Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统
1.前言
上接 YFCC 100M数据集分析笔记 和 使用百度地图api可视化聚类结果, 在对 YFCC 100M 聚类出的景点信息的基础上,使用 Spark MLlib 提供的 ALS 算法构建推荐模型。
本节代码可见:https://github.com/libaoquan95/TRS/tree/master/Analyse/recommend
数据信息:https://github.com/libaoquan95/TRS/tree/master/Analyse/dataset
2.数据预处理
在用户数据(user.csv) 和 用户-景点数据(user-attraction.csv) 中,用户标识和景点标识都使用了字符串进行表示,但在 Spark MLlib 提供的 ALS 算法中,要求这两者是整数类型,所以首先要对数据进行预处理,将其转化为整数。
对于 userName, 联立 user.csv 和 user-attraction.csv,将 user-attraction.csv 中的 userName 转化为 userId 即可。
对于 provinceId, 可以考虑将其编码,provinceId 格式为 省份标识_省内景点编号,如 HK_100 标识使用在香港拍摄的照片聚类出的第 100 个景点。
编码方式很简单,首先将 _ 前的省份标识转化为数字,之后与 _ 后的数字连接即可。
编码与解码代码如下:
val provinceToCode = Map(
"LN" -> "10",
"ShanX" -> "11",
"ZJ" -> "12",
"CQ" -> "13",
"HLJ" -> "14",
"AH" -> "15",
"SanX" -> "16",
"SD" -> "17",
"SH" -> "18",
"XJ" -> "19",
"HuN" -> "20",
"GS" -> "21",
"HeN" -> "22",
"BJ" -> "23",
"NMG" -> "24",
"YN" -> "25",
"JX" -> "26",
"HuB" -> "27",
"JL" -> "28",
"NX" -> "29",
"TJ" -> "30",
"FJ" -> "31",
"SC" -> "32",
"TW" -> "33",
"GX" -> "34",
"GD" -> "35",
"HeB" -> "36",
"HaiN" -> "37",
"Macro" -> "38",
"XZ" -> "39",
"GZ" -> "40",
"JS" -> "41",
"QH" -> "42",
"HK" -> "43"
)
val codeToProvince = Map(
"10" -> "LN",
"11" -> "ShanX",
"12" -> "ZJ",
"13" -> "CQ",
"14" -> "HLJ",
"15" -> "AH",
"16" -> "SanX",
"17" -> "SD",
"18" -> "SH",
"19" -> "XJ",
"20" -> "HuN",
"21" -> "GS",
"22" -> "HeN",
"23" -> "BJ",
"24" -> "NMG",
"25" -> "YN",
"26" -> "JX",
"27" -> "HuB",
"28" -> "JL",
"29" -> "NX",
"30" -> "TJ",
"31" -> "FJ",
"32" -> "SC",
"33" -> "TW",
"34" -> "GX",
"35" -> "GD",
"36" -> "HeB",
"37" -> "HaiN",
"38" -> "Macro",
"39" -> "XZ",
"40" -> "GZ",
"41" -> "JS",
"42" -> "QH",
"43" -> "HK"
)
// 编码
def codeing(str: String): String = {
var code: String = ""
val Array(province, index) = str.split('_')
code = provinceToCode(province) + index
code
}
// 解码
def decodeing(str: String): String = {
var decode: String = ""
decode = codeToProvince(str(0).toString+str(1).toString) + "_"
for (i <- 1 to str.length-1){
decode += str(i).toString
}
decode
}

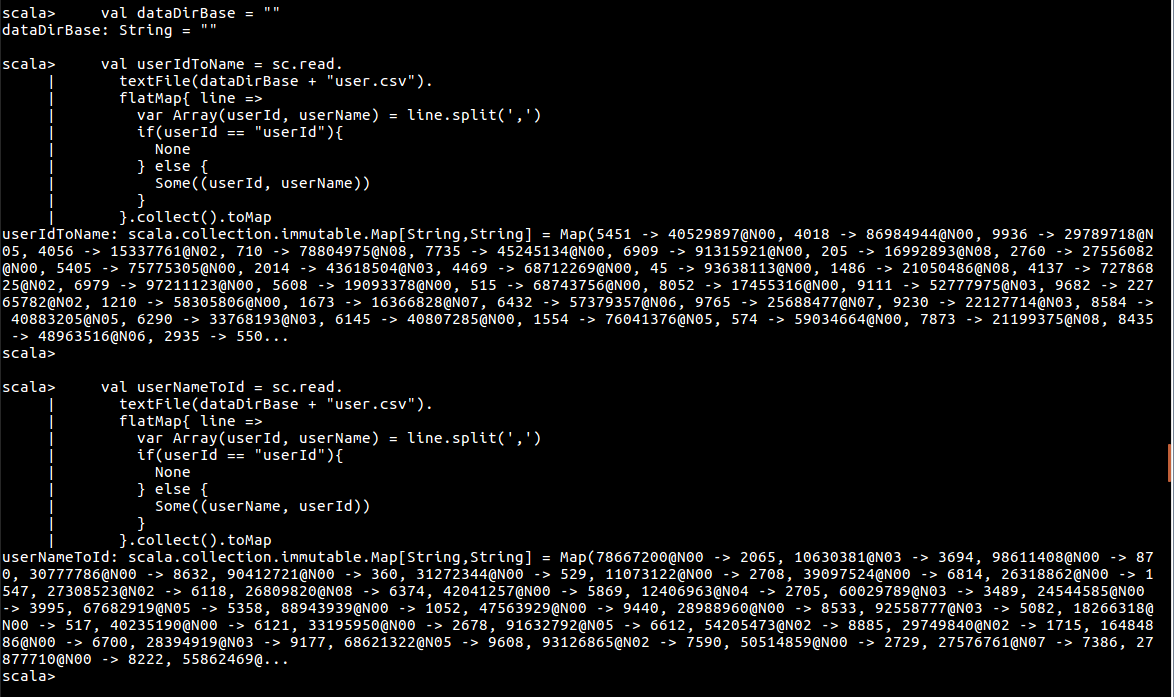
之后加载用户数据 user.scv,并去除头标题。
val dataDirBase = "..\\dataset\\"
val userIdToName = sc.read.
textFile(dataDirBase + "user.csv").
flatMap{ line =>
var Array(userId, userName) = line.split(',')
if(userId == "userId"){
None
} else {
Some((userId, userName))
}
}.collect().toMap
val userNameToId = sc.read.
textFile(dataDirBase + "user.csv").
flatMap{ line =>
var Array(userId, userName) = line.split(',')
if(userId == "userId"){
None
} else {
Some((userName, userId))
}
}.collect().toMap
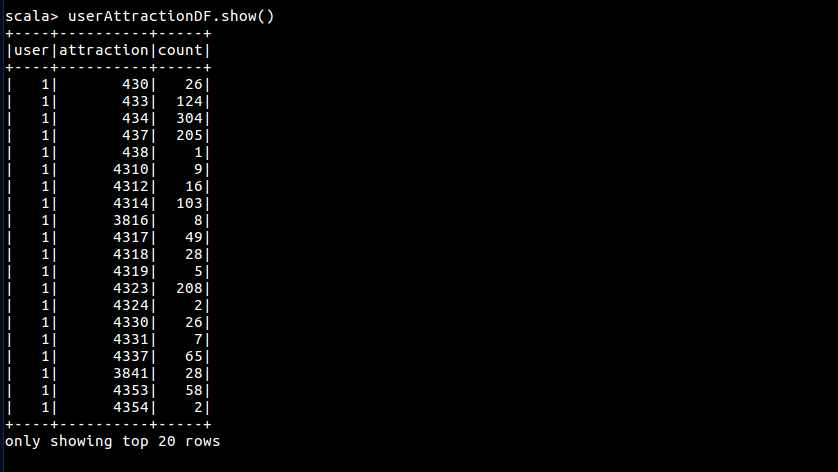
转化 user-attraction 数据
val userAttractionDF = sc.read.
textFile(dataDirBase + "user-attraction.csv").
flatMap{ line =>
val Array(userName, attractionId, count, rating) = line.split(',')
if (userName == "userName"){
None
} else {
Some((userNameToId(userName).toInt, codeing(attractionId).toInt, count.toInt))
}
}.toDF("user", "attraction", "count").cache()
3.建立推荐模型
Spark MLlib ALS 算法接受 三元组矩阵数据,分别代表 用户标识,景点标识,评分数据,其中 用户标识,景点标识 必须是整数。
ALS 是 最小交替二乘 的简称,是使用矩阵分解算法来填补稀疏矩阵,预测评分,具体参见矩阵分解在协同过滤推荐算法中的应用
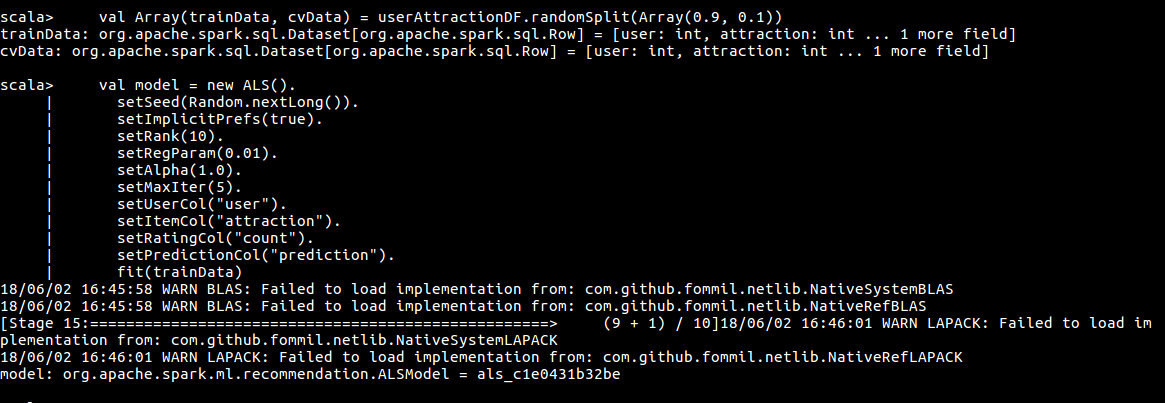
经历过上面的步骤后,userAttractionDF 已经转化为适应 ALS 算法的数据。之后可以建立推荐模型了,将数据拆分为训练集和测试集,使用训练集训练模型。具体算法如下:
val Array(trainData, cvData) = userAttractionDF.randomSplit(Array(0.9, 0.1))
val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(10).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(5).
setUserCol("user").
setItemCol("attraction").
setRatingCol("count").
setPredictionCol("prediction").
fit(trainData)
4.进行推荐
Spark MLlib ALS 一次只能对一个用户进行推荐,代码如下:
def recommendByUser(userId: Int, topN: Int): Array[String] = {
val toRecommend = model.itemFactors.
select($"id".as("attraction")).
withColumn("user", lit(userId))
val topRecommendations = model.transform(toRecommend).
select("attraction", "prediction").
orderBy($"prediction".desc).
limit(topN)
val recommends = topRecommendations.select("attraction").as[Int].collect()
recommends.map(line => decodeing(line.toString))
}
推荐效果如下:

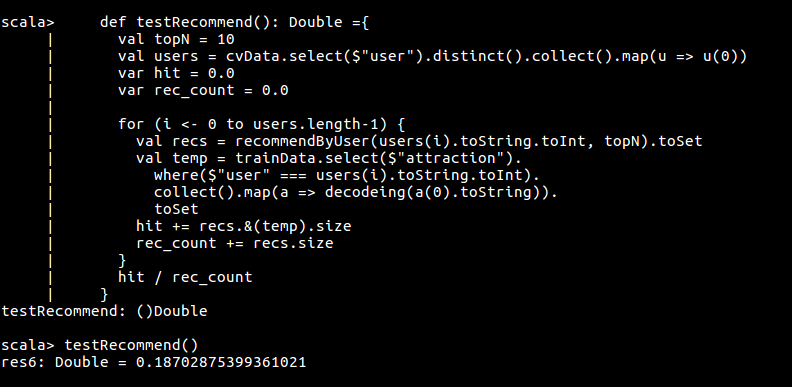
5.评测系统
验证推荐模型的正确率
def testRecommend(): Unit ={
val topN = 10
val users = cvData.select($"user").distinct().collect().map(u => u(0))
var hit = 0.0
var rec_count = 0.0
var test_count = 0.0
for (i <- 0 to users.length-1) {
val recs = recommendByUser(users(i).toString.toInt, topN).toSet
val temp = cvData.select($"attraction").
where($"user" === users(i).toString.toInt).
collect().map(a => decodeing(a(0).toString)).
toSet
hit += recs.&(temp).size
rec_count += recs.size
test_count += temp.size
}
print ("正确率:" + (hit / rec_count))
print ("召回率:" + (hit / test_count))
}
Spark 实践——基于 Spark MLlib 和 YFCC 100M 数据集的景点推荐系统的更多相关文章
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
- YFCC 100M数据集分析笔记
--从YFCC 100M数据集中筛选出Geo信息位于中国的数据集 1.YFCC 100M简介 YFCC 100M数据库是2014年来基于雅虎Flickr的影像数据库.该库由1亿条产生于2004年至20 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 基于Spark Mllib的文本分类
基于Spark Mllib的文本分类 文本分类是一个典型的机器学习问题,其主要目标是通过对已有语料库文本数据训练得到分类模型,进而对新文本进行类别标签的预测.这在很多领域都有现实的应用场景,如新闻网站 ...
- 【spark】spark应用(分布式估算圆周率+基于Spark MLlib的贷款风险预测)
注:本章不涉及spark和scala原理的探讨,详情见其他随笔 一.分布式估算圆周率 计算原理:假设正方形的面积S等于x²,而正方形的内切圆的面积C等于Pi×(x/2)²,因此圆面积与正方形面积之比C ...
- 京东基于Spark的风控系统架构实践和技术细节
京东基于Spark的风控系统架构实践和技术细节 时间 2016-06-02 09:36:32 炼数成金 原文 http://www.dataguru.cn/article-9419-1.html ...
- 基于Spark Mllib,SparkSQL的电影推荐系统
本文测试的Spark版本是1.3.1 本文将在Spark集群上搭建一个简单的小型的电影推荐系统,以为之后的完整项目做铺垫和知识积累 整个系统的工作流程描述如下: 1.某电影网站拥有可观的电影资源和用户 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 基于Spark自动扩展scikit-learn (spark-sklearn)(转载)
转载自:https://blog.csdn.net/sunbow0/article/details/50848719 1.基于Spark自动扩展scikit-learn(spark-sklearn)1 ...
随机推荐
- python第四十二课——__str__(self)函数
4.__str__(self): 作用: 创建完对象,直接打印对象名/引用名我们得到的是对象的内存信息(十六进制的地址信息), 这串数据我们程序员并不关心,我们更希望看到的是属性赋值以后的内容(属性赋 ...
- 宿主在Windows Service中的WCF(创建,安装,调用) (host到exe,非IIS)
1. 创建WCF服务 在vs2010中创建WCF服务应用程序,会自动生成一个接口和一个实现类:(IService1和Service1) IService1接口如下: using System.Ru ...
- pytorch代码资源
pytorch版本的faster和fpn https://github.com/jwyang/faster-rcnn.pytorch https://github.com/jwyang/fpn.pyt ...
- UART, SPI, IIC的详解及三者的区别和联系
UART.SPI.IIC是经常用到的几个数据传输标准,下面分别总结一下: UART(Universal Asynchronous Receive Transmitter):也就是我们经常所说的串口,基 ...
- Waymo在美国推出自动驾驶汽车共享服务
导读 经过数月的测试和数百万英里的无人驾驶汽车技术开发,Waymo 正式在美国推出了具有商业性质的自动驾驶汽车的共享服务. 该公司的 Waymo One 项目将为客户提供 24 小时自动驾驶汽车服务. ...
- JAVA框架Struts2 servlet API
一:servlet API 1)完全解耦接口: 使用ActionContext类进行相关操作: package jd.com.actioncontex; import com.opensymphony ...
- 几个简单易懂的排序算法php
几个简单易懂的排序算法.排序算法,在应用到解决实际问题的时候(由于不一定总是数字排序),重点要分析出什么时候该交换位置. <?php // 冒泡排序 function bubble_sort(a ...
- MapReduce -- TF-IDF
通过MapReduce实现 TF-IDF值的统计 数据:文章ID 文件内容 今天约了姐妹去逛街吃美食,周末玩得很开心啊! ...... ...... 结果数据: 开心:0.28558719539400 ...
- C# 文本转语音朗读
1. 利用DONET框架自带的 SpeechSynthesizer ,缺点是没有感情色彩,抑扬顿挫等. using System; using System.Collections.Generic; ...
- 20155233 《网络对抗》Exp7 网络欺诈技术防范
应用SET工具建立冒名网站 1.要让冒名网站在别的主机上也能看到,需要开启本机的Apache服务,并且要将Apache服务的默认端口改为80,先在kali中使用netstat -tupln |grep ...