HEOI2018(九省联考) 题解集合
转载请注明出处:http://www.cnblogs.com/LadyLex/p/8792894.html
今年的省选题目真是赞啊……Day2的题完全不会做……
不过终于卡着校线爬着进了B队
终于改完了题……在这里总结一下这次的题目吧
DAY1
Pro.1 一双木棋
这道题的确是T1难度的题目……
我们考虑这其实是个对抗搜索
已经放好棋子的位置只能是左上角,并且从上到下是不降的
如果我维护了现在已经放了棋子的位置,我就可以知道下一步该谁放,以及哪里可以放了
具体做法……我用11进制压位来着,出题人的做法是用01维护轮廓线
hashmap快的飞起
code:
#include <cstdio>
#include <cstring>
using namespace std;
#define RG register
#define LL long long
#define mod 612497
#define inf 0x3f3f3f3f
struct hash_map
{
struct node{LL state;int next,val;}s[];
int e,adj[mod];
inline void ins(LL state,int val)
{
RG int pos=state%mod;
s[++e].state=state;s[e].val=val;s[e].next=adj[pos];adj[pos]=e;
}
inline int get(LL state)
{
RG int pos=state%mod,i;
for(i=adj[pos];i&&s[i].state!=state;i=s[i].next);
if(!i)return -inf;
return s[i].val;
}
}H;
inline int min(int a,int b){return a<b?a:b;}
inline int max(int a,int b){return a>b?a:b;}
int n,m,A[][],B[][];
LL bin[];
inline int dfs(int l,int r,LL state,int already)
{
if(already==n*m)return ;
int ret=H.get(state);
if(ret!=-inf)return ret;
if(already&)ret=inf;
int last=;
for(RG int i=l;i<=r;++i)
{
int v=(state/bin[i-])%;
if(i!=l&&v==last)continue;
if(already&)ret=min(ret,-B[i][v+]+dfs(l+(v==m-),r,state+bin[i-],already+));
else ret=max(ret,A[i][v+]+dfs(l+(v==m-),r,state+bin[i-],already+));
last=v;
}
if(r<n)
if(already&)ret=min(ret,-B[r+][]+dfs(l,r+,state+bin[r],already+));
else ret=max(ret,A[r+][]+dfs(l,r+,state+bin[r],already+));
H.ins(state,ret);
return ret;
}
int main()
{
RG int i,j;
scanf("%d%d",&n,&m);
for(bin[]=i=;i<=;++i)
bin[i]=bin[i-]*11ll;
for(i=;i<=n;++i)
for(j=;j<=m;++j)
scanf("%d",&A[i][j]);
for(i=;i<=n;++i)
for(j=;j<=m;++j)
scanf("%d",&B[i][j]);
if(m==)
{
int ans=;
for(i=;i<=n;++i)
if(i&)ans+=A[i][];
else ans-=B[i][];
printf("%d\n",ans);
return ;
}
printf("%d\n",A[][]+dfs(,,,));
}
chess
Pro.2 IIIDX
感觉又看到了UR17的滑稽树上滑稽果
出题人给了我这个贪心那他肯定是错的啊
真是见鬼……考场上我用分类讨论打了k=2的部分
但是我们可以考虑像出题人说的那样“换个贪心的思路”
我们不能往第一个节点放最大的元素是因为它的子树里面要有比他更大的对吧
考虑先从大到小排序,按照从1到n的顺序给每个节点填数
那么我们考虑某个节点选的时候,选能选的最大值,然后给他的子树预留一定数量比他大的数
预留的意思是,我们并不知道谁会被用,但是这个范围里面已经有这么多不能用了
我们用线段树维护每个数”比他大的数还有几个可用的“,
每次我们在线段树上查询一个最小的位置x,使得其右面的数的可用个数都大于等于这个节点的子树大小
然后给$[x,n]$区间减去$size[x]-1$
这样为什么是对的?我们不能把任何一个点的可用数量减成负的
因此我们要这样做
而如何查询这个位置呢?我个人维护了线段右端点的值和线段最小值
因为可用位置的序列是一堆不降序列,那么查询的时候,左线段最小值最大的后缀一定是”只选最后一个位置“这个后缀
因此用上面这俩信息就能维护了。
code:
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cmath>
using namespace std;
#define RG register
#define db double
#define N 500010
#define inf 0x3f3f3f3f
char B[<<],*S=B,*T=B;
#define getc (S==T&&(T=(S=B)+fread(B,1,1<<15,stdin),S==T)?0:*S++)
inline int read()
{
RG int x=;RG char c=getc;
while(c<''|c>'')c=getc;
while(c>=''&c<='')x=*x+(c^),c=getc;
return x;
}
inline bool mt(const int &a,const int &b){return a>b;}
struct node
{
node *ch[];int rval,minn,mark;
}*root,mem[N<<];int tot;
inline node* build(int l,int r)
{
node *o=mem+(tot++);
o->rval=r;o->minn=l;
if(l^r)
{
RG int mi=l+r>>;
o->ch[]=build(l,mi);
o->ch[]=build(mi+,r);
}
return o;
}
#define min(a,b) ((a)<(b)?(a):(b))
inline int find(node *&o,int l,int r,int K)
{
if(l==r)return l;
RG int mi=l+r>>,ret;
if(o->mark)
o->ch[]->minn+=o->mark,o->ch[]->rval+=o->mark,o->ch[]->mark+=o->mark,
o->ch[]->minn+=o->mark,o->ch[]->rval+=o->mark,o->ch[]->mark+=o->mark,
o->mark=;
if( min(o->ch[]->rval,o->ch[]->minn) >= K )ret=find(o->ch[],l,mi,K);
else ret=find(o->ch[],mi+,r,K);
o->minn=min(o->ch[]->minn,o->ch[]->minn);
o->rval=o->ch[]->rval;
return ret;
}
inline void add(node *&o,int l,int r,int L,int R,int val)
{
if(L<=l&&r<=R)
{o->minn+=val,o->rval+=val,o->mark+=val;return;}
RG int mi=l+r>>;
if(o->mark)
o->ch[]->minn+=o->mark,o->ch[]->rval+=o->mark,o->ch[]->mark+=o->mark,
o->ch[]->minn+=o->mark,o->ch[]->rval+=o->mark,o->ch[]->mark+=o->mark,
o->mark=;
if(L<=mi)add(o->ch[],l,mi,L,R,val);
if(mi<R)add(o->ch[],mi+,r,L,R,val);
o->minn=min(o->ch[]->minn,o->ch[]->minn);
o->rval=o->ch[]->rval;
}
int n,d[N],size[N],pos[N],fa[N],lst[N];
db k;bool killed[N];
int main()
{
RG int i,j,u,v;
scanf("%d%lf",&n,&k);
for(i=;i<=n;++i)d[i]=read();
for(i=n;i;--i)
++size[i],fa[i]=floor(i/k),size[fa[i]]+=size[i];
sort(d+,d+n+,mt);
for(lst[n]=n,i=n-;i;--i)
lst[i]=(d[i]==d[i+])?lst[i+]:i;
root=build(,n);
killed[]=;
for(i=;i<=n;++i)
{
if(!killed[fa[i]])
add(root,,n,pos[fa[i]],n,size[fa[i]]-),killed[fa[i]]=;
pos[i]=lst[find(root,,n,size[i])];
add(root,,n,pos[i],n,-size[i]);
printf("%d ",d[pos[i]]);
}
}
IIIDX
Pro.3 coat
看来出题人的数据的确造水了……
一开始想了一个$O(n^3)$的做法,就是我们把val>=x的点看成黑点,剩下的是白点
然后我们从大到小枚举x,每次统计黑点大于等于x的联通块数,每次新增的联通块就是新的这个值为K大值的联通块数
我们这样就可以统计答案了对吧
然后我想了几个剪枝
*我们当然要离散,也就是并不统计所有的1~W
*一个显然的剪枝是如果总黑点数小于K,就直接continue
*枚举的时候,每个点的size定义为子树内的黑点数
*我们可以把枚举范围限制为K(大于K的变量我们都加到到K处),这样如果K很小的话我们可以跑的快一点
然后这样复杂度最后就被优化成了$O(nk(n-k))$
事实证明由于出题人的数据水了(n,k接近),所以这个做法在考场上拿了95分
其他省份的同学有用这个做法A题的,事实证明是我实现的细节不优秀,导致常数太大了
正解的做法我实在不敢尝试……不是很懂……
code:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define RG register
#define LL long long
#define mod 64123
#define N 1700
int n,K,e,adj[N],size[N],sta[N],val[N],top;
struct edge{int zhong,next;}s[N<<];
inline void add(int qi,int zhong)
{s[++e].zhong=zhong;s[e].next=adj[qi];adj[qi]=e;}
// inline int min(int a,int b){return a<b?a:b;}
#define min(a,b) ((a)<(b)?(a):(b))
int f[N][N],cnt,can[N];
LL g[N];
inline void dfs(int rt,int fa)
{
RG int i,to,u,v,j,k,lim1,lim2,lim3,lim4;
memset(f[rt],,K+<<);
f[rt][can[rt]]=;
for(i=adj[rt];i;i=s[i].next)
if((to=s[i].zhong)!=fa)
{
dfs(to,rt);
memset(g,,K+<<);
lim1=min(can[rt],K);
lim2=min(can[to],K);
for(j=;j<=lim1;++j)
for(v=;v<=lim2;++v)
g[min(K,j+v)]=g[min(K,j+v)] + (LL)f[rt][j]*f[to][v];
can[rt]+=can[to];
lim1=min(can[rt],K);
for(k=;k<=lim1;++k)f[rt][k]=g[k]%mod;
}
++f[rt][];
if(can[rt]>=K)cnt=(cnt+f[rt][K])%mod;
}
int main()
{
RG int i,j,a,b;
scanf("%d%d%d",&n,&K,&top);
for(i=;i<=n;++i)scanf("%d",&val[i]),sta[i]=val[i];
sort(sta+,sta+n+);
top=unique(sta+,sta+n+)-sta-;
for(i=;i<=n;++i)
val[i]=lower_bound(sta+,sta+top+,val[i])-sta;
for(i=;i<n;++i)
scanf("%d%d",&a,&b),add(a,b),add(b,a);
RG int ans=,last=,tot;
for(i=top;i;--i)
{
tot=;
for(j=;j<=n;++j)
can[j]=(val[j]>=i),tot+=can[j];
if(tot<K)continue;
cnt=;dfs(,);
ans=(ans+(LL)(cnt-last)*sta[i])%mod;
last=cnt;
}
printf("%d\n",(ans+mod)%mod);
}
coat
DAY2
Pro.1 劈配
考试的时候想对了也想错了
我把除了”如何匹配“其他的所有地方都想到了,就是匹配不对……
我们考虑枚举每个人的答案是第几志愿,然后向对应志愿的导师连边
导师就暴力拆成b个点即可
用二分图的增广来判断是否可行
然后第二问就通过二分转成第一问的判断
听起来很清真,但是为什么可以暴力拆成b个点?

code:
#include <cstdio>
#include <cstring>
#include <vector>
using namespace std;
#define RG register
#define N 210
int n,m,C,rk[N][N],lim[N],ned[N],T,vis[N*N],ans[N];
struct edge{int zhong,next;}s[N*N<<];
struct Gragh
{
int e,adj[N],match[N*N];
inline void init()
{
memset(match,,sizeof(match));
memset(adj,,sizeof(adj));e=;
}
inline void add(int qi,int zhong)
{s[++e].zhong=zhong;s[e].next=adj[qi];adj[qi]=e;}
inline bool find(int rt)
{
for(RG int u,i=adj[rt];i;i=s[i].next)
if(vis[u=s[i].zhong]!=T)
{
vis[u]=T;
if(!match[u]||find(match[u]))
{match[u]=rt;return ;}
}
return ;
}
}G,H;
vector<int>tea[N][N];
inline bool check(int rt,int up)
{
H.init();
for(RG int i=;i<=up;++i)
if(ans[i]<=m)
for(vector<int>::iterator it =tea[i][ans[i]].begin();it!=tea[i][ans[i]].end();++it)
for(RG int k=;k<=lim[*it];++k)H.add(i,(*it-)*n+k);
for(RG int i=;i<=up;++i)++T,H.find(i);
RG int cur=H.e;
for(RG int j=;j<=ned[rt];++j)
if(!tea[rt][j].empty())
{
H.e=cur;H.adj[rt]=;++T;
for(vector<int>::iterator it =tea[rt][j].begin();it!=tea[rt][j].end();++it)
for(RG int k=;k<=lim[*it];++k)H.add(rt,(*it-)*n+k);
if(H.find(rt))return true;
}
return false;
}
int main()
{
RG int i,j,t,l,r,mi,fin;
scanf("%d%d",&t,&C);
while(t--)
{
scanf("%d%d",&n,&m);
memset(vis,,sizeof(vis));T=;
for(i=;i<=m;++i)scanf("%d",&lim[i]);
for(i=;i<=n;++i)
for(j=;j<=m;++j)tea[i][j].clear();
for(i=;i<=n;++i)
for(j=;j<=m;++j)
scanf("%d",&rk[i][j]),
tea[i][rk[i][j]].push_back(j);
for(i=;i<=n;++i)scanf("%d",&ned[i]);
RG int cur;
for(G.init(),i=;i<=n;++i)
{
cur=G.e;
for(ans[i]=m+,j=;j<=m;++j)
if(!tea[i][j].empty())
{
G.e=cur;
G.adj[i]=;++T;
for(vector<int>::iterator it =tea[i][j].begin();it!=tea[i][j].end();++it)
for(RG int k=;k<=lim[*it];++k)G.add(i,(*it-)*n+k);
if(G.find(i)){ans[i]=j;break;}
}
}
for(i=;i<=n;++i)printf("%d ",ans[i]);printf("\n");
for(i=;i<=n;++i)
{
if(ans[i]<=ned[i]){printf("0 ");continue;}
l=,r=i-,fin=-;
while(l<=r)
if(check(i,mi=l+r>>))fin=mi,l=mi+;
else r=mi-;
printf("%d ",i--fin);
}printf("\n");
}
}
mentor
Pro.2 林克卡特树
这题的正解似乎是之前遇到过的wqs二分
我们根本不可以发现”删掉K条边“等价于”选取K+1条不相交的链,使其权值和最大“
那么我们就可以写一个dp,数组定义是$f(i,j,0/1/2)$代表i的子树,选了j条链,i的度数为0/1/2
然后用儿子来更新父亲
这个dp细节特别多,可以获得60分
然后我们也不知道怎么就意识到,如果设$ans(x)$为选$x$条链的答案,那么这个$ans()$函数是上凸的
这其实可以理解,随着我们能删的边数变多,我们去掉了更多负权边影响,
但是删的更多后,我们就不得不删掉一些正权边,答案就变小了
这样我们可以用一条直线去卡这个凸包
假如在知道斜率后我们可以计算出这条直线的切点,那么我们通过二分斜率使得这个直线能在横坐标K处与凸包相切我们输出y坐标就行了
怎么算切点?斜率的实际意义相当于每选一条链要额外给答案减去斜率k那么多
这样计算我们得到一个答案$y_{0}$,那么$y_{0}+x*k$就是原来的$ans(x)$
因此我们通过一个$O(n)$的树归求出斜率为k时的切点,然后二分就行了
那个树归其实和贪心比较类似……?
整数二分需要注意一下如何判断边界
code:
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
#define N 300010
#define RG register
#define LL long long
#define inf 0x3f3f3f3f3f3f3f3fll
int n,K,e,adj[N];
struct edge{int zhong,val,next;}s[N<<];
inline void add(int qi,int zhong,int val)
{s[++e].zhong=zhong;s[e].next=adj[qi];adj[qi]=e;s[e].val=val;}
LL sum1[N],sum2[N];
int num1[N],num2[N],sta[N],top,fa[N];
inline void dfs1(int rt,int Vater)
{
sta[++top]=rt;fa[rt]=Vater;
for(RG int u,i=adj[rt],v;i;i=s[i].next)
if((u=s[i].zhong)!=Vater)dfs1(u,rt);
}
inline void check(int val)
{
RG int i,j,rt,u,v;
LL maxsum,secsum,tmpsum;
int maxnum,secnum,tmpnum;
for(j=n;j;--j)
{
rt=sta[j];
num1[rt]=sum1[rt]=;num2[rt]=sum2[rt]=;
maxsum=secsum=;maxnum=secnum=;
for(i=adj[rt];i;i=s[i].next)
if((u=s[i].zhong)!=fa[rt])
{
num1[rt]+=num1[u],sum1[rt]+=sum1[u];
tmpsum=sum2[u]-sum1[u]+s[i].val,tmpnum=num2[u]-num1[u];
if(tmpsum>maxsum||(tmpsum==maxsum&&tmpnum<maxnum))
secsum=maxsum,secnum=maxnum,maxnum=tmpnum,maxsum=tmpsum;
else if(tmpsum>secsum||(tmpsum==secsum&&tmpnum<secnum))
secnum=tmpnum,secsum=tmpsum;
}
num2[rt]=num1[rt]+maxnum;sum2[rt]=sum1[rt]+maxsum;
if(maxsum+secsum>val)
num1[rt]+=maxnum+secnum+,sum1[rt]+=maxsum+secsum-val;
}
}
int main()
{
RG int i,x,a,b,c;
scanf("%d%d",&n,&K);++K;
for(i=;i<n;++i)
scanf("%d%d%d",&a,&b,&c),add(a,b,c),add(b,a,c);
dfs1(,);
int l=-1e9,r=1e9,mi,ans;
while(l<=r)
{
mi=l+r>>;check(mi);
if(num1[]>K)l=mi+;
else ans=mi,r=mi-;
}
check(ans);
printf("%lld\n",sum1[]+(LL)K*ans);
}
lct
Pro.3 制胡窜
垃圾YJQ,毁我青春
这B题考场给我std我都抄不完2333333
我讲个笑话,我在考场上想到了正难则反,并且打出了后缀自动机+倍增+可持久化数据结构
最后打了个$N^{2}Q$暴力
我都佩服我自己
大概经过就是我用上面那堆东西维护了一个right集合
然后就死了,还不如人家kmp选手
那么怎么做呢?
我们考虑正难则反,那就是要维护一些方案数,使得每个字符串内部都有一个端点
让我偷张图
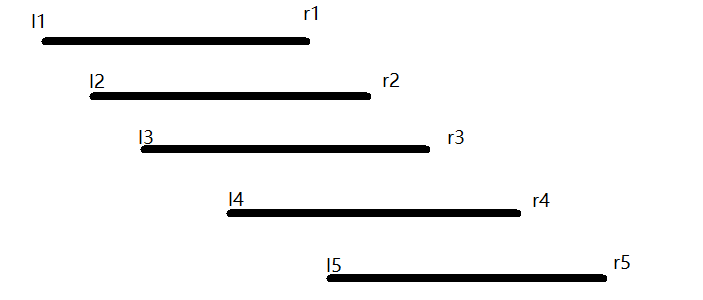
那么,比如我左端点在$(l1,l2)$,那么右端点应该覆盖后面4个串,即应该在$(l5,r2)$
那么写成通式应该是$\sum (r_{i+1}-r_{i})*(r_{i+1}-l_{n})$
我们分别维护$\sum (r_{i+1}-r_{i})*r_{i+1}$以及$\sum (r_{i+1}-r_{i})$
然后就能计算答案了
当然最恶心的地方是边界讨论
第一,可能不存在不合法的情况,这个可以判掉
第二,有的情况可以一个端点完全覆盖所有串,另外一个就可以随便移动了,这个也要统计上
最后,我们最后一个能覆盖的端点的计算不是$(r_{i+1}-r_{i})*(r_{i+1}-l_{n})$,而是$(r_{1}-l_{i})*(r_{i+1}-l_{n})$
code:
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cstdlib>
#include <iostream>
#include <vector>
using namespace std;
#define N 100010
#define inf 0x3f3f3f3f
#define fir first
#define sec second
#define RG register
#define LL long long
struct node
{
int sum1,minn,maxn,size;
LL sum2;
node *ch[];
inline void upd();
}*root[N<<],Mem[N<<],*null;int tot;
char str[N];
int n,q,len,ch[N<<][],parent[N<<],maxn[N<<],sz,last;
inline int newSAM(int l)
{maxn[++sz]=l;root[sz]=null;return sz;}
inline void init()
{
null=new node();
null->ch[]=null->ch[]=null;
null->sum1=null->sum2=;
null->minn=inf,null->maxn=-inf;
last=newSAM();
}
int f[N<<][],bin[];
inline void insert(int d)
{
RG int p=last,np=newSAM(maxn[p]+),q,nq;
for(;p&&!ch[p][d];p=parent[p])ch[p][d]=np;
if(!p)parent[np]=;
else
{
q=ch[p][d];
if(maxn[q]==maxn[p]+)parent[np]=q;
else
{
nq=newSAM(maxn[p]+);memcpy(ch[nq],ch[q],sizeof(ch[q]));
parent[nq]=parent[q],parent[q]=parent[np]=nq;
for(;p&&ch[p][d]==q;p=parent[p])ch[p][d]=nq;
}
}last=np;
}
int deep[N<<],pos[N],e,adj[N<<];
struct edge{int zhong,next;}s[N<<];
inline void add(int qi,int zhong)
{s[++e].zhong=zhong;s[e].next=adj[qi];adj[qi]=e;}
inline void dfs(int rt)
{ RG int i,u;
for(i=;bin[i]<=deep[rt];++i)
f[rt][i]=f[f[rt][i-]][i-];
for(i=adj[rt];i;i=s[i].next)
deep[u=s[i].zhong]=deep[rt]+,
f[u][]=rt,dfs(u);
}
inline int getid(int l,int r)
{ int rt=pos[r];
for(RG int i=;~i;--i)
if(maxn[f[rt][i]]>=len)rt=f[rt][i];
return rt;
}
inline node* newnode()
{
node *o=Mem+(tot++);
o->ch[]=o->ch[]=null;
o->sum1=o->sum2=;o->size=;
return o;
}
inline void node::upd()
{
size=ch[]->size+ch[]->size;
minn=(ch[]==null)?ch[]->minn:ch[]->minn;
maxn=(ch[]==null)?ch[]->maxn:ch[]->maxn;
sum1=maxn-minn;
sum2=ch[]->sum2+ch[]->sum2;
if(ch[]!=null&&ch[]!=null)
sum2+=(LL)ch[]->minn*(ch[]->minn-ch[]->maxn);
}
inline void ins(node *&o,int l,int r,int pos)
{
if(o==null)o=newnode();
o->size=;o->minn=o->maxn=pos;
if(l==r)return;
RG int mi=l+r>>;
if(pos<=mi)ins(o->ch[],l,mi,pos);
else ins(o->ch[],mi+,r,pos);
}
inline void merge(node *&a,node *b)
{
if(a==null){a=b;return;}
if(b==null)return;
merge(a->ch[],b->ch[]);
merge(a->ch[],b->ch[]);
a->upd();
}
#define pll pair<LL,LL>
#define pii pair<int,int>
inline void query_pre(node *o,int l,int r,int pos,pii &q)
{
if(l==r){q.fir=l;++q.sec;return;}
RG int mi=l+r>>;
if(o->ch[]!=null&&o->ch[]->minn<pos)q.sec+=o->ch[]->size,query_pre(o->ch[],mi+,r,pos,q);
else query_pre(o->ch[],l,mi,pos,q);
}
inline void query_nxt(node *o,int l,int r,int pos,pii &q)
{
if(l==r){q.fir=l;--q.sec;return;}
RG int mi=l+r>>;
if(o->ch[]!=null&&o->ch[]->maxn>pos)
q.sec-=o->ch[]->size,query_nxt(o->ch[],l,mi,pos,q);
else query_nxt(o->ch[],mi+,r,pos,q);
}
inline int query_kth(node *o,int l,int r,int k)
{
if(l==r)return l;
return (o->ch[]->size>=k)?query_kth(o->ch[],l,(l+r>>),k):query_kth(o->ch[],(l+r>>)+,r,k-o->ch[]->size);
}
inline void query(node *o,int l,int r,int L,int R,pll &q)
{
if(o==null)return;
if(L<=l&&r<=R)
{q.fir+=o->sum1,q.sec+=o->sum2;return;}
RG int mi=l+r>>;
if(R<=mi)query(o->ch[],l,mi,L,R,q);
else if(mi<L)query(o->ch[],mi+,r,L,R,q);
else
{
if(o->ch[]!=null&&o->ch[]!=null)
{
int v1=o->ch[]->minn-o->ch[]->maxn;
q.fir+=v1,q.sec+=(LL)v1*o->ch[]->minn;
}
query(o->ch[],l,mi,L,R,q);
query(o->ch[],mi+,r,L,R,q);
}
}
struct quest{int len;LL ans;}Q[N*];
vector<int>mem[N<<];
inline LL S(int l,int r){return (LL)(r-l+)*(l+r)/;}
inline void work(int rt)
{
RG int i;
for(i=adj[rt];i;i=s[i].next)
work(s[i].zhong),merge(root[rt],root[s[i].zhong]);
pii Ln,R1;pll ans;
RG int r1=root[rt]->minn,lx,ln;
for(vector<int>::iterator it=mem[rt].begin();it!=mem[rt].end();++it)
{
len=Q[*it].len;
ln=root[rt]->maxn-len+;
if(root[rt]->size==)
{Q[*it].ans-=(LL)(len-)*(ln-)+S(n-r1,n-(ln+));continue;}
R1.sec=,Ln.sec=root[rt]->size+;
query_pre(root[rt],,n,r1+len-,R1);query_nxt(root[rt],,n,ln,Ln);
lx=R1.fir-len+;
if(R1.sec+<Ln.sec)continue;
if(R1.sec+==Ln.sec){Q[*it].ans-=(LL)(r1-lx)*(Ln.fir-ln);continue;}
if(Ln.sec==)
{
Q[*it].ans-=(LL)(r1-len)*(r1-lx)+S(n-r1,n-lx-);
Q[*it].ans-=root[rt]->sum2-(LL)root[rt]->sum1*ln;
}
else
{
Q[*it].ans-=(LL)(r1-lx)*( query_kth(root[rt],,n,R1.sec+)-ln );
if(Ln.sec<=R1.sec)
{
ans.fir=ans.sec=;
query(root[rt],,n,query_kth(root[rt],,n,Ln.sec-),R1.fir,ans);
Q[*it].ans-=ans.sec-ans.fir*ln;
}
}
}
}
int main()
{
RG int i,j,l,r,id;
scanf("%d%d%s",&n,&q,str+);
init();
for(i=;i<=n;++i)
insert(str[i]-''),pos[i]=last,
ins(root[last],,n,i);
for(i=;i<=sz;++i)add(parent[i],i);
for(bin[]=i=;i<=;++i)bin[i]=bin[i-]<<;
deep[]=;dfs();
LL all=(n-1ll)*(n-)/;
for(i=;i<=q;++i)
{
scanf("%d%d",&l,&r);
len=Q[i].len=r-l+,Q[i].ans=all;
mem[getid(l,r)].push_back(i);
}
work();
for(i=;i<=q;++i)printf("%lld\n",Q[i].ans);
}
cutting
总结
这次DAY1的难度还算适中吧……至少不会爆零……
然后DAY2的题目就非常有难度了,然后我就死了
感觉考试的时候,DAY1节奏很好,DAY2由于题目太难,没有适当的放松
然后就比较紧张,可能也影响了思维的活跃度和严密性
以后看到难题之后不要乱了阵脚,慢慢的做,拿好每一档能拿的分数
继续前行吧。
HEOI2018(九省联考) 题解集合的更多相关文章
- [九省联考2018]秘密袭击coat
[九省联考2018]秘密袭击coat 研究半天题解啊... 全网几乎唯一的官方做法的题解:链接 别的都是暴力.... 要是n=3333暴力就完了. 一.问题转化 每个联通块第k大的数,直观统计的话,会 ...
- 【BZOJ5250】[九省联考2018]秘密袭击(动态规划)
[BZOJ5250][九省联考2018]秘密袭击(动态规划) 题面 BZOJ 洛谷 给定一棵树,求其所有联通块的权值第\(k\)大的和. 题解 整个\(O(nk(n-k))\)的暴力剪剪枝就给过了.. ...
- [BZOJ 5252][LOJ 2478][九省联考2018] 林克卡特树
[BZOJ 5252][LOJ 2478][九省联考2018] 林克卡特树 题意 给定一个 \(n\) 个点边带权的无根树, 要求切断其中恰好 \(k\) 条边再连 \(k\) 条边权为 \(0\) ...
- 【BZOJ5248】【九省联考2018】一双木棋(搜索,哈希)
[BZOJ5248][九省联考2018]一双木棋(搜索,哈希) 题面 BZOJ Description 菲菲和牛牛在一块n行m列的棋盘上下棋,菲菲执黑棋先手,牛牛执白棋后手.棋局开始时,棋盘上没有任何 ...
- [luogu] P4364 [九省联考2018]IIIDX(贪心)
P4364 [九省联考2018]IIIDX 题目背景 Osu 听过没?那是Konano 最喜欢的一款音乐游戏,而他的梦想就是有一天自己也能做个独特酷炫的音乐游戏.现在,他在世界知名游戏公司KONMAI ...
- Loj #2479. 「九省联考 2018」制胡窜
Loj #2479. 「九省联考 2018」制胡窜 题目描述 对于一个字符串 \(S\),我们定义 \(|S|\) 表示 \(S\) 的长度. 接着,我们定义 \(S_i\) 表示 \(S\) 中第 ...
- 「九省联考 2018」IIIDX 解题报告
「九省联考 2018」IIIDX 这什么鬼题,送的55分要拿稳,实测有60? 考虑把数值从大到小摆好,每个位置\(i\)维护一个\(f_i\),表示\(i\)左边比它大的(包括自己)还有几个数可以选 ...
- LOJ #2473. 「九省联考 2018」秘密袭击
#2473. 「九省联考 2018」秘密袭击 链接 分析: 首先枚举一个权值W,计算这个多少个连通块中,第k大的数是这个权值. $f[i][j]$表示到第i个节点,有j个大于W数的连通块的个数.然后背 ...
- 洛谷 P4363 [九省联考2018]一双木棋chess 解题报告
P4363 [九省联考2018]一双木棋chess 题目描述 菲菲和牛牛在一块\(n\)行\(m\)列的棋盘上下棋,菲菲执黑棋先手,牛牛执白棋后手. 棋局开始时,棋盘上没有任何棋子,两人轮流在格子上落 ...
随机推荐
- 关于开发React Native的注意事项
今天在写一个简单的RN的Demo时,一连出现了好几个错误,最后幸亏得以解决,在这里把我踩过的坑以及解决办法分享出来: 1.运行出现错误:Could not connect to development ...
- ORACLE官网下载登陆账号能够使用
username: responsecool@sina.com password: abc123ABC http://www.oracle.com/index.html
- Docker:一个装应用的容器
一:简介:你是否经历过“我本地运行没问题啊!““哪个哥们有写死循环了““完了,服务器撑不住了“等等问题,docker就是这么帮你解决问题的工具,它可以帮你把web应用自动化打包和发布,在服务型环境下进 ...
- 1.3《想成为黑客,不知道这些命令行可不行》(Learn Enough Command Line to Be Dangerous)——手册页
我们运行的命令行程序,通常在技术上称作shell, 它包含了一个非常强大(也很神秘)的工具,我们将用它来学习更多可用的命令.这个工具本身就是个称作'man'的命令('manual'的简写).它的参数是 ...
- # 20155218 徐志瀚 EXP7 网络欺诈
20155218 徐志瀚 EXP7 网络欺诈 1. URL攻击 1.在终端中输入命令netstat -tupln |grep 80,查看80端口是否被占用 发现没有被占用: 2.输入指令service ...
- vector 去重
1.使用unique函数: sort(v.begin(),v.end()); v.erase(unique(v.begin(), v.end()), v.end()); //unique()函数将重复 ...
- java 自定义异常输出信息(使用构造器)
throw new Exception("上传的脚本类型不匹配,当前只支持类unix系列的远程扫描,请上传后缀名为 .sh .pl 的脚本文件"); 这样就可以了,结合配置的异常信 ...
- CSS布局的一些技巧
max-width 通常使元素水平居中用的较多的方法为: #main { width: 600px; margin: 0 auto; } 但是,当浏览器窗口比元素的宽度还要窄时,浏览器会显示一个水平滚 ...
- LOJ#6354. 「CodePlus 2018 4 月赛」最短路[最短路优化建图]
题意 一个 \(n\) 个点的完全图,两点之间的边权为 \((i\ xor\ j)*C\) ,同时有 \(m\) 条额外单向路径,问从 \(S\) 到 \(T\) 的最短路. \(n\leq 10^5 ...
- flask_admin 笔记二 授权和权限
权限当然就是让有应该权限的用户能执行某些操作,把没有权限的用户限制在外面.Flask-admin提供了几种方法来处理: 1, Http basic Auth 最简单的身份验证形式是HTTP基本身份验证 ...