NIO 基础之 Buffer
文章目录
- 1. 概述
- 2. 基本属性
- 3. 创建 Buffer
- 4. 向 Buffer 写入数据
- 5. 从 Buffer 读取数据
- 6. rewind() v.s. flip() v.s. clear()
- 7. mark() 搭配 reset()
- 8. 其它方法
- 666. 彩蛋
1. 概述
一个 Buffer ,本质上是内存中的一块,我们可以将数据写入这块内存,之后从这块内存获取数据。通过将这块内存封装成 NIO Buffer 对象,并提供了一组常用的方法,方便我们对该块内存的读写。
Buffer 在 java.nio 包中实现,被定义成抽象类,从而实现一组常用的方法。整体类图如下:
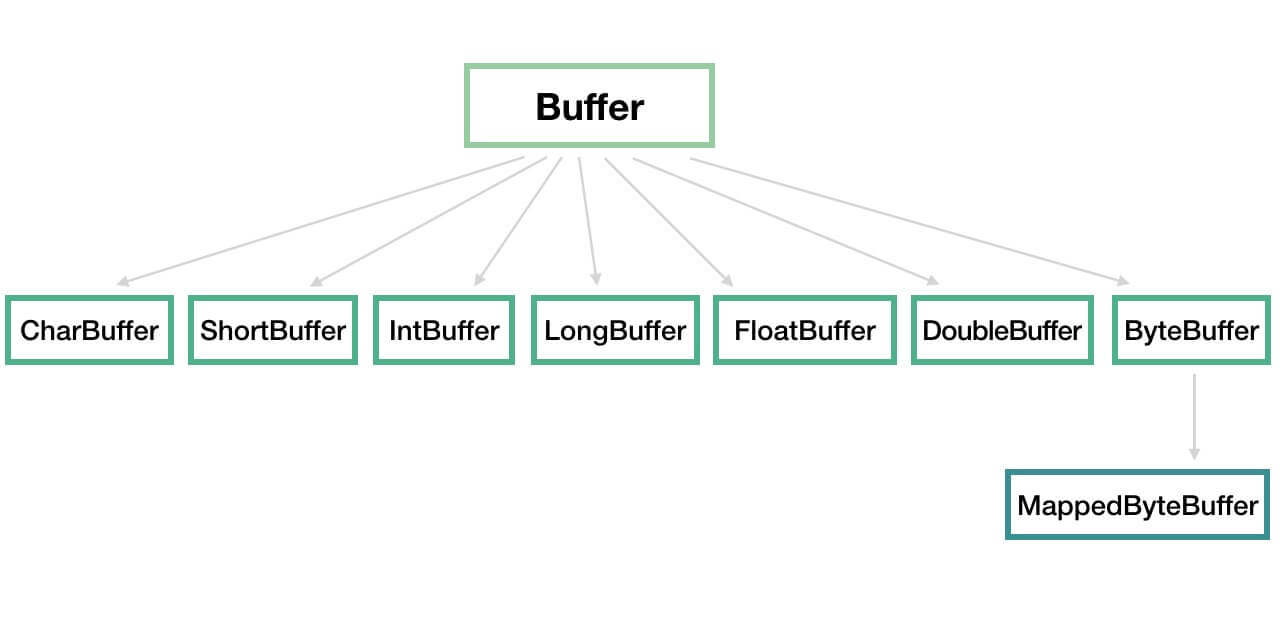
- 我们可以将 Buffer 理解为一个数组的封装,例如 IntBuffer、CharBuffer、ByteBuffer 等分别对应
int[]、char[]、byte[]等。 - MappedByteBuffer 用于实现内存映射文件,不是本文关注的重点。因此,感兴趣的胖友,可以自己 Google 了解,还是蛮有趣的。
2. 基本属性
Buffer 中有 4 个非常重要的属性:capacity、limit、position、mark 。代码如下:
public abstract class Buffer {
// Invariants: mark <= position <= limit <= capacity
|
capacity属性,容量,Buffer 能容纳的数据元素的最大值。这一容量在 Buffer 创建时被赋值,并且永远不能被修改。- Buffer 分成写模式和读模式两种情况。如下图所示:
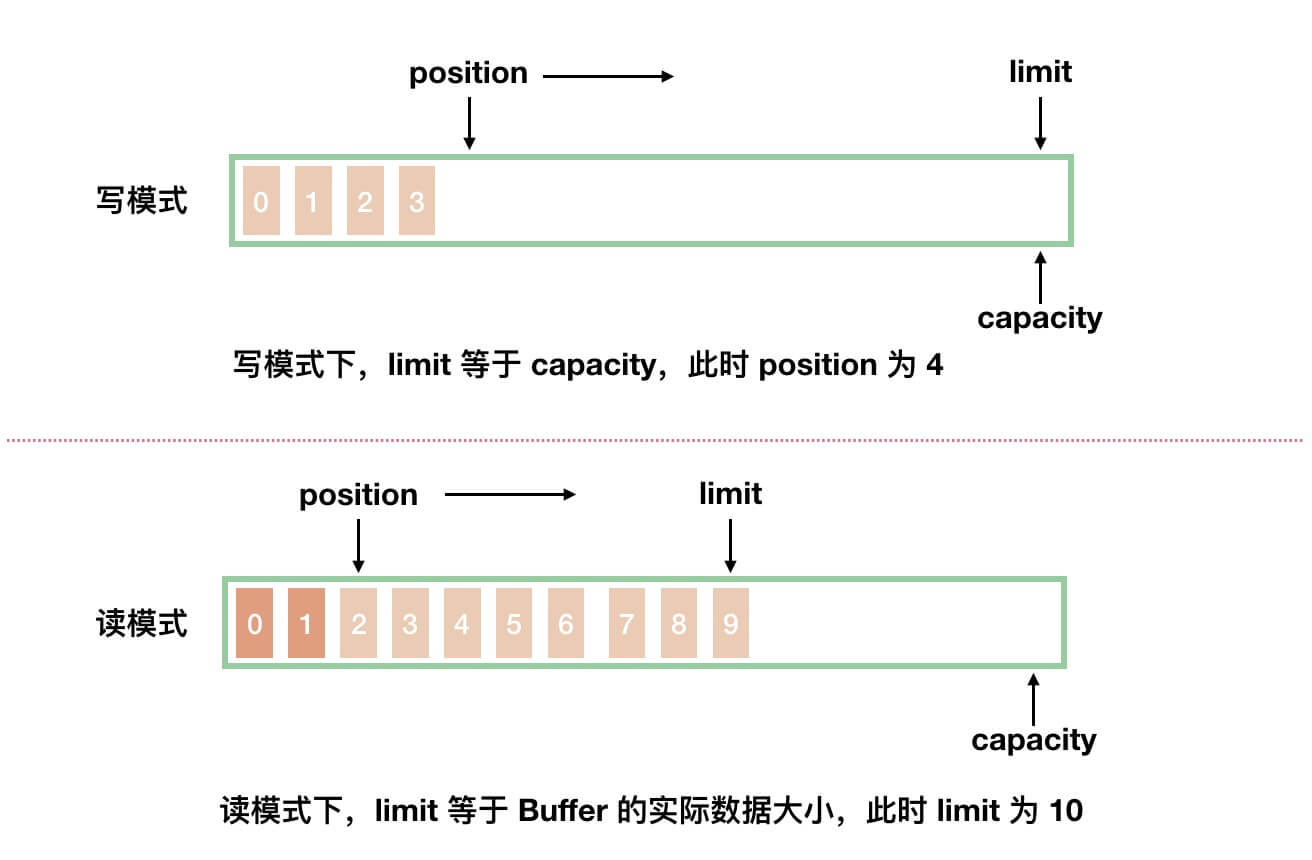
- 从图中,我们可以看到,两种模式下,
position和limit属性分别代表不同的含义。下面,我们来分别看看。
- 从图中,我们可以看到,两种模式下,
position属性,位置,初始值为 0 。- 写模式下,每往 Buffer 中写入一个值,
position就自动加 1 ,代表下一次的写入位置。 - 读模式下,每从 Buffer 中读取一个值,
position就自动加 1 ,代表下一次的读取位置。( 和写模式类似 )
- 写模式下,每往 Buffer 中写入一个值,
limit属性,上限。- 写模式下,代表最大能写入的数据上限位置,这个时候
limit等于capacity。 - 读模式下,在 Buffer 完成所有数据写入后,通过调用
#flip()方法,切换到读模式。此时,limit等于 Buffer 中实际的数据大小。因为 Buffer 不一定被写满,所以不能使用capacity作为实际的数据大小。
- 写模式下,代表最大能写入的数据上限位置,这个时候
mark属性,标记,通过#mark()方法,记录当前position;通过reset()方法,恢复position为标记。- 写模式下,标记上一次写位置。
- 读模式下,标记上一次读位置。
从代码注释上,我们可以看到,四个属性总是遵循如下大小关系:
mark <= position <= limit <= capacity
写到此处,忍不住吐槽了下,Buffer 的读模式和写模式,我认为是有一点“糟糕”。相信大多数人在理解的时候,都会开始一脸懵逼的状态。相比较来说,Netty 的 ByteBuf 就优雅的非常多,基本属性设计如下:
0 <= readerIndex <= writerIndex <= capacity |
- 通过
readerIndex和writerIndex两个属性,避免出现读模式和写模式的切换。
3. 创建 Buffer
① 每个 Buffer 实现类,都提供了 #allocate(int capacity) 静态方法,帮助我们快速实例化一个 Buffer 对象。以 ByteBuffer 举例子,代码如下:
// ByteBuffer.java |
- ByteBuffer 实际是个抽象类,返回的是它的基于堆内( Non-Direct )内存的实现类 HeapByteBuffer 的对象。
② 每个 Buffer 实现类,都提供了 #wrap(array) 静态方法,帮助我们将其对应的数组包装成一个 Buffer 对象。还是以 ByteBuffer 举例子,代码如下:
// ByteBuffer.java |
- 和
#allocate(int capacity)静态方法一样,返回的也是 HeapByteBuffer 的对象。
③ 每个 Buffer 实现类,都提供了 #allocateDirect(int capacity) 静态方法,帮助我们快速实例化一个 Buffer 对象。以 ByteBuffer 举例子,代码如下:
// ByteBuffer.java |
- 和
#allocate(int capacity)静态方法不一样,返回的是它的基于堆外( Direct )内存的实现类 DirectByteBuffer 的对象。
3.1 关于 Direct Buffer 和 Non-Direct Buffer 的区别
FROM 《Java NIO 的前生今世 之三 NIO Buffer 详解》
Direct Buffer:
- 所分配的内存不在 JVM 堆上, 不受 GC 的管理.(但是 Direct Buffer 的 Java 对象是由 GC 管理的, 因此当发生 GC, 对象被回收时, Direct Buffer 也会被释放)
- 因为 Direct Buffer 不在 JVM 堆上分配, 因此 Direct Buffer 对应用程序的内存占用的影响就不那么明显(实际上还是占用了这么多内存, 但是 JVM 不好统计到非 JVM 管理的内存.)
- 申请和释放 Direct Buffer 的开销比较大. 因此正确的使用 Direct Buffer 的方式是在初始化时申请一个 Buffer, 然后不断复用此 buffer, 在程序结束后才释放此 buffer.
- 使用 Direct Buffer 时, 当进行一些底层的系统 IO 操作时, 效率会比较高, 因为此时 JVM 不需要拷贝 buffer 中的内存到中间临时缓冲区中.
Non-Direct Buffer:
- 直接在 JVM 堆上进行内存的分配, 本质上是 byte[] 数组的封装.
- 因为 Non-Direct Buffer 在 JVM 堆中, 因此当进行操作系统底层 IO 操作中时, 会将此 buffer 的内存复制到中间临时缓冲区中. 因此 Non-Direct Buffer 的效率就较低.
笔者之前研究 JVM 内存时,也整理过一个脑图,感兴趣的胖友可以下载:传送门 。
4. 向 Buffer 写入数据
每个 Buffer 实现类,都提供了 #put(...) 方法,向 Buffer 写入数据。以 ByteBuffer 举例子,代码如下:
// 写入 byte |
对于 Buffer 来说,有一个非常重要的操作就是,我们要讲来自 Channel 的数据写入到 Buffer 中。在系统层面上,这个操作我们称为读操作,因为数据是从外部( 文件或者网络等 )读取到内存中。示例如下:
int num = channel.read(buffer); |
上述方法会返回从 Channel 中写入到 Buffer 的数据大小。对应方法的代码如下:
public interface ReadableByteChannel extends Channel { public int read(ByteBuffer dst) throws IOException; }
注意,通常在说 NIO 的读操作的时候,我们说的是从 Channel 中读数据到 Buffer 中,对应的是对 Buffer 的写入操作,初学者需要理清楚这个。
5. 从 Buffer 读取数据
每个 Buffer 实现类,都提供了 #get(...) 方法,从 Buffer 读取数据。以 ByteBuffer 举例子,代码如下:
// 读取 byte |
对于 Buffer 来说,还有一个非常重要的操作就是,我们要讲来向 Channel 的写入 Buffer 中的数据。在系统层面上,这个操作我们称为写操作,因为数据是从内存中写入到外部( 文件或者网络等 )。示例如下:
int num = channel.write(buffer); |
上述方法会返回向 Channel 中写入 Buffer 的数据大小。对应方法的代码如下:
public interface WritableByteChannel extends Channel { public int write(ByteBuffer src) throws IOException; }
6. rewind() v.s. flip() v.s. clear()
6.1 flip
如果要读取 Buffer 中的数据,需要切换模式,从写模式切换到读模式。对应的为 #flip() 方法,代码如下:
public final Buffer flip() {
|
使用示例,代码如下:
buf.put(magic); // Prepend header |
6.2 rewind
#rewind() 方法,可以重置 position 的值为 0 。因此,我们可以重新读取和写入 Buffer 了。
大多数情况下,该方法主要针对于读模式,所以可以翻译为“倒带”。也就是说,和我们当年的磁带倒回去是一个意思。代码如下:
public final Buffer rewind() {
|
- 从代码上,和
#flip()相比,非常类似,除了少了第一行的limit = position的代码块。
使用示例,代码如下:
channel.write(buf); // Write remaining data |
6.3 clear
#clear() 方法,可以“重置” Buffer 的数据。因此,我们可以重新读取和写入 Buffer 了。
大多数情况下,该方法主要针对于写模式。代码如下:
public final Buffer clear() {
|
- 从源码上,我们可以看出,Buffer 的数据实际并未清理掉,所以使用时需要注意。
- 读模式下,尽量不要调用
#clear()方法,因为limit可能会被错误的赋值为capacity。相比来说,调用#rewind()更合理,如果有重读的需求。
使用示例,代码如下:
buf.clear(); // Prepare buffer for reading |
7. mark() 搭配 reset()
7.1 mark
#mark() 方法,保存当前的 position 到 mark 中。代码如下:
public final Buffer mark() {
|
7.2 reset
#reset() 方法,恢复当前的 postion 为 mark 。代码如下:
public final Buffer reset() {
|
8. 其它方法
Buffer 中还有其它方法,比较简单,所以胖友自己研究噢。代码如下:
// ========== capacity ========== |
NIO 基础之 Buffer的更多相关文章
- NIO基础之Buffer
java.io 核心概念是流,即面向流的编程,在java中一个流只能是输入流或者输出流,不能同时具有两个概念. java.nio核心是 selector.Channel.Buffer ,是面向缓冲区( ...
- NIO基础操作
原文链接http://zhhll.icu/2020/05/18/java%E5%9F%BA%E7%A1%80/IO/NIO%E5%9F%BA%E6%9C%AC%E6%93%8D%E4%BD%9C/ N ...
- nio之缓冲区(Buffer)理解
一.缓冲区简介 Nio中的 Buffer 是用于存储特定基础类型的一个容器.为了能熟练的使用 Nio中的各种 Buffer , 我们需要理解 Buffer 中的 三个重要 的属性. 1. capaci ...
- Java NIO Channel和Buffer
Java NIO Channel和Buffer @author ixenos Channel和Buffer的关系 1.NIO速度的提高来自于所使用的结构更接近于OS执行I/O的方式:通道和缓冲器: 2 ...
- Java中的NIO基础知识
上一篇介绍了五种NIO模型,本篇将介绍Java中的NIO类库,为学习netty做好铺垫 Java NIO 由3个核心组成,分别是Channels,Buffers,Selectors.本文主要介绍着三个 ...
- Java NIO中的Buffer 详解
Java NIO中的Buffer用于和NIO通道进行交互.如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的.缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存.这块内存被包装成NIO ...
- NIO之缓冲区(Buffer)的数据存取
缓冲区(Buffer) 一个用于特定基本数据类行的容器.有java.nio包定义的,所有缓冲区都是抽象类Buffer的子类. Java NIO中的Buffer主要用于与NIO通道进行交互,数据是从通道 ...
- Netty学习笔记(一)——nio基础
Netty简单认识: 1) Netty 是由JBOSS 提供的一个Java 开源框架. 2) Netty 是一个异步的.基于事件驱动的网络应用框架,用以快速开发高性能.高可靠性的网络I0 程序. 3) ...
- NIO(一):Buffer缓冲区
一.NIO与IO: IO: 一般泛指进行input/output操作(读写操作),Java IO其核心是字符流(inputstream/outputstream)和字节流(reader/writer ...
随机推荐
- Ng第十六课:推荐系统(Recommender Systems)
16.1 问题形式化 16.2 基于内容的推荐系统 16.3 协同过滤 16.4 协同过滤算法 16.5 矢量化:低秩矩阵分解 16.6 推行工作上的细节:均值归一化 16.1 问题形式 ...
- TypeError: c is null
找到相应的js报错地方..添加判断条件 if(styles == null) { return ''; }
- Flash网页小游戏开发教程
架设服务器 地图 程序员
- spring mvc使用ModelAndView时发生No request handling method with name '方法 名' in class [类名]的错误
我日,下午关于标题错误查了好久,网上啥说法都有, 后来发现是ModelAndView的路径引错了 正确路径应该为: import org.springframework.web.servlet.Mod ...
- nodejs mongodb 数据库封装DB类 -转
使用到了nodejs的插件mongoose,用mongoose操作mongodb其实蛮方便的. 关于mongoose的安装就是 npm install -g mongoose 这个DB类的数据库配置是 ...
- set_time_limit
语法 : void set_time_limit (int seconds)说明 : 设定一个程式所允许执行的秒数,如果到达限制的时间,程式将会传回错误.它预设的限制时间是30秒,max_execut ...
- AngularJS $scope 继承性 作用 生命周期
一.基本概念 作用域是一个指向应用模型的对象,相当于MVVM中的ViewModel,能绑定数据(属性)和行为(方法),能监控表达式和传递事件,是实现双向绑定的基础,是应用在 HTML (视图) 和 J ...
- TVS二极管
TVS管命名规则: TVS管的型号由三部分组成:系列名+电压值+单/双向符号 系列名代表不同的峰值脉冲功率和封装形式 ① SMAJ.SMBJ.SMCJ.SMDJ表示贴片封装:分别代表的峰值脉冲 ...
- ceph osd 批量删除
ceph osd 批量删除,注意删除的是当前节点正在使用的osd,数据删除有风险,所以最后一步没有去format磁盘,给你留下一剂后悔药. #!/bin/bash osd_list=`mount|gr ...
- [转载]DevOps发展的四个重要阶段
DevOps是敏捷开发的延续,它将敏捷的精神延伸至IT运营(IT Operation)阶段.敏捷开发的主要目的是响应变化,快速交付价值.以2001年的敏捷宣言发布这个里程碑为起点,开始几年内企业主要在 ...