scrapy的中间件Downloader Middleware实现User-Agent随机切换
scrapy的中间件Download Middleware实现User-Agent随机切换
总架构理解Middleware
通过scrapy官网最新的架构图来理解:
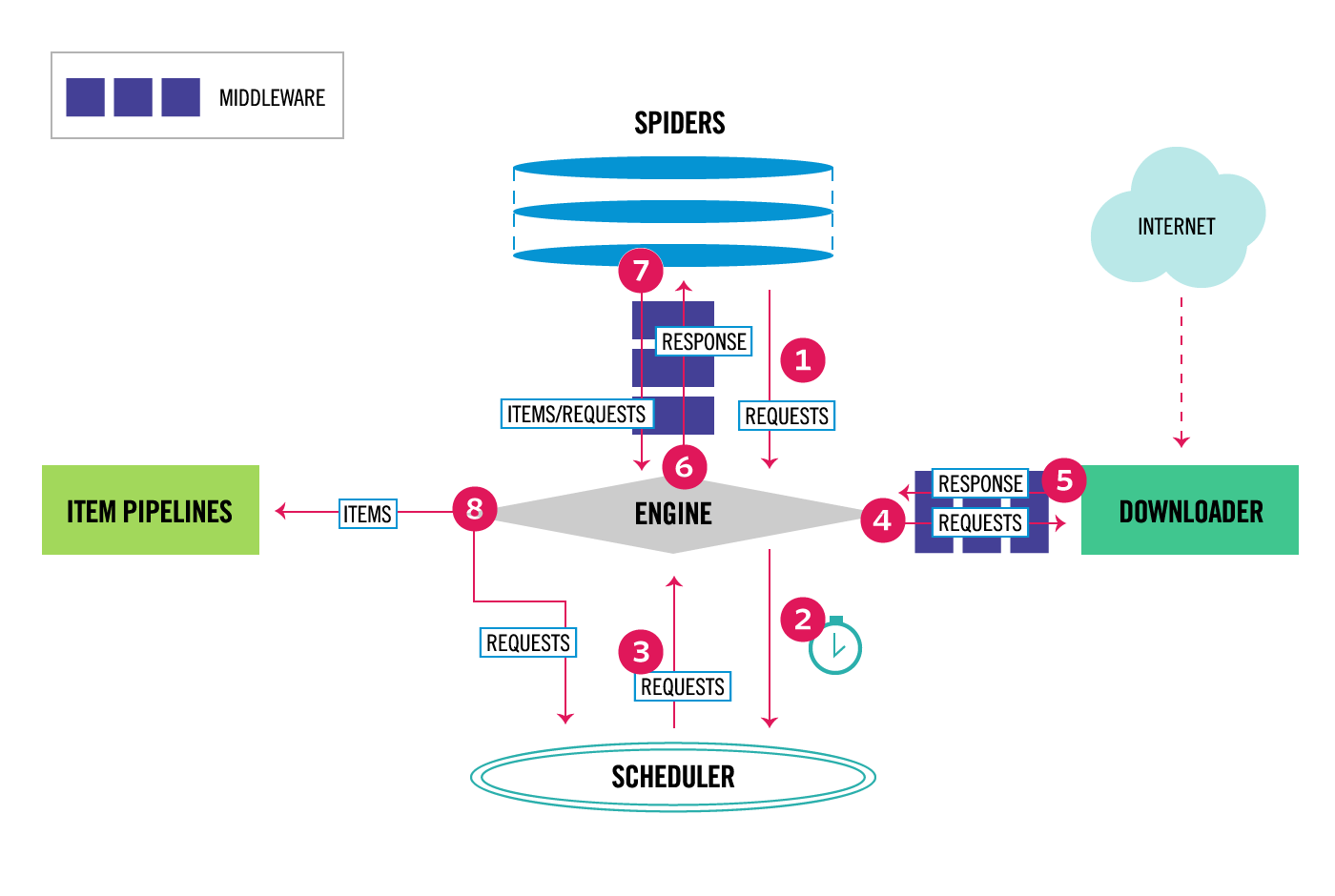
从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可以设置中间件,两者是双向的,并且是可以设置多层.
如何实现随机更换User-Agent
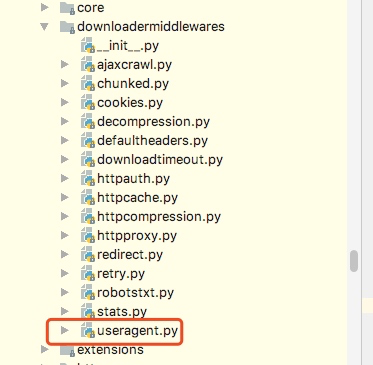
这里要做的是通过自己在Downlaoder Middleware中定义一个类来实现随机更换User-Agent,但是我们需要知道的是scrapy其实本身提供了一个user-agent这个我们在源码中可以看到如下图:
from scrapy import signals
class UserAgentMiddleware(object):
"""This middleware allows spiders to override the user_agent""" def __init__(self, user_agent='Scrapy'):
self.user_agent = user_agent @classmethod
def from_crawler(cls, crawler):
o = cls(crawler.settings['USER_AGENT'])
crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
return o def spider_opened(self, spider):
self.user_agent = getattr(spider, 'user_agent', self.user_agent) def process_request(self, request, spider):
if self.user_agent:
request.headers.setdefault(b'User-Agent', self.user_agent)
从源代码中可以知道,默认scrapy的user_agent=‘Scrapy’,并且这里在这个类里有一个类方法from_crawler会从settings里获取USER_AGENT这个配置,如果settings配置文件中没有配置,则会采用默认的Scrapy,process_request方法会在请求头中设置User-Agent.
关于随机切换User-Agent的库
github地址为:https://github.com/hellysmile/fake-useragent
安装:pip install fake-useragent
基本的使用例子:
from fake_useragent import UserAgent ua = UserAgent() print(ua.ie)
print(ua.chrome)
print(ua.Firefox)
print(ua.random)
print(ua.random)
print(ua.random)
这里可以获取我们想要的常用的User-Agent,并且这里提供了一个random方法可以直接随机获取,上述代码的结果为:

关于配置和代码
这里我找了一个之前写好的爬虫,然后实现随机更换User-Agent,在settings配置文件如下:
DOWNLOADER_MIDDLEWARES = {
'jobboleSpider.middlewares.RandomUserAgentMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
RANDOM_UA_TYPE= 'random'
这里我们要将系统的UserAgent中间件设置为None,这样就不会启用,否则默认系统的这个中间会被启用
定义RANDOM_UA_TYPE这个是设置一个默认的值,如果这里不设置我们会在代码中进行设置,在middleares.py中添加如下代码:
class RandomUserAgentMiddleware(object):
'''
随机更换User-Agent
'''
def __init__(self,crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random') @classmethod
def from_crawler(cls,crawler):
return cls(crawler) def process_request(self,request,spider): def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault('User-Agent',get_ua())
上述代码的一个简单分析描述:
1. 通过crawler.settings.get来获取配置文件中的配置,如果没有配置则默认是random,如果配置了ie或者chrome等就会获取到相应的配置
2. 在process_request方法中我们嵌套了一个get_ua方法,get_ua其实就是为了执行ua.ua_type,但是这里无法使用self.ua.self.us_type,所以利用了getattr方法来直接获取,最后通过request.heasers.setdefault来设置User-Agent
scrapy的中间件Downloader Middleware实现User-Agent随机切换的更多相关文章
- Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- 爬虫--Scrapy之Downloader Middleware
下载器中间件(Downloader Middleware) 下载器中间件是介于Scrapy的request/response处理的钩子框架. 是用于全局修改Scrapy request和respons ...
- scrapy之中间件
中间件的简介 1.中间件的作用 在scrapy运行的整个过程中,对scrapy框架运行的某些步骤做一些适配自己项目的动作. 例如scrapy内置的HttpErrorMiddleware,可以在http ...
- 第十九节:Scrapy爬虫框架之Middleware文件详解
# -*- coding: utf-8 -*- # 在这里定义蜘蛛中间件的模型# Define here the models for your spider middleware## See doc ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy框架——介绍、安装、命令行创建,启动、项目目录结构介绍、Spiders文件夹详解(包括去重规则)、Selectors解析页面、Items、pipelines(自定义pipeline)、下载中间件(Downloader Middleware)、爬虫中间件、信号
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- Scrapy框架学习(三)Spider、Downloader Middleware、Spider Middleware、Item Pipeline的用法
Spider有以下属性: Spider属性 name 爬虫名称,定义Spider名字的字符串,必须是唯一的.常见的命名方法是以爬取网站的域名来命名,比如爬取baidu.com,那就将Spider的名字 ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- Shell中括号的作用
Shell中括号的作用 作者:Danbo 时间:2015-8-7 单小括号() ①.命令组.括号中的命令将会断开一个子Shell顺序执行,所以括号中的变量不能被脚本余下的部分使用.括号中多个命令之间用 ...
- 升级python到最新2.7.13
python2.7是2.X的最后一个版本,同时也加入了一部分3.X的新特性.并且具有更好的性能,修改多个bug.所以决定升级到最新的2.7版,我的目前的版本是2.6.6 查看当前python版本 # ...
- Codeforces Round #304 (Div. 2) C. Soldier and Cards —— 模拟题,队列
题目链接:http://codeforces.com/problemset/problem/546/C 题解: 用两个队列模拟过程就可以了. 特殊的地方是:1.如果等大,那么两张牌都丢弃 : 2.如果 ...
- Java 线程转储
软件维护是一个枯燥而又有挑战性的工作.只要软件功能符合预期,那么这个工作就是好的.设想一个这样的情景,你的电话半夜也一直在响(这不是一个令人愉快的感受,是吧?)任何软件系统,无论它当初是被设计的多好, ...
- zoj 2316 Matrix Multiplication 解题报告
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2316 题目意思:有 N 个 点,M 条 边.需要构造一个N * ...
- linux系统配置之bash shell的配置(centos)
linux系统开机启动过程的最后阶段会由init进程根据启动方案(运行级:0-6)启动许多基本的服务程序,为用户提供各种各样的服务.在启动这些服务的最后会启动一个为用户提供操作环境的服务,用户就是通过 ...
- Rsync+Inotify同步
rsync服务安装与<rsync+sersync同步>环境一样! 安装inotify-tools 在源服务器10.10.2.191上操作: 1.查看服务器内核是否支持inotify ll ...
- cogs1070玻璃球游戏
1070. [焦作一中2012] 玻璃球游戏 ★ 输入文件:marbles.in 输出文件:marbles.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述] 小x ...
- oracle获取一段时间内所有的小时、天、月
获取一段时间内所有的小时 ) sdate FROM dual CONNECT ; 获取一段时间内所有的天 sdate FROM dual CONNECT ; from user_objects whe ...
- Day01:Python入门
一.编程与编程语言 编程的目的是将人类的思想流程按照某种能够被计算机识别的表达方式传递给计算机,从而让计算机能像人脑一样自动执行工作. 能被计算机所识别的表达方式是编程语言,python就是一门编程语 ...