关于Sql Server的一些知识点的定义总结
数据库完整性:是指数据库中数据在逻辑上的一致性、正确性、有效性和相容性
实体完整性(Entity Integrity 行完整性):实体完整性指表中行的完整性。主要用于保证操作的数据(记录)非空、唯一且不重复。即实体完整性要求每个关系(表)有且仅有一个主键,每一个主键值必须唯一,而且不允许为“空”(NULL)或重复。
域完整性(Domain Integrity 列完整性):是指数据库表中的列必须满足某种特定的数据类型或约束。其中约束又包括取值范围、精度等规定。表中的CHECK、FOREIGN KEY 约束和DEFAULT、 NOT NULL定义都属于域完整性的范畴。
参照完整性(Referential Integrity)属于表间规则:对于永久关系的相关表,在更新、插入或删除记录时,如果只改其一,就会影响数据的完整性。如删除父表的某记录后,子表的相应记录未删除,致使这些记录称为孤立记录。
参照完整性规则(Referential Integrity)要求:若属性组F是关系模式R1的主键,同时F也是关系模式R2的外键,则在R2的关系中,F的取值只允许两种可能:空值或等于R1关系中某个主键值。
Sql Server的存储结构,页、区、堆
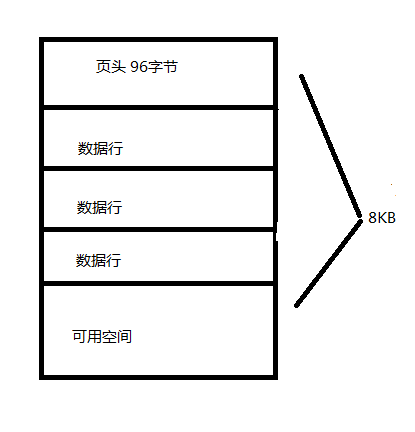
页:用于数据存储的连续的磁盘空间块,SQL Server中数据存储的基本单位是页,磁盘I/O操作在页级执行,页的大小为8KB。每页的开头是96字节的页头,用于存储有关页的系统信息,包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元ID;其他便是存储数据的数据行与剩下可用空间,结构图如下(个人绘制)
区间:区是管理空间的基本单位,一个区是8个物理上连续的页(即64KB)的集合,所有页都存储在区中。SQL Server有两种类型的区:统一区和混合区。
堆:堆是指不含聚集索引的表,它的数据不按任何顺序进行存储。
联系一个堆中的数据的唯一结构是被称为索引分配映射(IAM)的一个位图页,当扫描对象时,SQl server使用IAM页来遍历该对象的数据。
堆表内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是记录在 IAM 页内的信息
假设某订单明细表中有100万条数据,需要查询某个订单的明细数据,如下:
select * from T_EPZ_INOUT_ENTRY_DETAIL where entry_apply_id='31227000034000090169'
如果在堆表中进行查询,SQL Server通过扫描 IAM 页对堆表进行全表扫描,对entry_apply_id比较100万次,如果以entry_apply_id字段建立索引,则因为索引键值数据都必定以B-Tree有顺序的摆放,所以可采用二分查找找数据。也就是2的N次方大于记录数,就可以找到该条数据。而2的20次方大于100万,因此最多找寻20次就可以找到该条记录。20次与100万次的比较,你可以轻松感受出性能的差异。
由此引出索引的概念
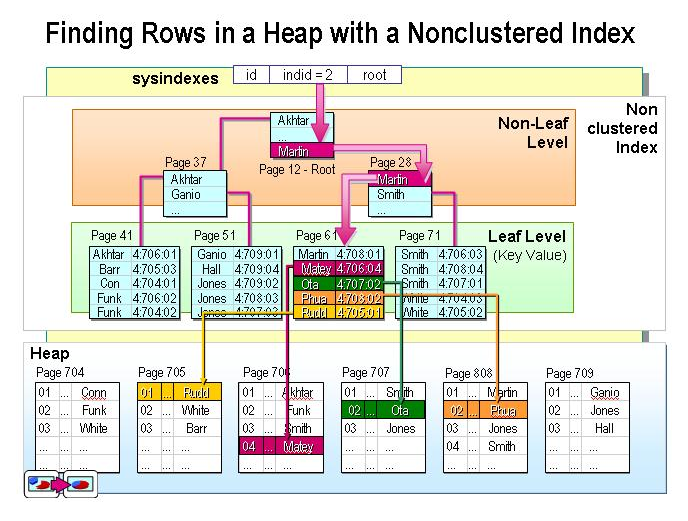
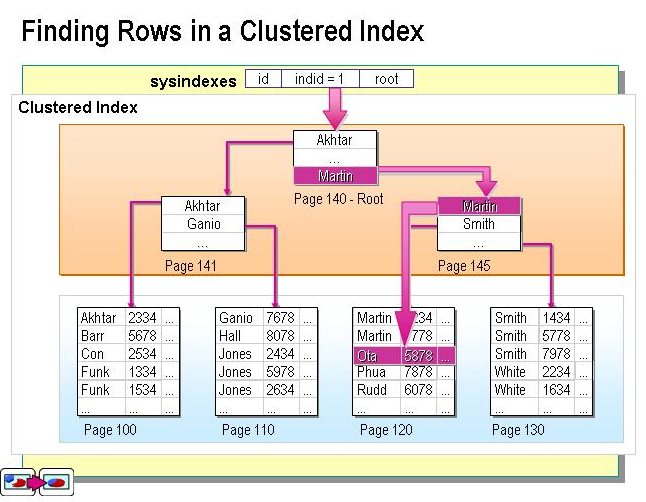
索引分为聚集索引与非聚集索引
聚集索引 :聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度
非聚集索引:非聚集索引是一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同
聚集索引与非聚集索引的形象比喻
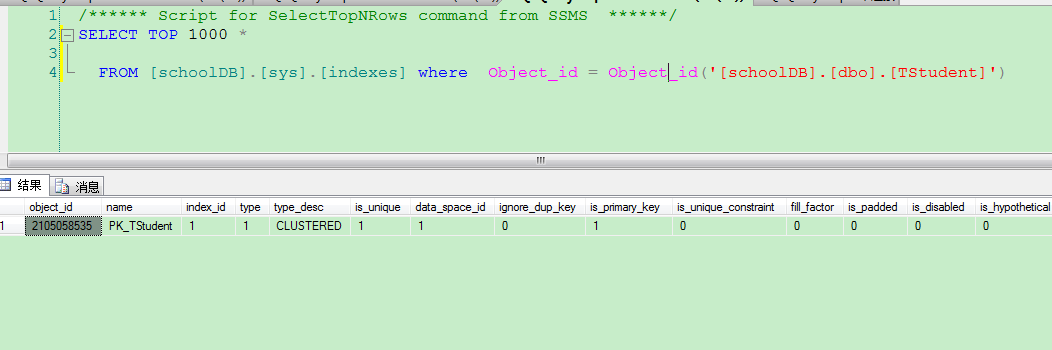
dbcc showcontig(Tstudent,non_sname) --Tstudent表明,PK_TStudent索引名 ,查询页分裂情况 dbcc indexdefrag(schoolDB,Tstudent,non_sname)--索引整理 create nonclustered index non_sname on TStudent(sname) with drop_existing,fillfactor = 50--重建索引,并且制定填充因子 dbcc show_statistics(tstudent,non_sname)--查看索引统计 update statistics schooldb.dbo.tstudent --人工更新表中所有索引的统计 update statistics schooldb.dbo.tstudent non_sname --人工更新表中non_sname索引统计
关于Sql Server的一些知识点的定义总结的更多相关文章
- sql server查询可编程对象定义的方式对比以及整合
本文目录列表: 1.sql server查看可编程对象定义的方式对比 2.整合实现所有可编程对象定义的查看功能的存储dbo.usp_helptext2 3.dbo.helptext2的选择性测试 4. ...
- SQL Server数据库的存储过程中定义的临时表,真的有必要显式删除临时表(drop table #tableName)吗?
本文出处:http://www.cnblogs.com/wy123/p/6704619.html 问题背景 在写SQL Server存储过程中,如果存储过程中定义了临时表,有些人习惯在存储过程结束的时 ...
- Sql Server数据库小知识点总结
把我在开发时候遇到的一点小知识持续更新在这里~ 1.where条件时常变 where UserID='1' 这里的UserID呢,它的值是经常在变化的,有时候要查2,有时候要查3的,有时候要查全部人! ...
- 调试SQL Server的存储过程及用户定义函数
分类: 数据库管理 2005-06-03 13:57 9837人阅读 评论(5) 收藏 举报 sql server存储vb.net服务器sql语言 1.在查询分析器中调试 查询分析器中调试的步骤如下: ...
- sql server 常用小知识点
1. sql server的语法:中文要加 N select * from eVA_EMPBoard where name = N'施纪平' 而oracle的不用 2.
- sql server DDL语句 建立数据库 定义表 修改字段等
一.数据库:1.建立数据库 create database 数据库名;use 数据库名; create database exp1;use exp1; mysql同样 2.删除数据库 drop dat ...
- 关于SQL server的一些知识点
关于怎么打开xp_cmdshell的方法: exec sp_configure 'show advanced option',1reconfiguregoexec sp_configure 'xp_c ...
- Sql server中根据object的定义查找object
SELECT OBJECT_NAME(object_id) FROM sys.sql_modulesWHERE definition LIKE '%keyword to search%' 或者 SEL ...
- SQL Server安全(6/11):执行上下文与代码签名(Execution Context and Code Signing)
在保密你的服务器和数据,防备当前复杂的攻击,SQL Server有你需要的一切.但在你能有效使用这些安全功能前,你需要理解你面对的威胁和一些基本的安全概念.这篇文章提供了基础,因此你可以对SQL Se ...
随机推荐
- 【洛谷P2696】慈善的约瑟夫
题解:根据<具体数学>上关于迭代约瑟夫问题性质的总结如下:多次迭代的约瑟夫问题的解具有循环移位性质,且答案最终会收敛到不动点处. 代码如下 #include<bits/stdc++. ...
- VBA:Double类型与Decimal类型
Sub DataType() For i = 0 To 100 t1 = t1 + 0.1 t2 = t2 + CDec(0.1) Debug.Print "Double=" &a ...
- Redis记录-Redis高级应用
Redis数据库可以使用安全的方案,使得进行连接的任何客户端在执行命令之前都需要进行身份验证.要保护Redis安全,需要在配置文件中设置密码. 示例 下面的示例显示了保护Redis实例的步骤. 127 ...
- POJ 3252 Round Number(数位DP)
Round Numbers Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 6983 Accepted: 2384 Des ...
- TC-572-D1L2 (双向搜索+记忆化)
solution: 这一题是比较难实现的双向搜索题:(字符串+双向搜索+hash记忆化) 我们可以先把K的前半部分枚举出来,并将得出的所有结果和题目给的n个数的每一个数的前半部分都比对一遍,得到它和每 ...
- sql server查询某年某月有多少天
sql语句如下: ),) date from (),,)+'-01' day) t1, ( ) t2 ),) ),,)+'%' 查询结果如下: 2017年2月共有28天,查询出28条记录.
- 移动端点击300ms延迟
转载自:http://www.jianshu.com/p/6e2b68a93c88 一.移动端300ms点击延迟 一般情况下,如果没有经过特殊处理,移动端浏览器在派发点击事件的时候,通常会出现300m ...
- 我们在部署 HTTPS 网站时,该如何选择SSL证书?
我们在部署 HTTPS 网站时,该如何选择SSL证书? 首次部署HTTPS网站的同学对选择什么样的SSL证书多多少少都有点迷茫. 这里考虑的因素确实不少:是否支持多域名.泛域名,价格,信息泄露的保额, ...
- ssh隐藏的sftp功能的使用
sftp是Secure File Transfer Protocol的缩写,安全文件传送协议.可以为传输文件提供一种安全的加密方法.sftp 与 ftp 有着几乎一样的语法和功能.SFTP 为 SSH ...
- Coursera台大机器学习技法课程笔记13-Deep Learning
深度学习面临的问题和现在解决的办法: 简要来说,分两步使用DL:初始化时一层一层的选择权重,而后再进行训练: 那么怎么做pre-training,即怎么选择权重呢?好的权重能够不改变原有资料的信息,即 ...