python爬虫:抓取下载电影文件,合并ts文件为完整视频
目标网站:https://www.88ys.cc/vod-play-id-58547-src-1-num-1.html 反贪风暴4
对电影进行分析
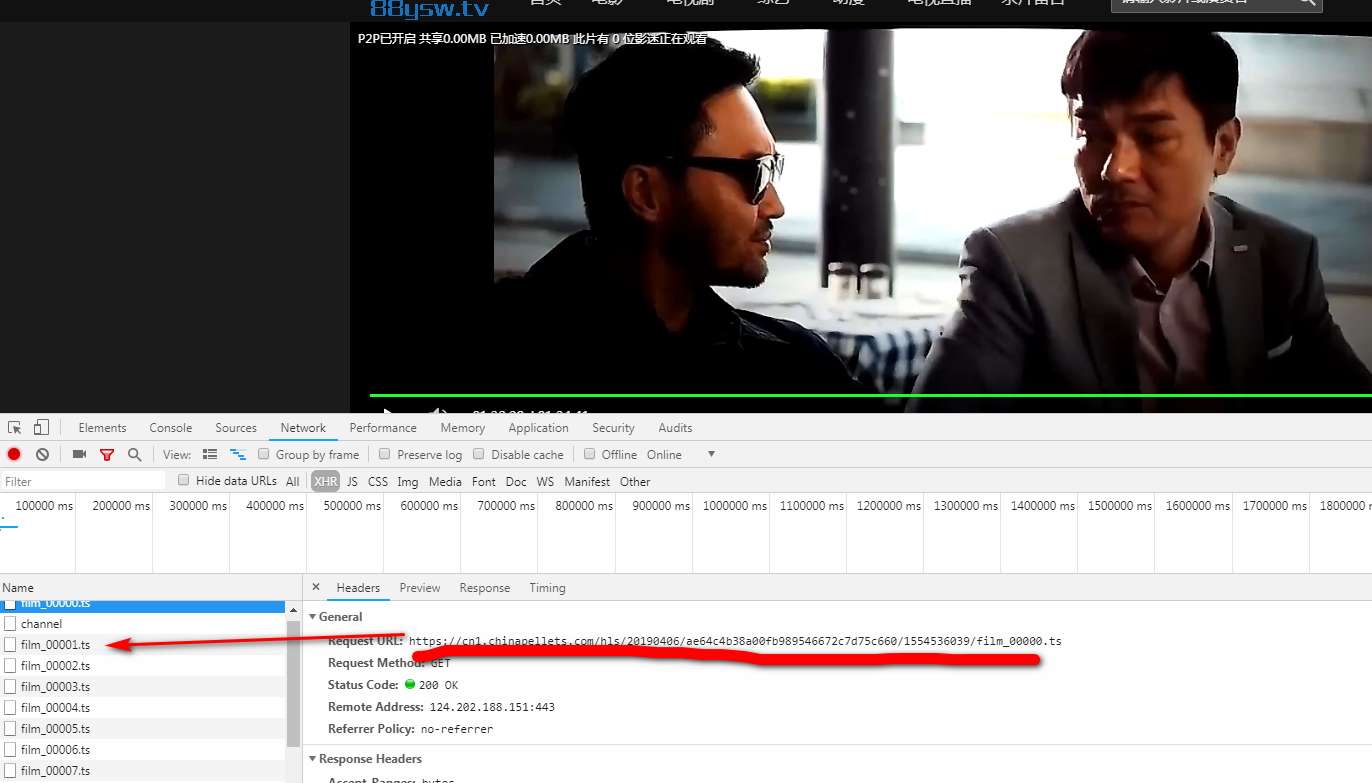
我们发现,电影是按片段一点点加载出来的,我们分别抓取所有ts文件,然后合并成一个完整的文件即可下载到完整电影
代码如下:
# https://www.88ys.cc/vod-play-id-58547-src-1-num-1.html 电影地址
import requests
import os
import time
from multiprocessing import Pool def run(i):
url = 'https://cn1.chinapellets.com/hls/20190406/ae64c4b38a00fb989546672c7d75c660/1554536039/film_0%04d.ts'%i
print("开始下载:"+url)
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"}
r = requests.get(url, headers = headers)
# print(r.content)
with open('./mp4/{}'.format(url[-:]),'wb') as f:
f.write(r.content) def merge(t,cmd):
time.sleep(t)
res=os.popen(cmd)
print(res.read()) if __name__ == '__main__':
# 创建进程池,执行10个任务
pool = Pool()
for i in range():
pool.apply_async(run, (i,)) #执行任务
pool.close()
pool.join()
#调用合并
merge(,"copy /b mp4\\*.ts mp4\\new.mp4")
print('ok!处理完成')
因为单个进程下载太慢了,这里用到了进程池,这样基本达到了,最大网速
运行过程:
下载完成:

python爬虫:抓取下载电影文件,合并ts文件为完整视频的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- 用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件 #coding=utf-8 from ...
- Python Spider 抓取猫眼电影TOP100
""" 抓取猫眼电影TOP100 """ import re import time import requests from bs4 im ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
随机推荐
- PAT甲题题解-1025. PAT Ranking (25)-排序
排序,求整体的排名和局部的排名整体排序,for循环一遍同时存储整体目前的排名和所在局部的排名即可 #include <iostream> #include <cstdio> # ...
- Daily Scrumming* 2015.12.8(Day 1)
一.团队scrum meeting照片 二.今日总结 姓名 WorkItem ID 工作内容 签入链接以及备注说明 江昊 任务942 学习使用github,在github上建立组织并将所有队员纳入, ...
- 剑指offer:包含min函数的栈
题目描述: 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1)). 解题思路: 相当与在保留原栈的同时,去维护一个最小栈.利用一个辅助栈来完成.对于每个 ...
- 05 方法与数组笔记【JAVA】
---恢复内容开始--- 1:方法(掌握) (1)方法:就是完成特定功能的代码块. 注意:在很多语言里面有函数的定义,而在Java中,函数被称为方法. (2)格式: 修饰符 返回值类型 方法名(参数类 ...
- Java认识对象
一.类与对象 java中有基本类型和类类型两个类型系统.Java撰写程序几乎都在使用对象,要产生对象必须先定义类,类是对象的设计图,对象是类的实例 1.定义类 类定义使用的关键词为class,建立实例 ...
- (改进)Python语言实现词频统计
需求: 1.设计一个词频统计的程序. 2.英语文章中包含的英语标点符号不计入统计. 3.将统计结果按照单词的出现频率由大到小进行排序. 设计: 1.基本功能和用法会在程序中进行提示. 2.原理是利用分 ...
- Linux下搭建testlink1.9.17
如果只是要搭建testlink服务的话,建议使用testlink的集成安装包,能避免很多坑 下载地址:https://bitnami.com/stack/testlink/installer 下载好后 ...
- JMeter学习笔记——认识JMeter(1)
拿到一个自动化测试工具,我们第一步就应该了解它能提供我们哪方面的功能(最直接的方法就是从官网获取),接下来就是简单的对这个工具进行“功能测试”了,当然这里的功能测试不是让你找它存在的bug,而是让自己 ...
- [财务知识] debt debit credit 的区别于联系
https://blog.csdn.net/sjpljr/article/details/70169303 剑桥词典解释分别为: Debt [C or U ] n.something, especia ...
- 【设计模式】—— 代理模式Proxy
前言:[模式总览]——————————by xingoo 模式意图 代理模式为其他的对象增加一个代理对象,进行访问控制.从而避免直接访问一个对象,造成效率或者安全性上的降低. 应用场景 1 远程代理, ...