VS2010与VS2013中的多字节编码与Unicode编码问题
1. 多字节字符与单字节字符
char与wchar_t
我们知道C++基本数据类型中表示字符的有两种:char、wchar_t。
char叫多字节字符,一个char占一个字节,之所以叫多字节字符是因为它表示一个字时可能是一个字节也可能是多个字节。一个英文字符(如’s’)用一个char(一个字节)表示,一个中文汉字(如’中’)用3个char(三个字节)表示。
wchar_t被称为宽字符,一个wchar_t占2个字节。之所以叫宽字符是因为所有的字都要用两个字节(即一个wchar_t)来表示,不管是英文还是中文。
在C++中,一般操作如下:
1. 用常量字符给wchar_t变量赋值时,前面要加L。如: wchar_t wch2 = L’中’;
2. 用常量字符串给wchar_t数组赋值时,前面要加L。如: wchar_t wstr2[3] = L”中国”;
3. 如果不加L,对于英文可以正常,但对于非英文(如中文)会出错。
2. 多字节字符串与宽字节字符串
std::string与std::wstring
字符数组可以表示一个字符串,但它是一个定长的字符串,我们在使用之前必须知道这个数组的长度。
为方便字符串的操作,STL为我们定义好了字符串的类string和wstring。大家对string肯定不陌生,但wstring可能就用的少了。
string是普通的多字节版本,是基于char的,对char数组进行的一种封装。
wstring是Unicode版本,是基于wchar_t的,对wchar_t数组进行的一种封装。
3.字符集(Charcater Set)与字符编码(Encoding)
字符集(Charcater Set或Charset):是一个系统支持的所有抽象字符的集合,也就是一系列字符的集合。
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
常见的字符集有:ASCII字符集、GB2312字符集(主要用于处理中文汉字)、GBK字符集(主要用于处理中文汉字)、Unicode字符集等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个字符集(如字母表或音节表),与计算机能识别的二进制数字进行配对。即它能在符号集合与数字系统之间建立对应关系,是信息处理的一项基本技术。
通常人们用符号集合(一般情况下就是文字)来表达信息,而计算机的信息处理系统则是以二进制的数字来存储和处理信息的。
字符编码就是将符号转换为计算机能识别的二进制编码。
一般一个字符集等同于一个编码方式,ANSI体系(ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符)的字符集如ASCII、ISO 8859-1、GB2312、GBK等等都是如此。
一般我们说一种编码都是针对某一特定的字符集。 一个字符集上也可以有多种编码方式,例如UCS字符集(也是Unicode使用的字符集)上有UTF-8、UTF-16、UTF-32等编码方式。
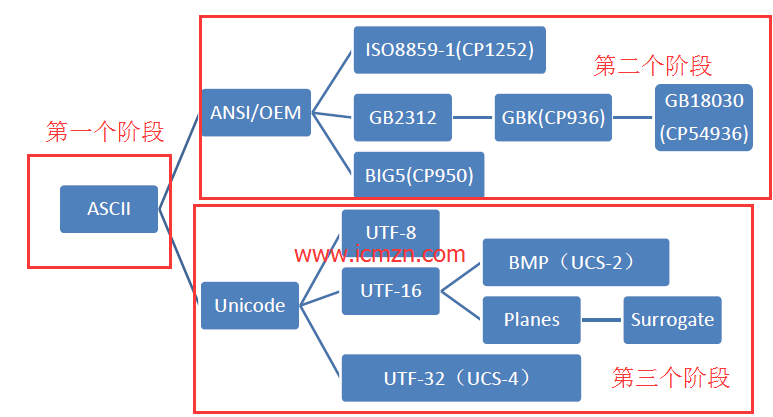
从计算机字符编码的发展历史角度来看,大概经历了三个阶段:
第一个阶段:ASCII字符集和ASCII编码。
计算机刚开始只支持英语(即拉丁字符),其它语言不能够在计算机上存储和显示。ASCII用一个字节(Byte)的7位(bit)表示一个字符,第一位置0。后来为了表示更多的欧洲常用字符又对ASCII进行了扩展,又有了EASCII,EASCII用8位表示一个字符,使它能多表示128个字符,支持了部分西欧字符。第二个阶段:ANSI编码(本地化)
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2
个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312
编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。第三个阶段:UNICODE(国际化)
为了使国际间信息交流更加方便,国际组织制定了 UNICODE
字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。UNICODE
常见的有三种编码方式:UTF-8(1个字节表示)、UTF-16((2个字节表示))、UTF-32(4个字节表示)。我们可以用一个树状图来表示由ASCII发展而来的各个字符集和编码的分支:
4. 工程里多字节与宽字符的配制
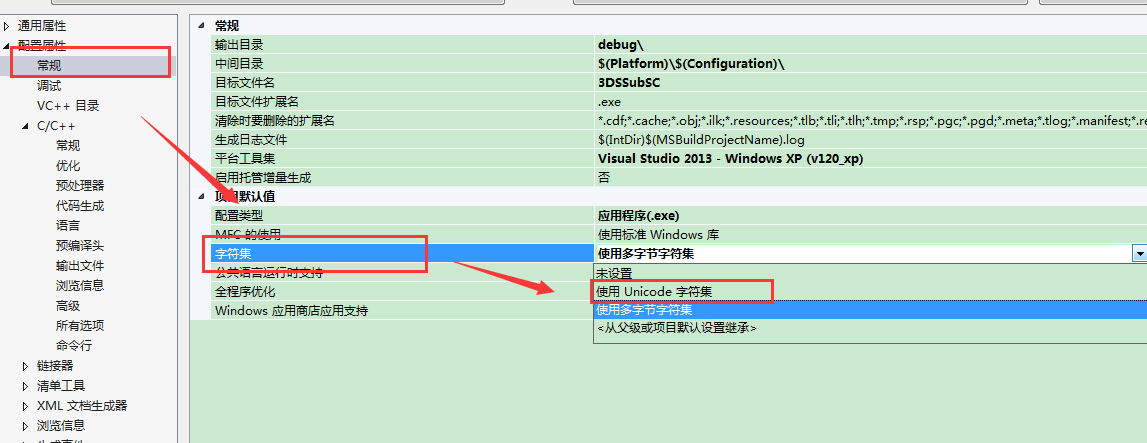
目前对于C++开发IDE,业内显著使用VS2010,以及VS2013.但是,这两个版本对字符的默认设置不同:
VS2010 默认采用“多字节”编码方式(单字符);VS2013则采用UNICODE编码方式(宽字符)。
一般项目如下设置:
VS2010如下:

VS2013的设置方式相同,但是,VS2013默认的字符集为UNICODE字符设置
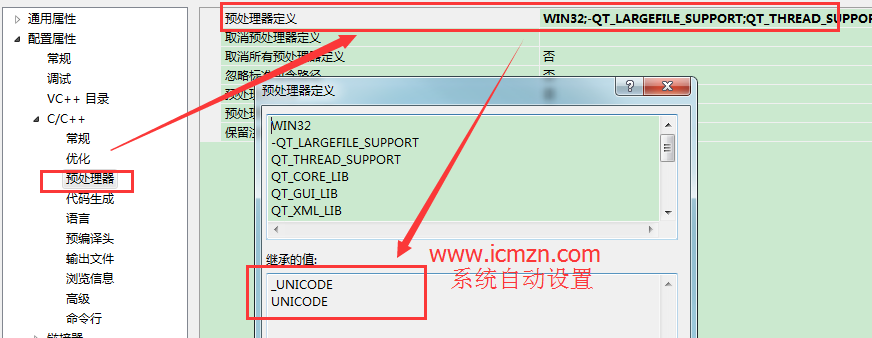
5. 需要注意的是
当设置为Unicode字符集时, IDE会自动设置会有预编译宏:_UNICODE、UNICODE。
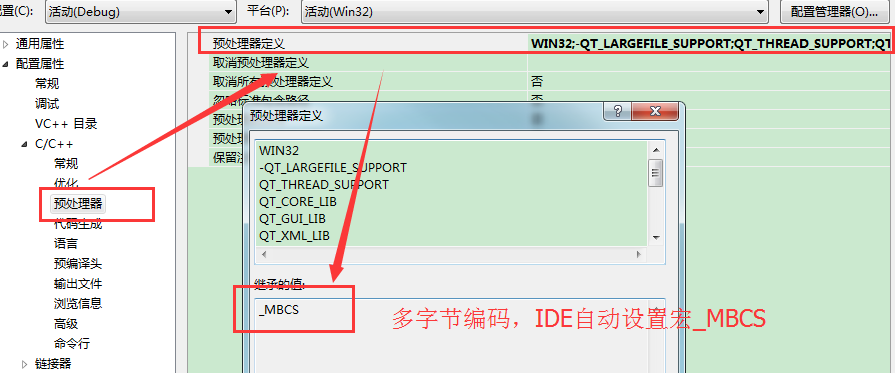
当设置为Use Multi-Byte Character Set时,会有预编译宏:_MBCS
6. Unicode Character Set与Multi-Byte Character Set有什么区别呢?
不同版本的IDE中,如VS2010,VS2013中,默认的编码字符集不同,
因为在项目开发的进程中,可能会采用第三方库,而第三方库,往往会采用不同的编码来完成。如较为底层且较为成熟的Zip压缩解压库源文件中,如果采用VS2013编译,可会出现有些函数参数的类型不相符,需要转化为宽字节字符串等相关的异常修复问题。
这是因为,预编译预设了_UNICODE、UNICODE宏,这样对于不同的函数版本中,就会选择宽字节的的函数版本

Unicode Character Set就是Unicode字符集,一般是指UTF-16编码的Unicode。也就是说每个字符编码为两个字节,两个字节可以表示65535个字符,65535个字符可以表示世界上大部分的语言。
在商业软件应用中,一般采用Unicode编码方法,一般推荐使用Unicode的方式,因为它可以适应各个国家语言,在进行软件国际时将会非常便得。除非在对存储要求非常高的时候,或要兼容C的代码时,我们才会使用多字节的方式 。
但是如果做科研软件开发,则推荐采用多字节编码,因为,这是一种以char为基础的多字节编码方案,会兼容其他开源库的使用。
7. Unicode(宽字节)编码的经验
(1)
除了使用L”Title”外,还可以使用_T(“Title”)和_TEXT(“Title”)。而且你会发现在MFC和Win32程序中会更多地使用_T和_TEXT,那_T、_TEXT和L之间有什么区别呢?
多字节字符(char)串常量时用一般的双引号括起来就可以了,如”String test”;而表示宽字节字符(wchar_t)串常量时要在引号前加L,如L”String test”。
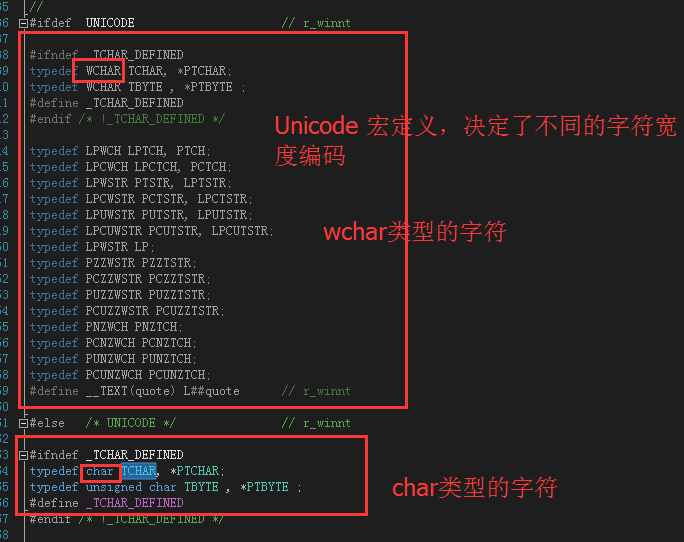
(2)VC++中还有一些常用的宏你也许会范糊涂,如Dword、LPSTR、LPWSTR、LPCSTR、LPCWSTR、LPTSTR、LPCTSTR。
这里我们统一总结一下: 常见的宏:
相互转换方法:
LPWSTR->LPTSTR: W2T();
LPTSTR->LPWSTR: T2W();
LPCWSTR->LPCSTR: W2CT();
LPCSTR->LPCWSTR: T2CW(); ANSI->UNICODE: A2W();
UNICODE->ANSI: W2A();
字符串函数:
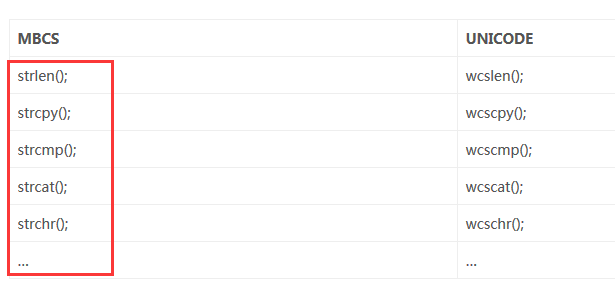
通过这些函数和宏的命名你也许就发现了一些霍规律,一般带有前缀w(或后缀W)的都是用于宽字符的,而不带前缀w(或带有后缀A)的一般是用于多字节字符的。
endl;
VS2010与VS2013中的多字节编码与Unicode编码问题的更多相关文章
- SQL Server 中怎么查看一个字母的ascii编码或者Unicode编码(转载)
在sql中怎么查看一个字符的ascii编码或Unicode编码: SELECT ASCII('a') AS [AsciiNum]--字符获取ASCII码 SELECT UNICODE(N'a') AS ...
- ASCII编码和Unicode编码的区别
链接: 计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了.Unicode标准也在不断发展,但最常用的是用两个字 ...
- 初学者对ASCII编码、Unicode编码、UTF-8编码的理解
最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是 255(二进制 11111111=十进制 255),如果要表示更大的整数,就必须用更多的字节. ...
- SQL Server 中怎么查看一个字母的ascii编码或者Unicode编码
参考文章:微信公众号文章 在sql中怎么查看一个字符的ascii编码,so easy !! select ASCII('a') SELECT CHAR(97) charNum SELECT UNICO ...
- 刨根究底字符编码之八——Unicode编码方案概述
Unicode编码方案概述 1. 前面讲过,随着计算机发展到世界各地,于是各个国家和地区各自为政,搞出了很多既兼容ASCII但又互相不兼容的各种编码方案.这样一来同一个二进制编码就有可能被解释成不 ...
- ASCII编码、Unicode编码、UTF-8
一.区别 ASCII.Unicode 是“字符集” UTF-8 .UTF-16.UTF-32 是“编码规则” 其中: 字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code ...
- 三种常见的编码:ASCII码、UTF-8编码、Unicode编码等字符占领的字节数
ASCII码: 一个英文字母(不分大写和小写)占一个字节的空间.一个中文汉字占两个字节的空间. 一个二进制数字序列,在计算机中作为一个数字单元,一般为8位二进制数,换算为十进制. 最小值0,最大值25 ...
- java 中文转换成Unicode编码和Unicode编码转换成中文
转自:一叶飘舟 http://blog.csdn.net/jdsjlzx/article/details/ package lia.meetlucene; import java.io.IOExcep ...
- Java实现 中文转换成Unicode编码 和 Unicode编码转换成中文
想要实现中文字符转换为Unicode编码的话主要用到的是一个这样的包,自己可以去API文档里面查看下的 java.util.Properties; 直接进入主题吧,主要是 package Test01 ...
随机推荐
- 9.Mysql字符集
9.字符集9.1 字符集概述 字符集就是一套文字符号及其编码.比较规则的集合. ASCII(American Standard Code for Information Interchange)字符集 ...
- 优化myeclipse启动速度以及解决内存不足问题
解决myeclipse内存不足问题: 使用 MyEclipse 开发项目后,随着项目文件的增多,以及运行时间的增加,实际上 MyEclipse 所消耗的内存是会一直增大的,有的时候会出现 MyEcli ...
- yii2.0增删改查
//关闭csrf public $enableCsrfValidation = false; 1.sql语句 //查询 $db=\Yii::$app->db ->createCommand ...
- Python GUI中 text框里实时输出
首先GUI中不同函数的局部变量的问题. 发现不同button定义的函数得到的变量无法通用. 通过global 函数内的变量可以解决这个问题 def openfiles2(): global s2fna ...
- 脚本路径问题_dirname
pwd可获取命令当前的路径 可是若我们想在脚本中获取脚本所在文件夹的路径,这种方法是不够用的. 例如,我们的脚本放在/home/user/script/下,名字叫做getpath.sh getpath ...
- netty4初步使用
文件 D:\jp\netty\NtServer.java import io.netty.bootstrap.ServerBootstrap; import io.netty.channel.Chan ...
- ubuntu16下的/etc/resolv.conf重置的解决方案
此文件存放了网络网关信息,重启后会刷新,刷新来源有两个可能 一个是根据文件中的resolvconf目录下的resolv.conf.d目录下的base文件 另一个来源是/etc/network/inte ...
- 一窥kbmmw中的 smart service
在kbmmw 的新版中(还没有发布),将会有一个叫做smart service 的服务.这种服务的属性基于服务器端,并且可以自动注册服务名,下面就是一个简单例子代码.这个服务里面有有三个发布的函数:e ...
- 2018.12.05 codeforces 961E. Tufurama(主席树)
传送门 一眼主席树sbsbsb题(%%%树状数组大佬们). 简化题意:求满足x<y,y≤ax,x≤ayx<y,y\le a_x,x\le a_yx<y,y≤ax,x≤ay的(x, ...
- 百度地图经纬度和地址互转(Java代码)
这是基于springmvc+mybatis 的一个controller.如果不是这个框架,可以把方法实体抽到自己写的一个类中,然后再测试 package com.uwitec.controller.s ...