Eureka 代码详解
看过之前文章的朋友们,相信已经对Eureka的运行机制已经有了一定的了解。为了更深入的理解它的运作和配置,下面我们结合源码来分别看看服务端和客户端的通信行为是如何实现的。另外写这篇文章,还有一个目的,还是希望鼓励大家能够学会学习和研究的方法,由于目前Spring Cloud的中文资料并不多,并不是大部分的问题都能找到现成的答案,所以其实很多问题给出一个科学而慎重的解答也都是花费研究者不少精力的。
在看具体源码前,我们先回顾一下之前我们所实现的内容,从而找一个合适的切入口去分析。首先,服务注册中心、服务提供者、服务消费者这三个主要元素来说,后两者(也就是Eureka客户端)在整个运行机制中是大部分通信行为的主动发起者,而注册中心主要是处理请求的接收者。所以,我们可以从Eureka的客户端作为入口看看它是如何完成这些主动通信行为的。
我们在将一个普通的Spring Boot应用注册到Eureka Server中,或是从Eureka Server中获取服务列表时,主要就做了两件事:
- 在应用主类中配置了
@EnableDiscoveryClient注解 - 在
application.properties中用eureka.client.serviceUrl.defaultZone参数指定了服务注册中心的位置
顺着上面的线索,我们先查看@EnableDiscoveryClient的源码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
/**
* Annotation to enable a DiscoveryClient implementation.
* @author Spencer Gibb
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Import(EnableDiscoveryClientImportSelector.class)
public @interface EnableDiscoveryClient {
}
|
从该注解的注释我们可以知道:该注解用来开启DiscoveryClient的实例。通过搜索DiscoveryClient,我们可以发现有一个类和一个接口。通过梳理可以得到如下图的关系:
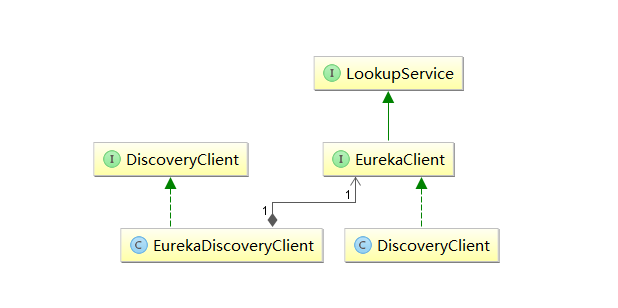
其中,左边的org.springframework.cloud.client.discovery.DiscoveryClient是Spring Cloud的接口,它定义了用来发现服务的常用抽象方法,而org.springframework.cloud.netflix.eureka.EurekaDiscoveryClient是对该接口的实现,从命名来就可以判断,它实现的是对Eureka发现服务的封装。所以EurekaDiscoveryClient依赖了Eureka的com.netflix.discovery.EurekaClient接口,EurekaClient继承了LookupService接口,他们都是Netflix开源包中的内容,它主要定义了针对Eureka的发现服务的抽象方法,而真正实现发现服务的则是Netflix包中的com.netflix.discovery.DiscoveryClient类。
那么,我们就看看来详细看看DiscoveryClient类。先解读一下该类头部的注释有个总体的了解,注释的大致内容如下:
|
1
2
3
4
5
6
7
8
9
|
这个类用于帮助与Eureka Server互相协作。
Eureka Client负责了下面的任务:
- 向Eureka Server注册服务实例
- 向Eureka Server为租约续期
- 当服务关闭期间,向Eureka Server取消租约
- 查询Eureka Server中的服务实例列表
Eureka Client还需要配置一个Eureka Server的URL列表。
|
在具体研究Eureka Client具体负责的任务之前,我们先看看对Eureka Server的URL列表配置在哪里。根据我们配置的属性名:eureka.client.serviceUrl.defaultZone,通过serviceUrl我们找到该属性相关的加载属性,但是在SR5版本中它们都被@Deprecated标注了,并在注视中可以看到@link到了替代类com.netflix.discovery.endpoint.EndpointUtils,我们可以在该类中找到下面这个函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public static Map<String, List<String>> getServiceUrlsMapFromConfig(
EurekaClientConfig clientConfig, String instanceZone, boolean preferSameZone) {
Map<String, List<String>> orderedUrls = new LinkedHashMap<>();
String region = getRegion(clientConfig);
String[] availZones = clientConfig.getAvailabilityZones(clientConfig.getRegion());
if (availZones == null || availZones.length == 0) {
availZones = new String[1];
availZones[0] = DEFAULT_ZONE;
}
……
int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
String zone = availZones[myZoneOffset];
List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(zone);
if (serviceUrls != null) {
orderedUrls.put(zone, serviceUrls);
}
……
return orderedUrls;
}
|
Region、Zone
在上面的函数中,我们可以发现客户端依次加载了两个内容,第一个是Region,第二个是Zone,从其加载逻上我们可以判断他们之间的关系:
- 通过
getRegion函数,我们可以看到它从配置中读取了一个Region返回,所以一个微服务应用只可以属于一个Region,如果不特别配置,就默认为default。若我们要自己设置,可以通过eureka.client.region属性来定义。
|
1
2
3
4
5
6
7
8
|
public static String getRegion(EurekaClientConfig clientConfig) {
String region = clientConfig.getRegion();
if (region == null) {
region = DEFAULT_REGION;
}
region = region.trim().toLowerCase();
return region;
}
|
- 通过
getAvailabilityZones函数,我们可以知道当我们没有特别为Region配置Zone的时候,将默认采用defaultZone,这也是我们之前配置参数eureka.client.serviceUrl.defaultZone的由来。若要为应用指定Zone,我们可以通过eureka.client.availability-zones属性来进行设置。从该函数的return内容,我们可以Zone是可以有多个的,并且通过逗号分隔来配置。由此,我们可以判断Region与Zone是一对多的关系。
|
1
2
3
4
5
6
7
|
public String[] getAvailabilityZones(String region) {
String value = this.availabilityZones.get(region);
if (value == null) {
value = DEFAULT_ZONE;
}
return value.split(",");
}
|
ServiceUrls
在获取了Region和Zone信息之后,才开始真正加载Eureka Server的具体地址。它根据传入的参数按一定算法确定加载位于哪一个Zone配置的serviceUrls。
|
1
2
3
|
int myZoneOffset = getZoneOffset(instanceZone, preferSameZone, availZones);
String zone = availZones[myZoneOffset];
List<String> serviceUrls = clientConfig.getEurekaServerServiceUrls(zone);
|
具体获取serviceUrls的实现,我们可以详细查看getEurekaServerServiceUrls函数的具体实现类EurekaClientConfigBean,该类是EurekaClientConfig和EurekaConstants接口的实现,用来加载配置文件中的内容,这里有非常多有用的信息,这里我们先说一下此处我们关心的,关于defaultZone的信息。通过搜索defaultZone,我们可以很容易的找到下面这个函数,它具体实现了,如何解析该参数的过程,通过此内容,我们就可以知道,eureka.client.serviceUrl.defaultZone属性可以配置多个,并且需要通过逗号分隔。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public List<String> getEurekaServerServiceUrls(String myZone) {
String serviceUrls = this.serviceUrl.get(myZone);
if (serviceUrls == null || serviceUrls.isEmpty()) {
serviceUrls = this.serviceUrl.get(DEFAULT_ZONE);
}
if (!StringUtils.isEmpty(serviceUrls)) {
final String[] serviceUrlsSplit = StringUtils.commaDelimitedListToStringArray(serviceUrls);
List<String> eurekaServiceUrls = new ArrayList<>(serviceUrlsSplit.length);
for (String eurekaServiceUrl : serviceUrlsSplit) {
if (!endsWithSlash(eurekaServiceUrl)) {
eurekaServiceUrl += "/";
}
eurekaServiceUrls.add(eurekaServiceUrl);
}
return eurekaServiceUrls;
}
return new ArrayList<>();
}
|
当客户端在服务列表中选择实例进行访问时,对于Zone和Region遵循这样的规则:优先访问同自己一个Zone中的实例,其次才访问其他Zone中的实例。通过Region和Zone的两层级别定义,配合实际部署的物理结构,我们就可以有效的设计出区域性故障的容错集群。
服务注册
在理解了多个服务注册中心信息的加载后,我们再回头看看DiscoveryClient类是如何实现“服务注册”行为的,通过查看它的构造类,可以找到它调用了下面这个函数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
private void initScheduledTasks() {
...
if (clientConfig.shouldRegisterWithEureka()) {
...
// InstanceInfo replicator
instanceInfoReplicator = new InstanceInfoReplicator(
this,
instanceInfo,
clientConfig.getInstanceInfoReplicationIntervalSeconds(),
2); // burstSize
...
instanceInfoReplicator.start(clientConfig.getInitialInstanceInfoReplicationIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}
|
在上面的函数中,我们可以看到关键的判断依据if (clientConfig.shouldRegisterWithEureka())。在该分支内,创建了一个InstanceInfoReplicator类的实例,它会执行一个定时任务,查看该类的run()函数了解该任务做了什么工作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public void run() {
try {
discoveryClient.refreshInstanceInfo();
Long dirtyTimestamp = instanceInfo.isDirtyWithTime();
if (dirtyTimestamp != null) {
discoveryClient.register();
instanceInfo.unsetIsDirty(dirtyTimestamp);
}
} catch (Throwable t) {
logger.warn("There was a problem with the instance info replicator", t);
} finally {
Future next = scheduler.schedule(this, replicationIntervalSeconds, TimeUnit.SECONDS);
scheduledPeriodicRef.set(next);
}
}
|
相信大家都发现了discoveryClient.register();这一行,真正触发调用注册的地方就在这里。继续查看register()的实现内容如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
boolean register() throws Throwable {
logger.info(PREFIX + appPathIdentifier + ": registering service...");
EurekaHttpResponse<Void> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
} catch (Exception e) {
logger.warn("{} - registration failed {}", PREFIX + appPathIdentifier, e.getMessage(), e);
throw e;
}
if (logger.isInfoEnabled()) {
logger.info("{} - registration status: {}", PREFIX + appPathIdentifier, httpResponse.getStatusCode());
}
return httpResponse.getStatusCode() == 204;
}
|
通过属性命名,大家基本也能猜出来,注册操作也是通过REST请求的方式进行的。同时,这里我们也能看到发起注册请求的时候,传入了一个com.netflix.appinfo.InstanceInfo对象,该对象就是注册时候客户端给服务端的服务的元数据。
服务获取与服务续约
顺着上面的思路,我们继续来看DiscoveryClient的initScheduledTasks函数,不难发现在其中还有两个定时任务,分别是“服务获取”和“服务续约”:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
private void initScheduledTasks() {
if (clientConfig.shouldFetchRegistry()) {
// registry cache refresh timer
int registryFetchIntervalSeconds = clientConfig.getRegistryFetchIntervalSeconds();
int expBackOffBound = clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
scheduler.schedule(
new TimedSupervisorTask(
"cacheRefresh",
scheduler,
cacheRefreshExecutor,
registryFetchIntervalSeconds,
TimeUnit.SECONDS,
expBackOffBound,
new CacheRefreshThread()
),
registryFetchIntervalSeconds, TimeUnit.SECONDS);
}
if (clientConfig.shouldRegisterWithEureka()) {
int renewalIntervalInSecs = instanceInfo.getLeaseInfo().getRenewalIntervalInSecs();
int expBackOffBound = clientConfig.getHeartbeatExecutorExponentialBackOffBound();
logger.info("Starting heartbeat executor: " + "renew interval is: " + renewalIntervalInSecs);
// Heartbeat timer
scheduler.schedule(
new TimedSupervisorTask(
"heartbeat",
scheduler,
heartbeatExecutor,
renewalIntervalInSecs,
TimeUnit.SECONDS,
expBackOffBound,
new HeartbeatThread()
),
renewalIntervalInSecs, TimeUnit.SECONDS);
// InstanceInfo replicator
……
}
}
|
从源码中,我们就可以发现,“服务获取”相对于“服务续约”更为独立,“服务续约”与“服务注册”在同一个if逻辑中,这个不难理解,服务注册到Eureka Server后,自然需要一个心跳去续约,防止被剔除,所以他们肯定是成对出现的。从源码中,我们可以清楚看到了,对于服务续约相关的时间控制参数:
|
1
2
|
eureka.instance.lease-renewal-interval-in-seconds=30
eureka.instance.lease-expiration-duration-in-seconds=90
|
而“服务获取”的逻辑在独立的一个if判断中,其判断依据就是我们之前所提到的eureka.client.fetch-registry=true参数,它默认是为true的,大部分情况下我们不需要关心。为了定期的更新客户端的服务清单,以保证服务访问的正确性,“服务获取”的请求不会只限于服务启动,而是一个定时执行的任务,从源码中我们可以看到任务运行中的registryFetchIntervalSeconds参数对应eureka.client.registry-fetch-interval-seconds=30配置参数,它默认为30秒。
继续循序渐进的向下深入,我们就能分别发现实现“服务获取”和“服务续约”的具体方法,其中“服务续约”的实现较为简单,直接以REST请求的方式进行续约:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
boolean renew() {
EurekaHttpResponse<InstanceInfo> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.sendHeartBeat(instanceInfo.getAppName(), instanceInfo.getId(), instanceInfo, null);
logger.debug("{} - Heartbeat status: {}", PREFIX + appPathIdentifier, httpResponse.getStatusCode());
if (httpResponse.getStatusCode() == 404) {
REREGISTER_COUNTER.increment();
logger.info("{} - Re-registering apps/{}", PREFIX + appPathIdentifier, instanceInfo.getAppName());
return register();
}
return httpResponse.getStatusCode() == 200;
} catch (Throwable e) {
logger.error("{} - was unable to send heartbeat!", PREFIX + appPathIdentifier, e);
return false;
}
}
|
而“服务获取”则相对复杂一些,会根据是否第一次获取发起不同的REST请求和相应的处理,具体的实现逻辑还是跟之前类似,有兴趣的读者可以继续查看服务客户端的其他具体内容,了解更多细节。
服务注册中心处理
通过上面的源码分析,可以看到所有的交互都是通过REST的请求来发起的。下面我们来看看服务注册中心对这些请求的处理。Eureka Server对于各类REST请求的定义都位于:com.netflix.eureka.resources包下。
以“服务注册”请求为例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info,
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
logger.debug("Registering instance {} (replication={})", info.getId(), isReplication);
// validate that the instanceinfo contains all the necessary required fields
...
// handle cases where clients may be registering with bad DataCenterInfo with missing data
DataCenterInfo dataCenterInfo = info.getDataCenterInfo();
if (dataCenterInfo instanceof UniqueIdentifier) {
String dataCenterInfoId = ((UniqueIdentifier) dataCenterInfo).getId();
if (isBlank(dataCenterInfoId)) {
boolean experimental = "true".equalsIgnoreCase(
serverConfig.getExperimental("registration.validation.dataCenterInfoId"));
if (experimental) {
String entity = "DataCenterInfo of type " + dataCenterInfo.getClass()
+ " must contain a valid id";
return Response.status(400).entity(entity).build();
} else if (dataCenterInfo instanceof AmazonInfo) {
AmazonInfo amazonInfo = (AmazonInfo) dataCenterInfo;
String effectiveId = amazonInfo.get(AmazonInfo.MetaDataKey.instanceId);
if (effectiveId == null) {
amazonInfo.getMetadata().put(
AmazonInfo.MetaDataKey.instanceId.getName(), info.getId());
}
} else {
logger.warn("Registering DataCenterInfo of type {} without an appropriate id",
dataCenterInfo.getClass());
}
}
}
registry.register(info, "true".equals(isReplication));
return Response.status(204).build(); // 204 to be backwards compatible
}
|
在对注册信息进行了一大堆校验之后,会调用org.springframework.cloud.netflix.eureka.server.InstanceRegistry对象中的register(InstanceInfo info, int leaseDuration, boolean isReplication)函数来进行服务注册:
|
1
2
3
4
5
6
7
8
9
10
11
|
public void register(InstanceInfo info, int leaseDuration, boolean isReplication) {
if (log.isDebugEnabled()) {
log.debug("register " + info.getAppName() + ", vip " + info.getVIPAddress()
+ ", leaseDuration " + leaseDuration + ", isReplication "
+ isReplication);
}
this.ctxt.publishEvent(new EurekaInstanceRegisteredEvent(this, info,
leaseDuration, isReplication));
super.register(info, leaseDuration, isReplication);
}
|
在注册函数中,先调用publishEvent函数,将该新服务注册的事件传播出去,然后调用com.netflix.eureka.registry.AbstractInstanceRegistry父类中的注册实现,将InstanceInfo中的元数据信息存储在一个ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>对象中,它是一个两层Map结构,第一层的key存储服务名:InstanceInfo中的appName属性,第二层的key存储实例名:InstanceInfo中的instanceId属性。
服务端的请求接收都非常类似,对于其他的服务端处理,这里就不再展开,读者可以根据上面的脉络来自己查看其内容(这里包含很多细节内容)来帮助和加深理解。
Eureka 代码详解的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- ASP.NET MVC 5 学习教程:生成的代码详解
原文 ASP.NET MVC 5 学习教程:生成的代码详解 起飞网 ASP.NET MVC 5 学习教程目录: 添加控制器 添加视图 修改视图和布局页 控制器传递数据给视图 添加模型 创建连接字符串 ...
- Github-karpathy/char-rnn代码详解
Github-karpathy/char-rnn代码详解 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2016-1-10 ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- JAVA类与类之间的全部关系简述+代码详解
本文转自: https://blog.csdn.net/wq6ylg08/article/details/81092056类和类之间关系包括了 is a,has a, use a三种关系(1)is a ...
- Java中String的intern方法,javap&cfr.jar反编译,javap反编译后二进制指令代码详解,Java8常量池的位置
一个例子 public class TestString{ public static void main(String[] args){ String a = "a"; Stri ...
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- 基础 | batchnorm原理及代码详解
https://blog.csdn.net/qq_25737169/article/details/79048516 https://www.cnblogs.com/bonelee/p/8528722 ...
- 非极大值抑制(NMS,Non-Maximum Suppression)的原理与代码详解
1.NMS的原理 NMS(Non-Maximum Suppression)算法本质是搜索局部极大值,抑制非极大值元素.NMS就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的b ...
随机推荐
- JSP&Servlet(转)
第一篇:Web应用基础1.概念: 1.1应用程序分类 a.桌面应用程序:一般是指采用client/server即客户机/服务器结构的应用程序. b.web应用程序:一般是指采用Bro ...
- Ruby操作数据库基本步骤
1.rails g model university name:string 2.model has_many :colleges belongs_to :university has_one :us ...
- Java互斥语义的实现
锁 对象头(Object Header) HotSpot 虚拟机的对象头包括两部分信息:Mark Word(标记字段)和 Klass Pointer(类型指针) Mark Word 用于存储对象自 ...
- 《锋利的jQuery》打造个性网站整合
搜索框文字效果 网页换肤 导航效果 广告效果 添加超链接提示 产品横向滚动效果 光标滑动列表效果 产品详细页面效果(放大镜,遮罩,选项卡,评分等) 1.搜索框文字效果 <!DOCTYPE htm ...
- Linux系统资源查看与设置
/proc/sys/fs/file-max = 65536 /proc/sys/net/ipv4/tcp_fin_timeout = 15 /proc/sys/net/ipv4/tcp_tw_recy ...
- 《CSS权威指南(第三版)》---第五章 字体
这章主要的内容有: 1.字体:一般使用一种通用的字体. 2.字体加粗:一般从数字100 -900 . 3.字体大小:font-size 4.拉伸和调整字体:font-stretch 5.调整字体大小: ...
- Cocos2d-x中单例的使用
大家都知道一个程序中只有一个导演类,eg: CCDirector *pDirectory = CCDirector::sharedDirector();//初始化导演类. 可通过 pDirectory ...
- Scrapy,终端startproject,显示错误TimeoutError: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
F:\python_project\test>scrapy startproject spz Traceback (most recent call last): File "d:\p ...
- BZOJ1382:[Baltic2001]Mars Maps
浅谈树状数组与线段树:https://www.cnblogs.com/AKMer/p/9946944.html 题目传送门:https://www.lydsy.com/JudgeOnline/prob ...
- DataGrid 滚动特定的行或者列
DataGrid 滚动特定的行或者列. DataGrid.ScrollIntoView Method (Object, DataGridColumn) .NET Framework 4.5 Silve ...