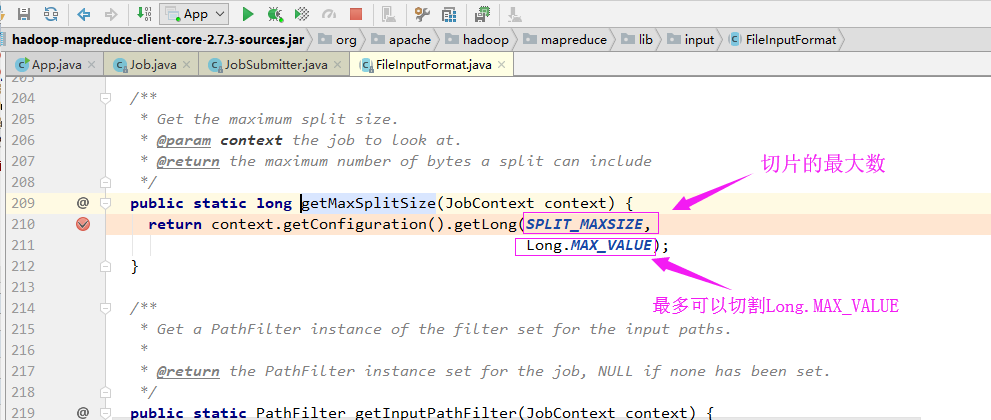
实际切片大小从代码调试的大小(长度)如下:
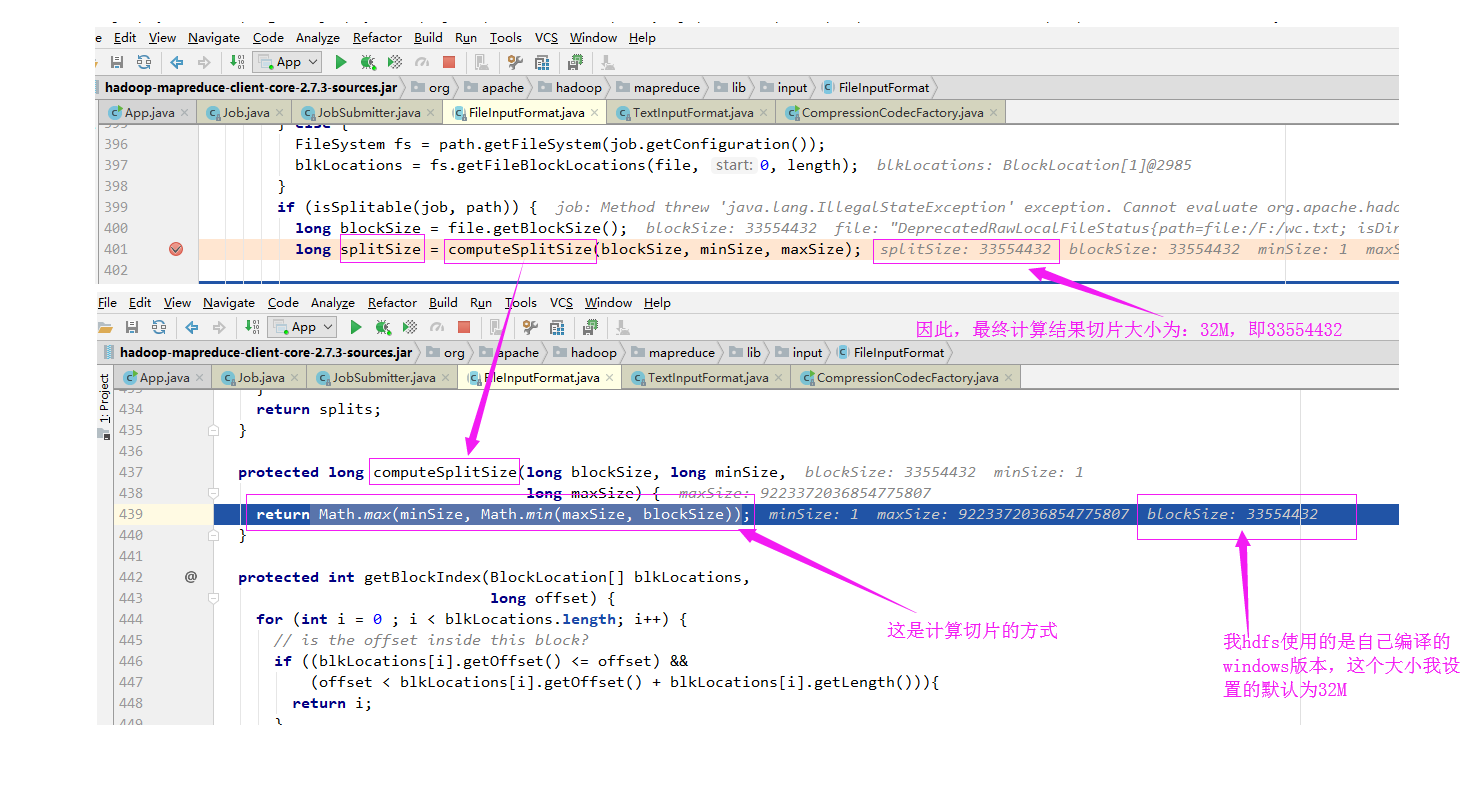
确认切片的偏移量:

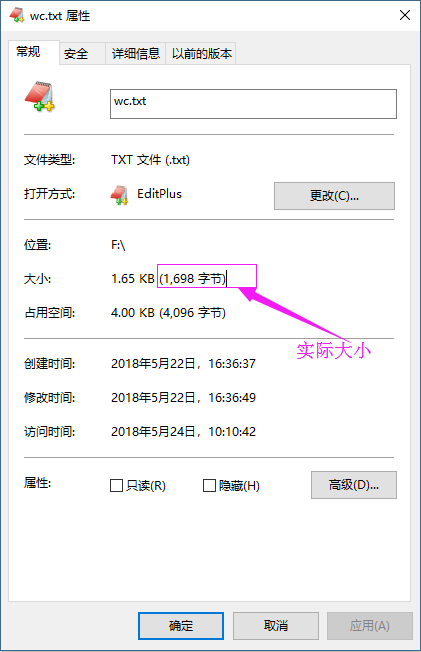
偏移量“0+1698”指的是文件的偏移量,如果文件较大,可能会被切割成多个切片进行处理,由于我测试的文件比较小,因此就被MapReduce切割成一个了,这个1698其实是文件的实际大小,如下:
4>.创建切片列表
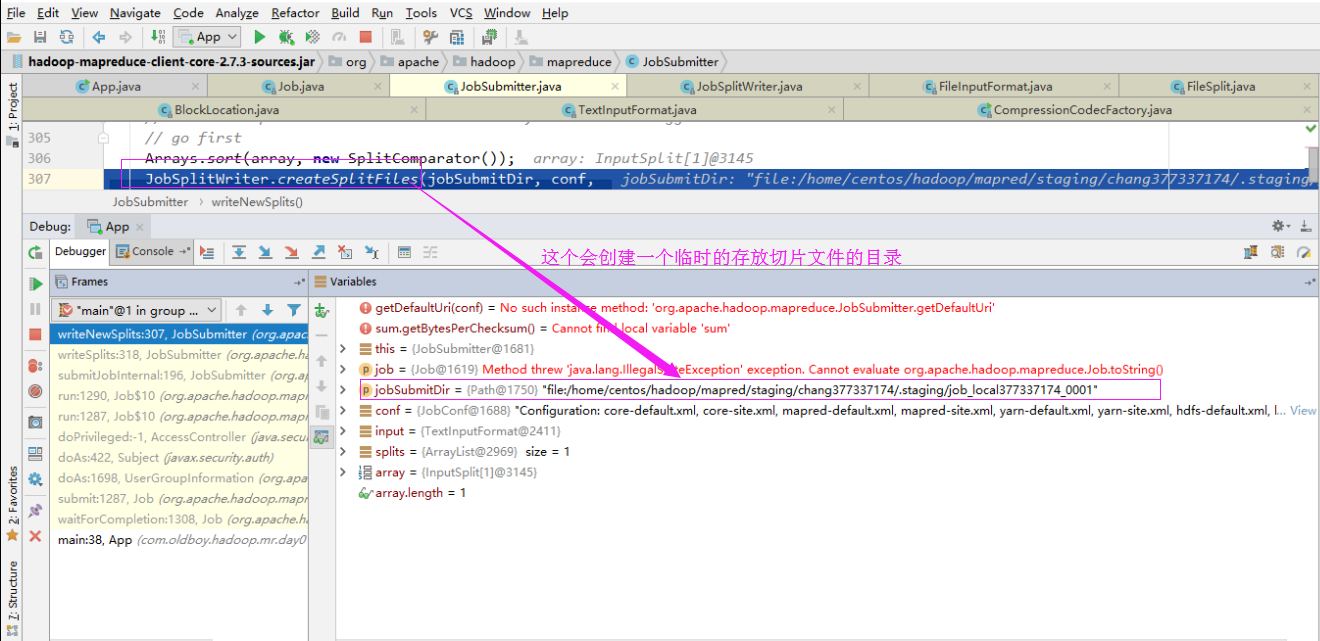
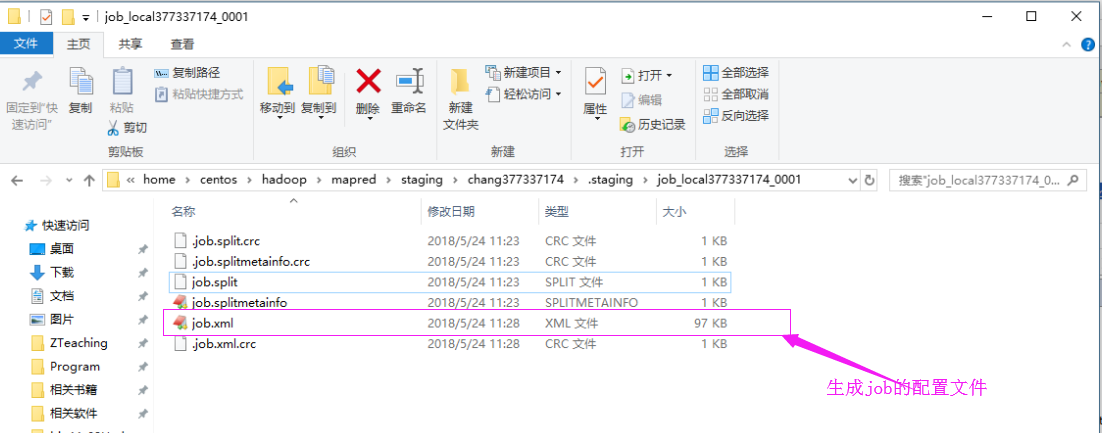
我们可以去这个切片目录中看看,如下:

5>..编写作业
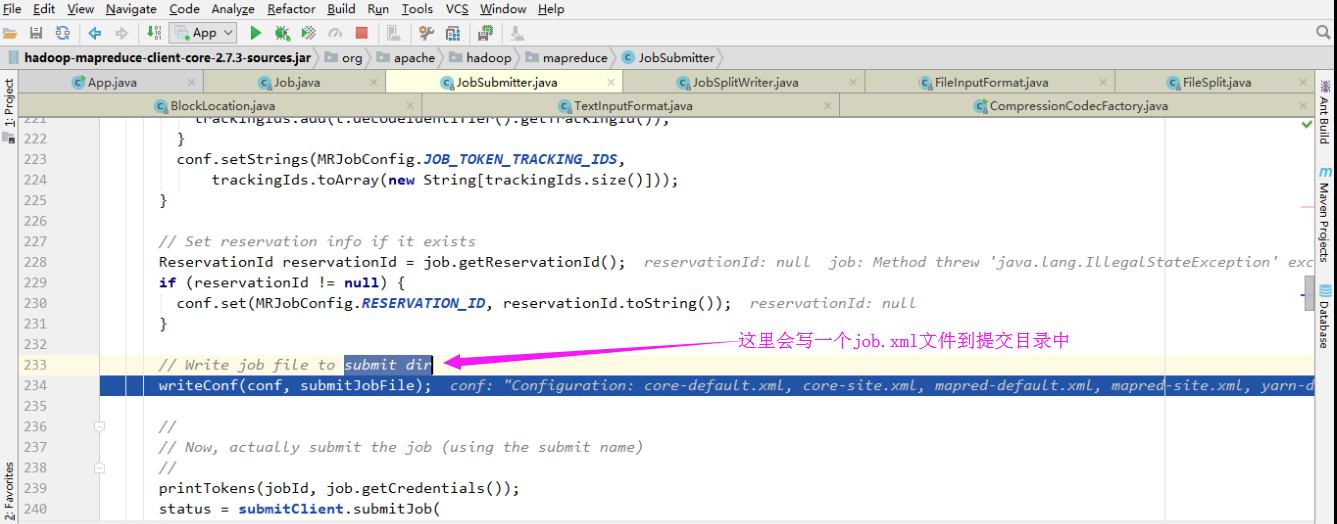
这个job文件和切片存放在同一个目录中:
5>.提交作业

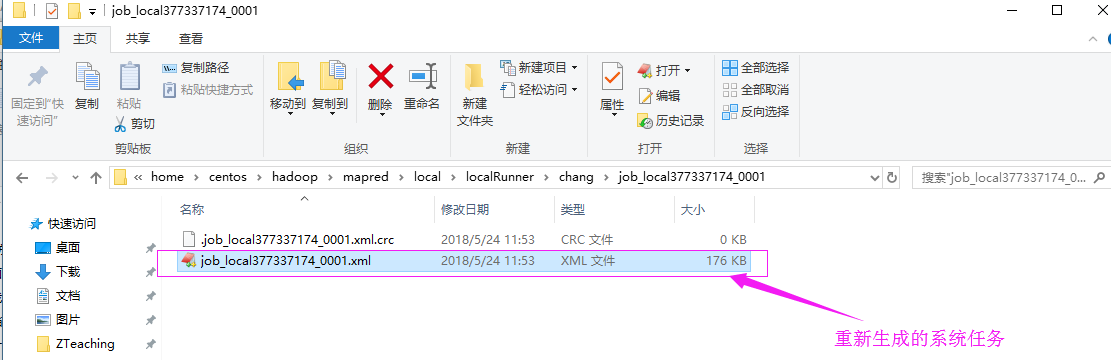
6>.创建当前job(比之前的job.xml更加详细的任务)
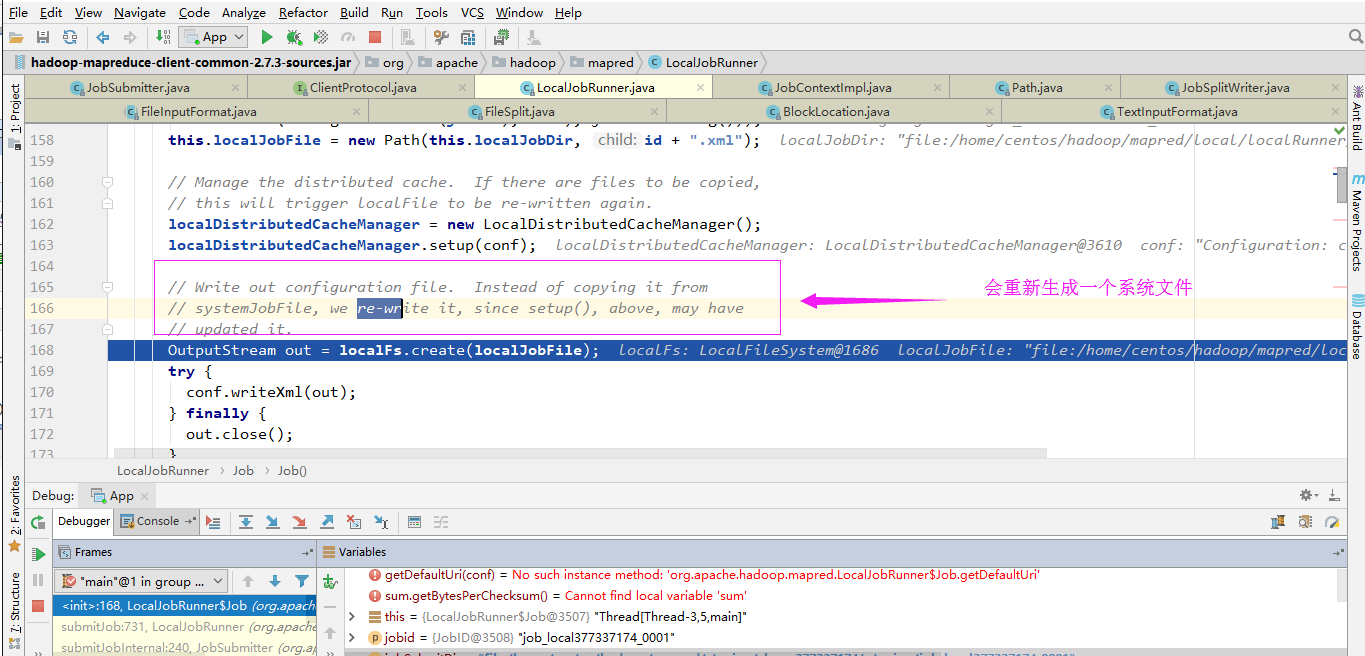
具体存放路径如下:
7>.启动线程
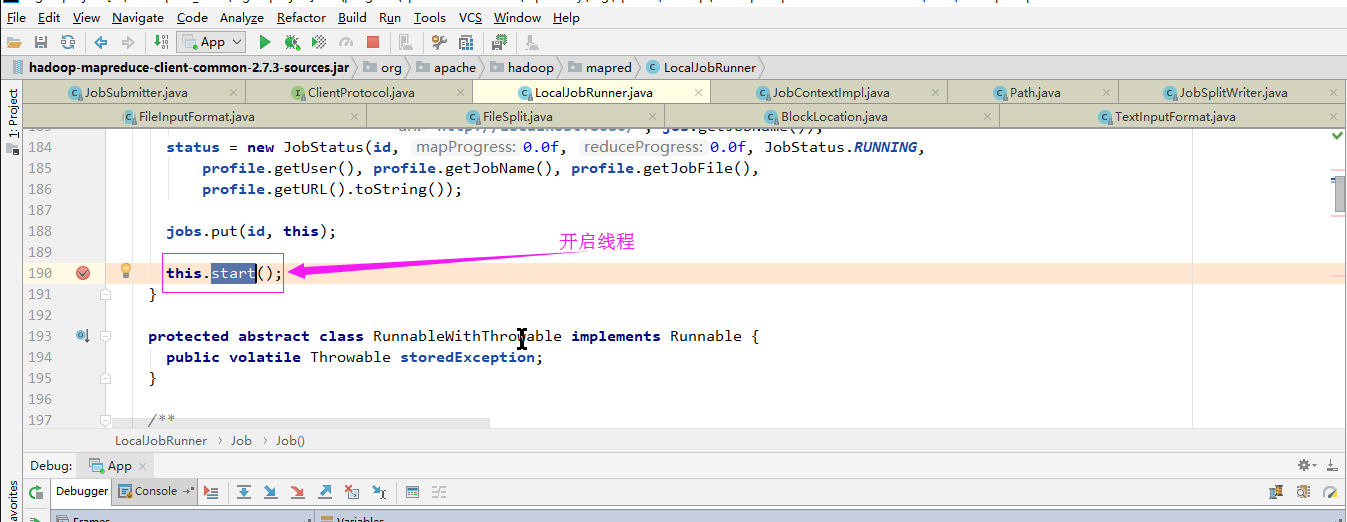
开启线程后会调用run方法:
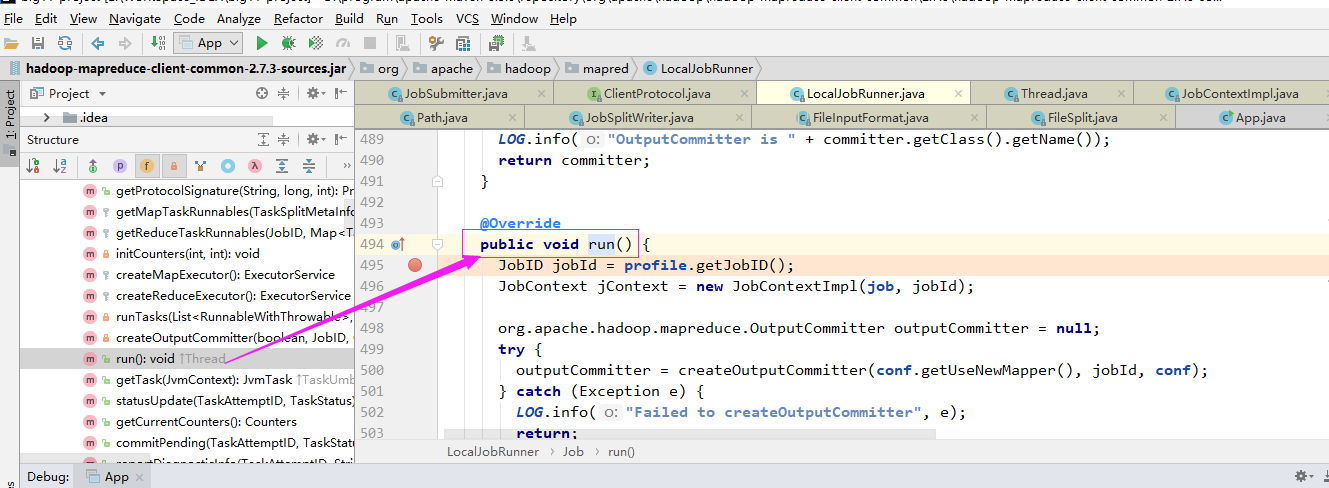
二.Mapper
1>.运行任务
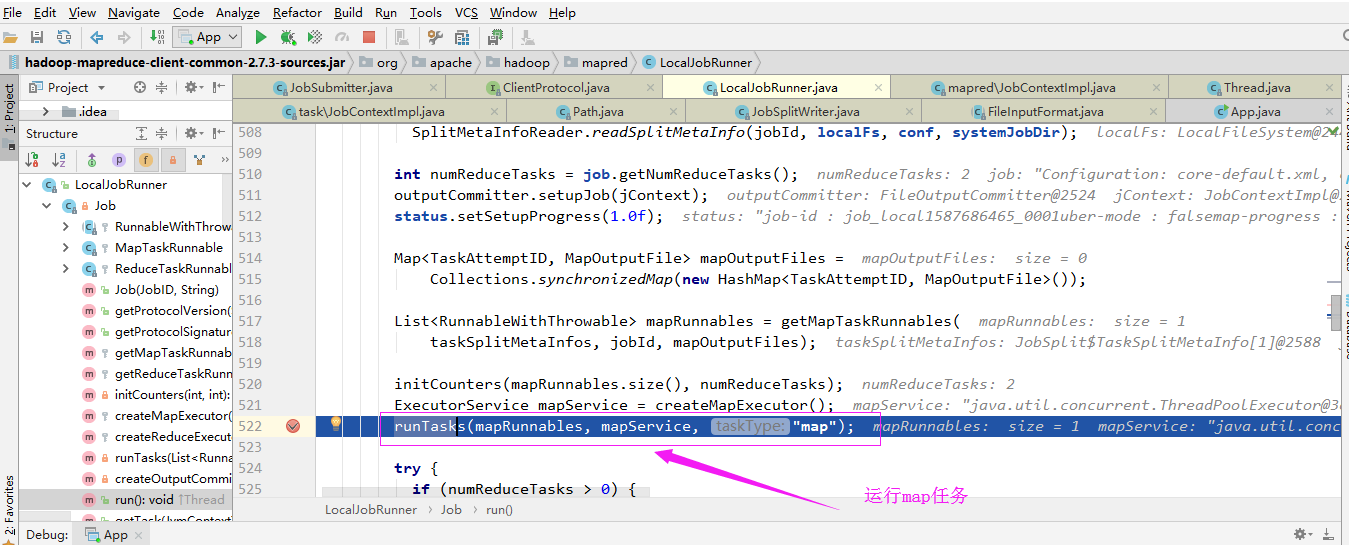
通过“LocalJobRunner$Job$MapTaskRunnable”内部类运行任务:
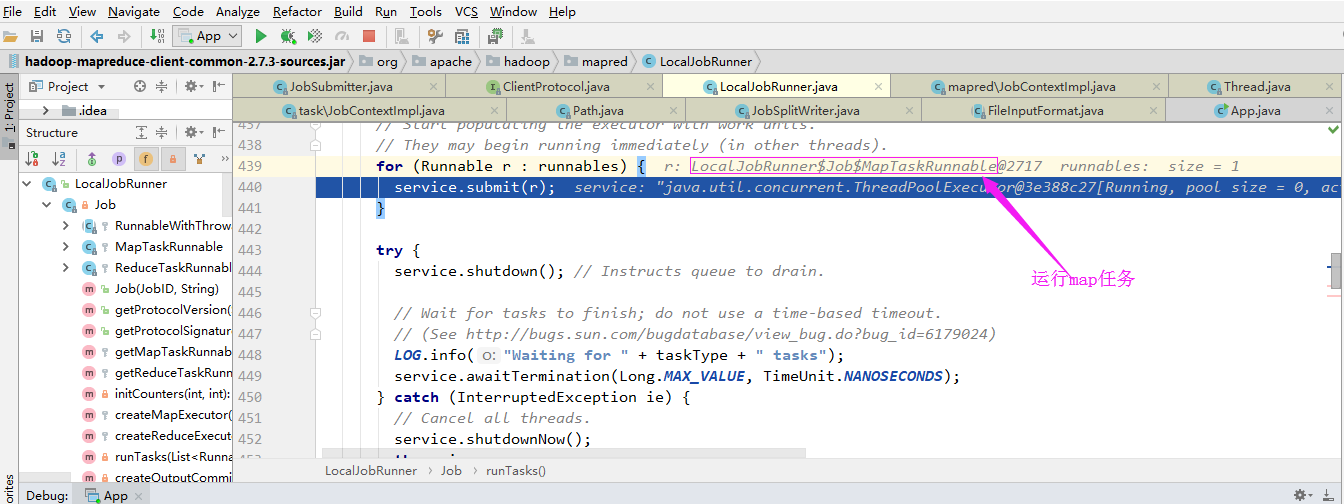
进入maper任务:
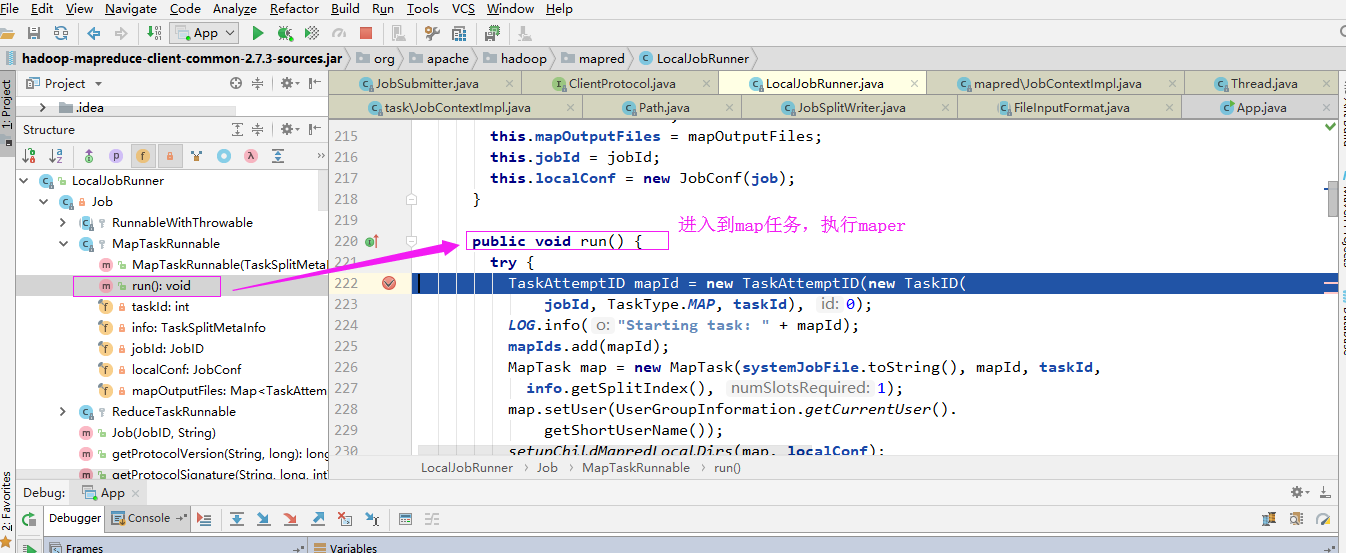
2>.通过反射得到map对象(Map程序是用户在通过“job.setMapperClass”方法设置的)
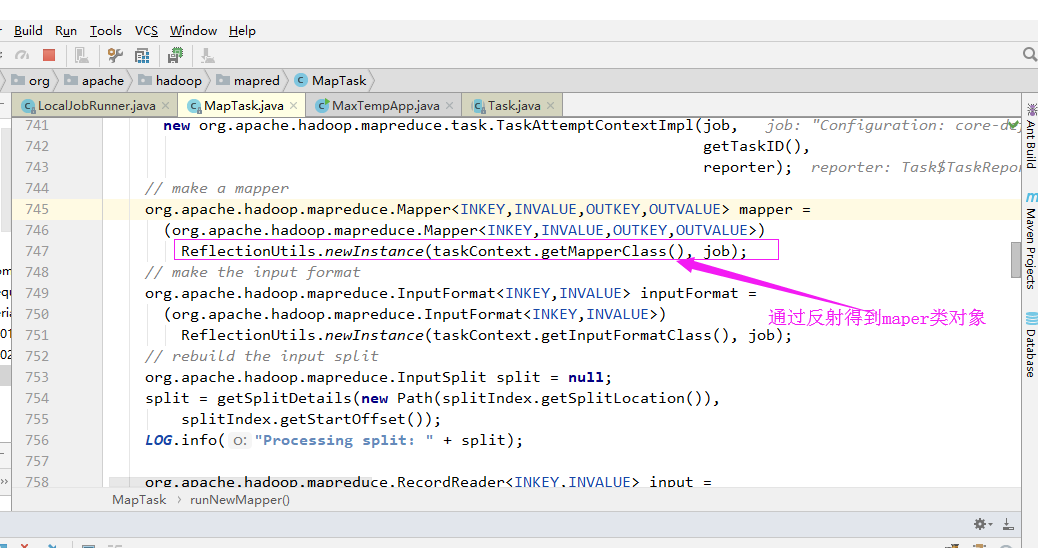
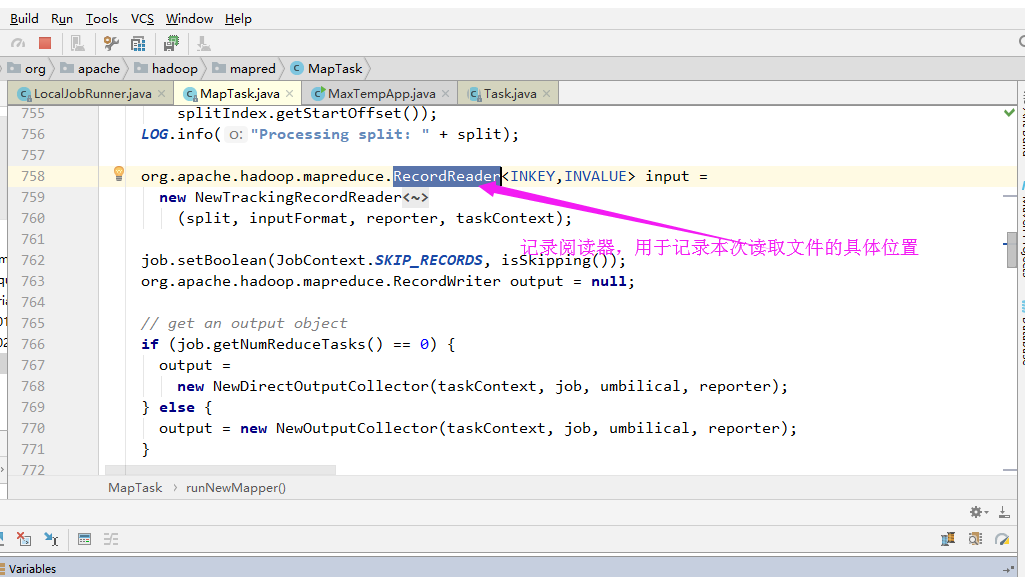
3>.记录阅读器
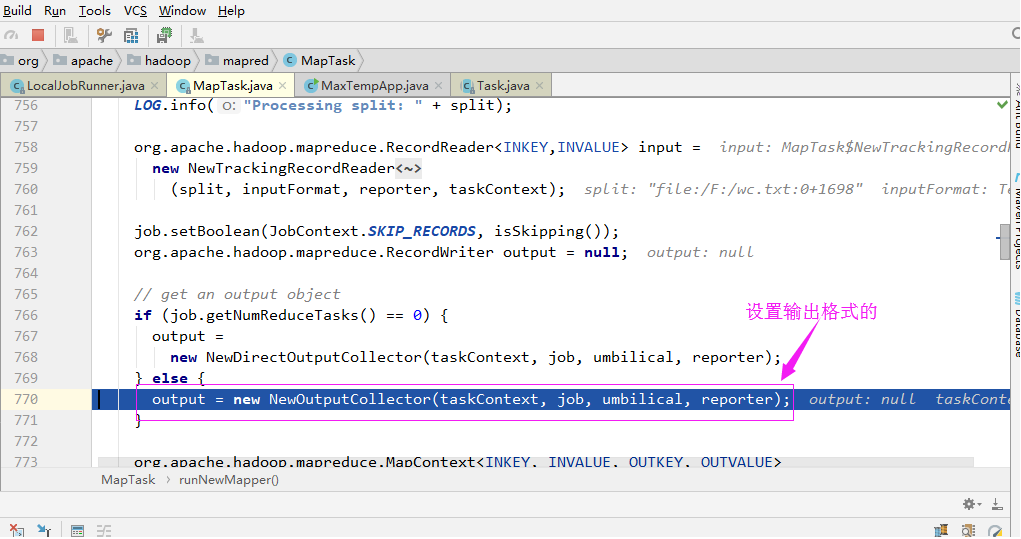
3>.设置输出格式
4>.Maper的回调机制
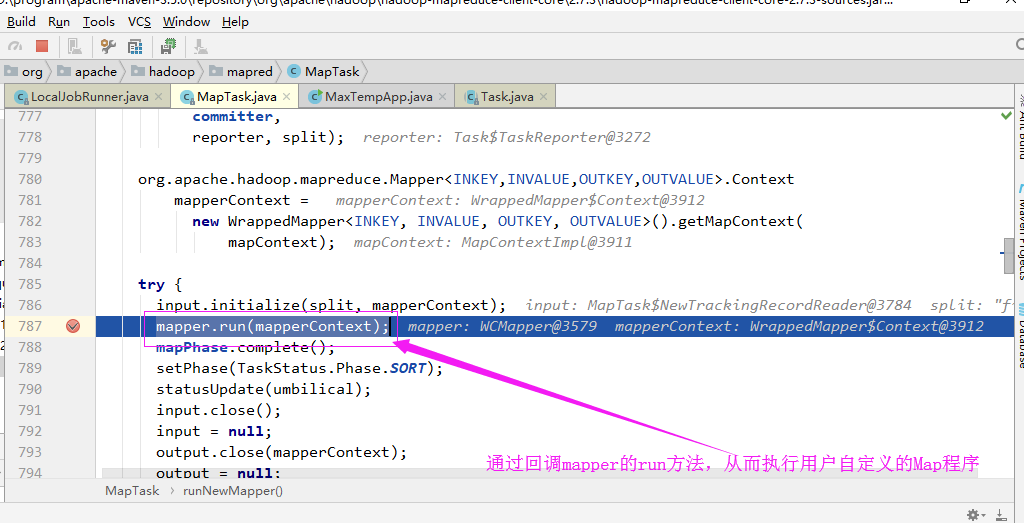
回调函数其实调用的mapper的run方法:
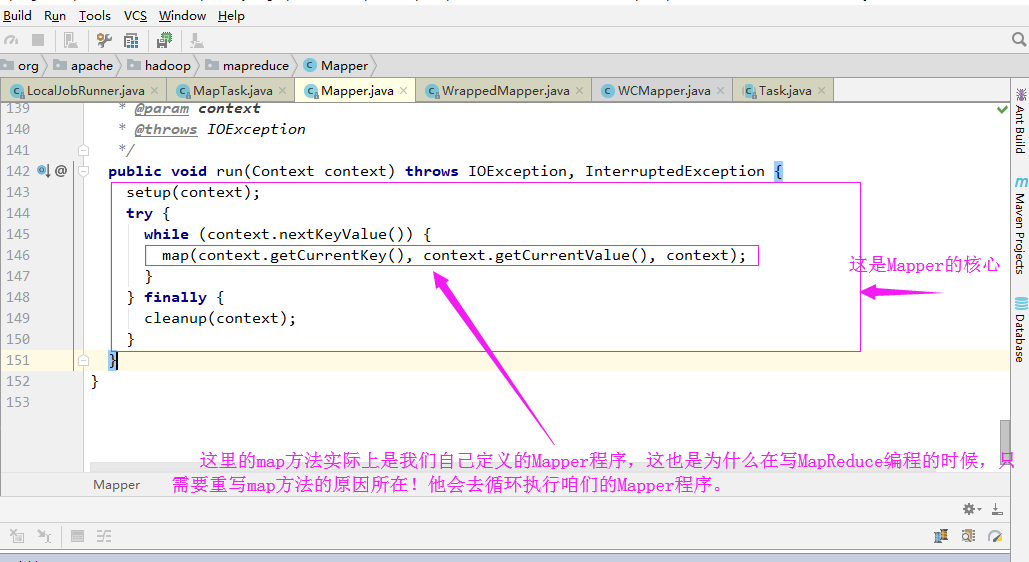
5>.排序阶段
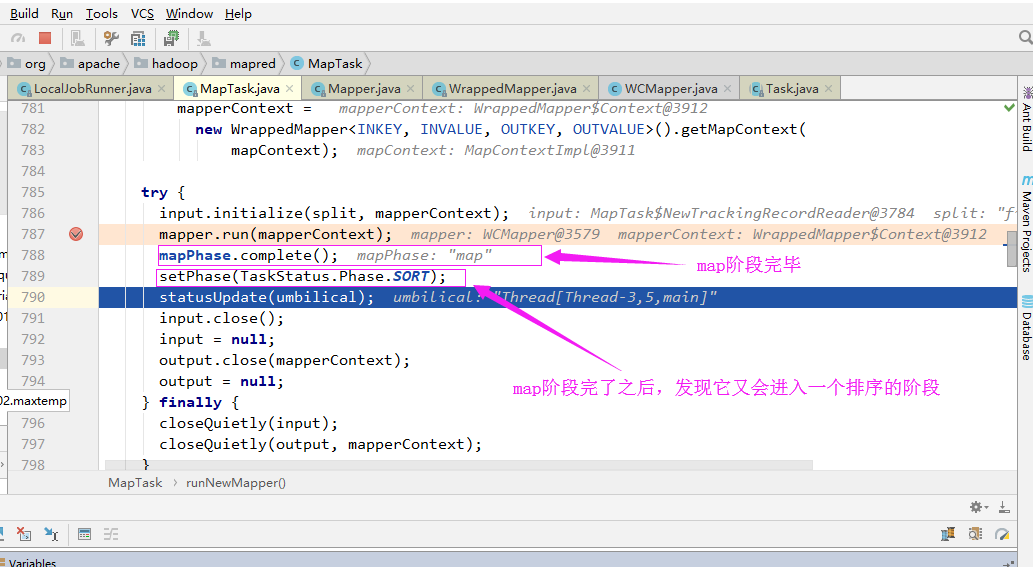
6>.Maper阶段执行结束
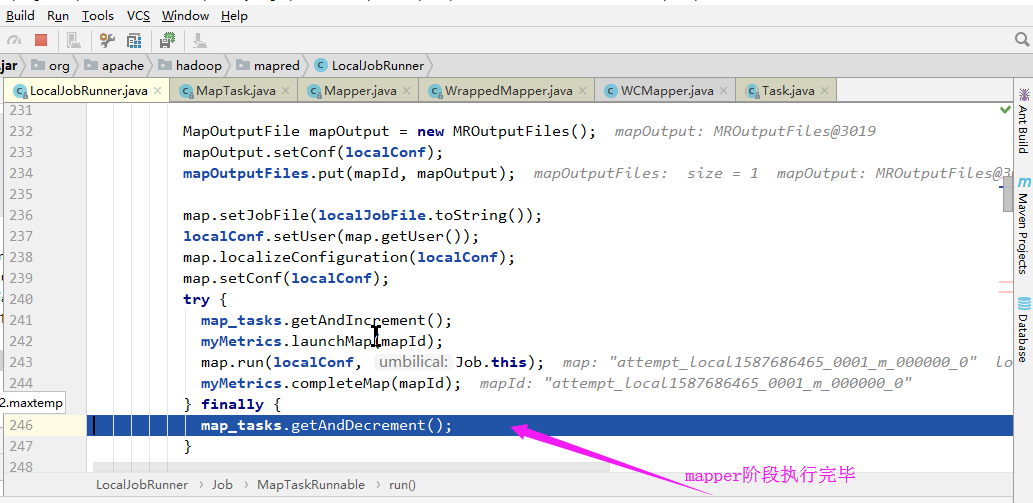
三.Reduce
Mapper阶段执行完毕之后,经过shuffle和sort等操作最终会进入到Reduce阶段,而Reduce阶段的实现过程和Mapper类似,它会首先启动一个”LocalJobRunner$Job$ReduceTaskRunnable“的线程,这里就不带截图了。继续打断点调试即可。此部分略过。
四.InputFormat
1>.TextInputFormat

2>.LzoTextInputFormat
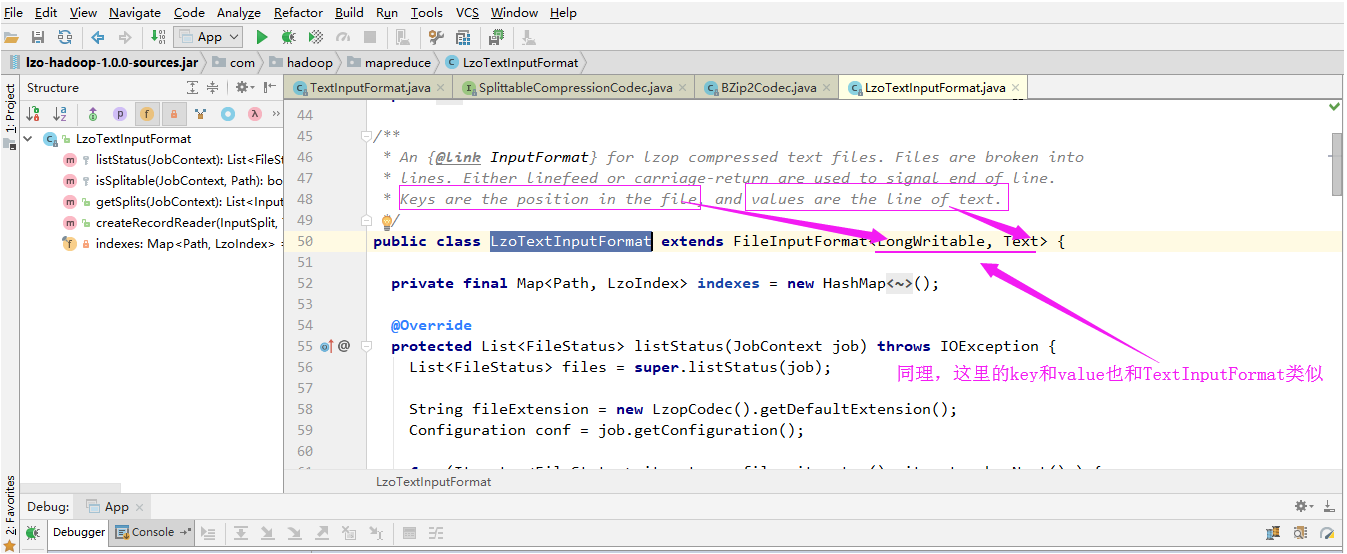
3>.读行的类
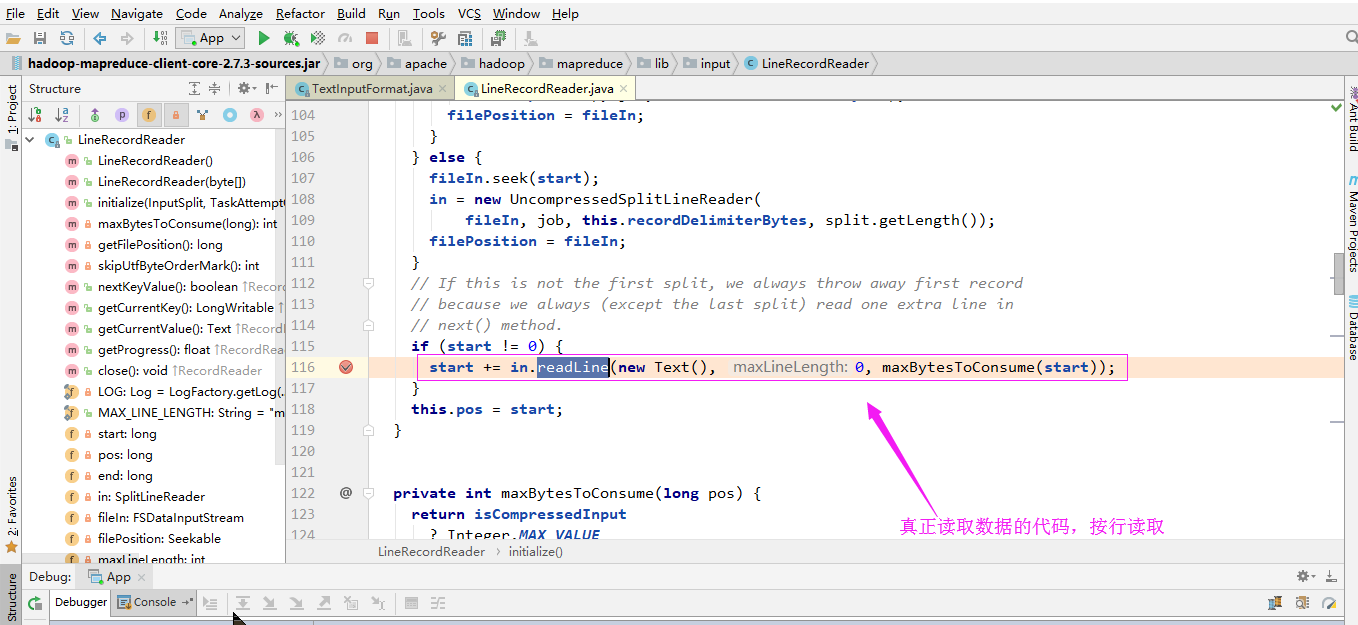
下图是部分调用过程:

4>.SequenceFileInputFormat
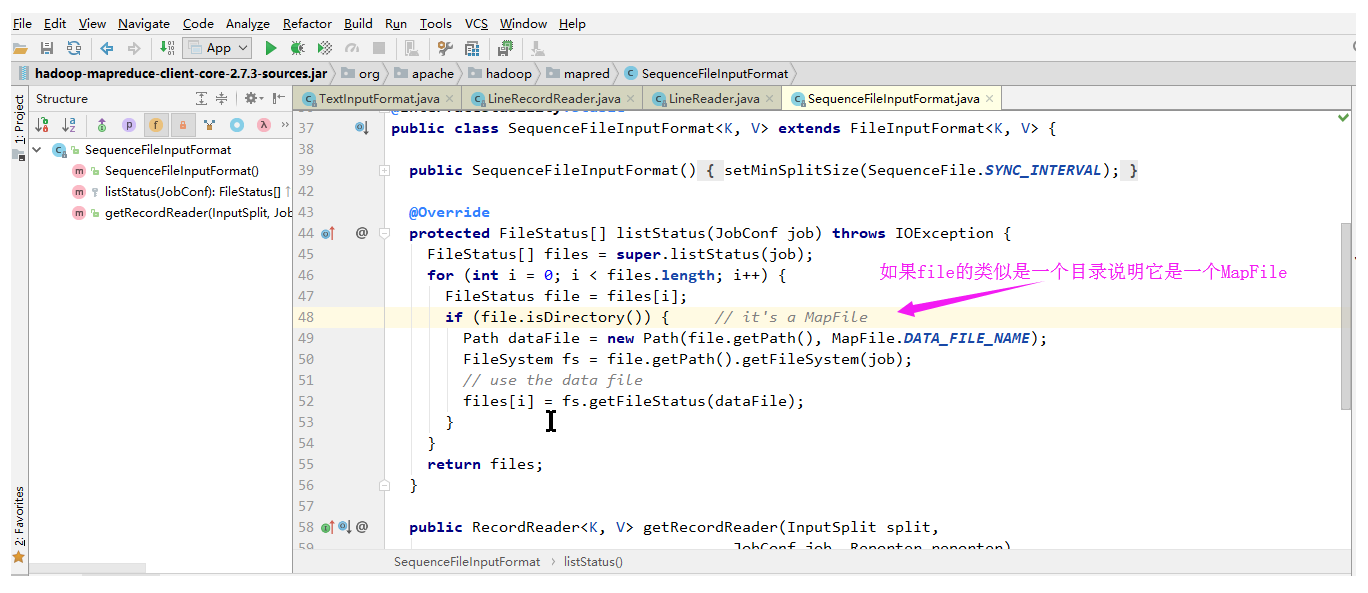
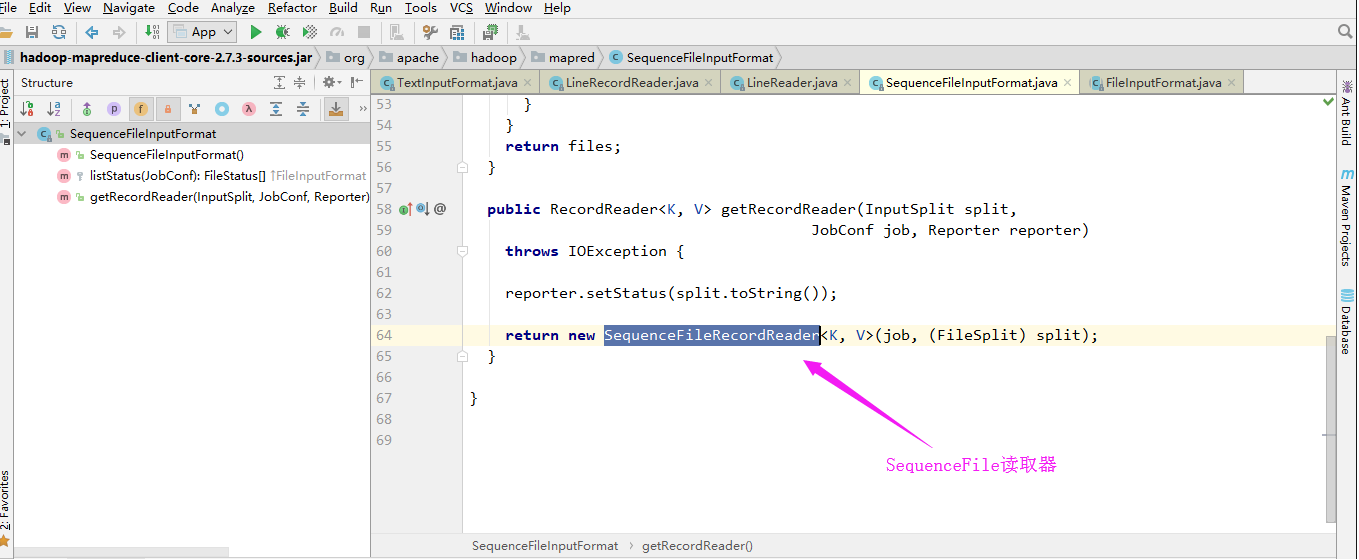
SequenceFileInputFormat是可切割的:

SequenceFile读取器:
Hadoop基础-MapReduce的工作原理第二弹的更多相关文章
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop生态圈-Zookeeper的工作原理分析
Hadoop生态圈-Zookeeper的工作原理分析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zoo ...
随机推荐
- libgdx退出对话框
package com.fxb.newtest; import com.badlogic.gdx.ApplicationListener; import com.badlogic.gdx.Gdx; i ...
- [C#]使用Join与GroupJoin将两个集合进行关联与分组
本文为原创文章.源代码为原创代码,如转载/复制,请在网页/代码处明显位置标明原文名称.作者及网址,谢谢! 本文使用的开发环境是VS2017及dotNet4.0,写此随笔的目的是给自己及新开发人员作为参 ...
- effective c++ 笔记 (23-25)
//---------------------------15/04/08---------------------------- //#23 宁以non_member.non_friend替换m ...
- SpringBoot日记——Docker的使用
跟进互联网的浪潮有时候也挺难的,还没学完就出现新技术了…… 今天来说说,如何使用docker吧~ docker的安装配置 Docker是一个容器,我们怎么理解这个概念.我们做windows系统的时候会 ...
- 数据中心网络(1)-VXLAN
想写个DC系列的文章,站在传统路由交换网络基础上谈谈数据中心网络,一方面是给自己的学习做下总结,另一方面也想分享一些东西. 谈到数据中心网络,能想到的东西无非就VXLAN.SDN.NFV.EVPN这些 ...
- ping命令使用及其常用参数
PING (Packet Internet Groper),因特网包探索器,用于测试网络连接量检查网络是否连通,可以很好地帮助我们分析和判定网络故障.Ping发送一个ICMP(Internet Con ...
- PAT甲题题解-1029. Median (25)-求两序列的中位数,题目更新了之后不水了
这个是原先AC的代码,但是目前最后一个样例会超内存,也就是开不了两个数组来保存两个序列了,意味着我们只能开一个数组来存,这就需要利用到两个数组都有序的性质了. #include <iostrea ...
- 微软必应词典UWP -2017春
必应UWP调研,评测 软件平台:windows10 软件名称:微软必应词典 软件类型:UWP Bug Bug1 当在文本框中进行输入时,在谷歌拼音输入法状态下,无法使用Shift键切换到谷歌拼音的纯英 ...
- 如何自定义微信小程序swiper轮播图面板指示点的样式
https://www.cnblogs.com/myboogle/p/6278163.html 微信小程序的swiper组件是滑块视图容器,也就是说平常我们看到的轮播图就可以用它来做,不过这个组件有很 ...
- 位运算卷积-FWT
问题 给出两个幂级数 \(f,g\) ,求 \[ h=\sum _i\sum _jx^{i\oplus j}f_ig_j \] 其中 \(\oplus\) 是可拆分的位运算. 算法 由于位运算具有独立 ...