python 网络爬虫介绍
一、网络爬虫相关概念
网络爬虫介绍
我们都知道,当前我们所处的时代是大数据的时代,在大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集。
优酷推出的火星情报局就是基于网络爬虫和数据分析制作完成的。其中每期的节目话题都是从相关热门的互动平台中进行相关数据的爬取,然后对爬取到的数据进行数据分析而得来的。另一方面,优酷根据用户实时观看视频时的前进,后退等行为数据,能够推测计算出观众的兴趣点和爱好点,这样有助于节目的剪辑和后期的节目方案的编写。
今日头条作为一个新闻推荐类的应用,其内部的新闻数据都是通过爬虫程序在各个新闻网站进行新闻数据的爬取,然后通过相应的处理和运算将用户感兴趣的新闻话题推送到用户的手机上。、
robots.txt协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
反爬虫
门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
反反爬虫
爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
二、HTTP和HTTPS协议
2.1 HTTP协议
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
工作原理:
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
2.2 HTTP之Request:
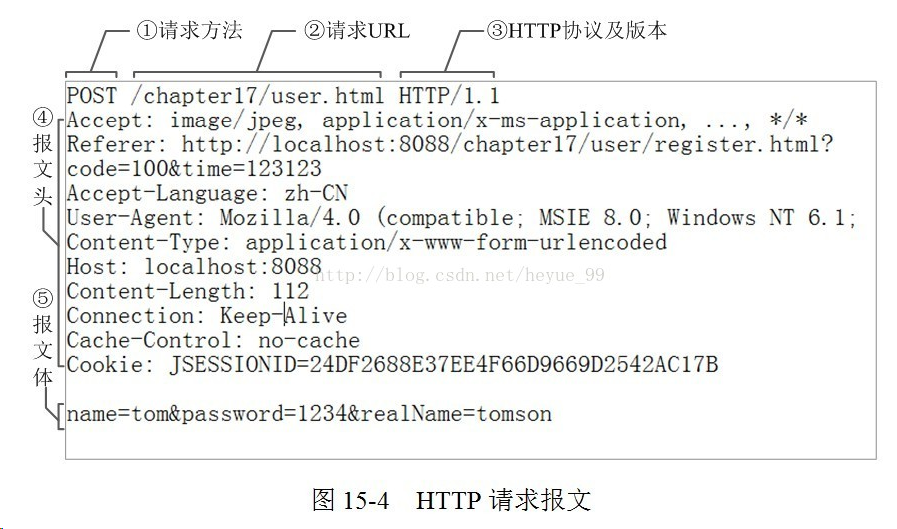
报文头:常被叫做请求头,请求头中存储的是该请求的一些主要说明(自我介绍)。服务器据此获取客户端的信息。
常见的请求头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集
Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式
Accept-Language:浏览器通过这个头告诉服务器,它的语言环境
Host:浏览器通过这个头告诉服务器,想访问哪台主机
If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间
Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链
Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接
X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问
User-Agent:请求载体的身份标识
报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
2.3 HTTP之Response:
服务器回传一个HTTP响应到客户端的响应消息包括以下组成部分:

常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里
Server:服务器通过这个头,告诉浏览器服务器的型号
Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式
Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度
Content-Language: 服务器通过这个头,告诉浏览器语言环境
Content-Type:服务器通过这个头,告诉浏览器回送数据的类型
Refresh:服务器通过这个头,告诉浏览器定时刷新
Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据
Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的
Expires: -1 控制浏览器不要缓存
Cache-Control: no-cache
Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
2.4 HTTPS协议
1.官方概念:
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。

2.5 HTTPS采用的加密技术
SSL加密技术
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:


非对称秘钥加密技术
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。以下是非对称加密的原理图:

但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
2.7 HTTPS的证书机制
在上面我们讲了非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
1:服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起

2:服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密
python 网络爬虫介绍的更多相关文章
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- Python 网络爬虫 001 (科普) 网络爬虫简介
Python 网络爬虫 001 (科普) 网络爬虫简介 1. 网络爬虫是干什么的 我举几个生活中的例子: 例子一: 我平时会将 学到的知识 和 积累的经验 写成博客发送到CSDN博客网站上,那么对于我 ...
- Python 网络爬虫干货总结
Python 网络爬虫干货总结 爬取 对于爬取来说,我们需要学会使用不同的方法来应对不同情景下的数据抓取任务. 爬取的目标绝大多数情况下要么是网页,要么是 App,所以这里就分为这两个大类别来进行了介 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 利用Python网络爬虫抓取微信好友的所在省位和城市分布及其可视化
前几天给大家分享了如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,感兴趣的小伙伴可以点击链接进行查看.今天小编给大家介绍如何利用Python网络爬虫抓取微信好友的省位和城市,并且将 ...
- 如何利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例
前几天给大家分享了利用Python网络爬虫抓取微信朋友圈的动态(上)和利用Python网络爬虫爬取微信朋友圈动态——附代码(下),并且对抓取到的数据进行了Python词云和wordart可视化,感兴趣 ...
随机推荐
- 本地用maven搭建SpringMvc+redis集成
---恢复内容开始--- 首先本地需要搭建私服,简单说一下搭建私服的步骤 1.为什么使用Nexus 如果没有私服,我们所需的所有构件都需要通过maven的中央仓库和第三方的Maven仓库下载到本地,而 ...
- Javascript执行流总结
面对各种各样的JavaScript代码,我们有时候难免会犯错.可当自己仔细研究一下,哦原来是这么回事.有时候怎么会想为什么Javascript程序会是这样执行的呢?为什么没有得到自己预期的答案呢?自己 ...
- Python字符串和编码
在最早的时候只有127个字符被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码被成为ASCII编码. 但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突 ...
- Azure Resource Manager 概述
应用程序的基础结构通常由许多组件构成:可能有虚拟机.存储帐户和虚拟网络,或 Web 应用.数据库.数据库服务器和第三方服务. 这些组件不会以独立的实体出现,而是以单个实体的相关部件和依赖部件出现. 如 ...
- SqlServer PIVOT函数快速实现行转列,UNPIVOT实现列转行
我们在写Sql语句的时候没经常会遇到将查询结果行转列,列转行的需求,拼接sql字符串,然后使用sp_executesql执行sql字符串是比较常规的一种做法.但是这样做实现起来非常复杂,而在SqlSe ...
- IDEA中的替换功能(替换代码中的变量名很好用哦)
刚刚上班不久,这两天正在研究公司项目里面的代码,今天用阿里的插件扫描了一下代码,发现代码中有很多变量的命名,没有遵循驼峰式的命名规则.一开始我一个一个的修改这些变量名,后来无意中用了一下Ctrl+F( ...
- Linux下源码编译安装MySQL 5.5.8
准备工作: 新建用户和用户组 groupadd mysql useradd -g mysql mysql 1:下载: bison-2.4.2.tar.bz2 cmake-2.8.3.tar.gz ma ...
- 【PyCharm疑问】在pycharm中带有中文时,有时会导致程序判断错误,是何原因?
1.会导致程序打印false错误的代码如下: # -*- coding:utf-8 -*- import os import sys from uiautomator import device as ...
- C#中的事件(event)处理机制
委托 语法 [访问修饰符] delegate 返回类型 委托名(); 委托的特点 类似于C++函数指针,但它是类型安全的:委托允许将方法作为参数进行传递:委托可用于定义回调方法:委托可以链接在一起:如 ...
- python爬虫(三)
webdriver Selenium是ThroughtWorks公司开发的一套Web自动化测试工具.它分为三个组件:Selenium IDE,Selenium RC (Remote Control), ...