搜索入门之dfs--经典的迷宫问题解析
今天来谈一下dfs的入门,以前看到的dfs入门,那真的是入门吗,都是把dfs的实现步骤往那一贴,看完是知道dfs的步骤了,但是对于代码实现还是没有概念。今天准备写点自己的心得,真的是字面意思--入门。
DFS,即深度优先搜索,是一种每次搜索都向尽可能深的地方去搜索,到达尽头时再回溯进行其他结点去搜索的搜索策略。形象的说,这是一种“不撞南墙不回头”的策略。
其实也就是遍历,只不过不像一个线性数组的遍历那么直观罢了。说到回溯,每次看到这个词我都得思考一会,到底是怎么用栈进行回溯的呢?今天实际操作了一次bfs,才发现妹的,这个事都是交给编译器去完成的(只要写的是递归形式)...当然了,非递归形式的dfs实现,肯定是要自己做栈的...
迷宫问题
迷宫问题是dfs入门的一个经典问题,这里就以HDOJ 1010 Tempter of Bone 来谈谈如何实际运用dfs。
http://acm.hdu.edu.cn/showproblem.php?pid=1010
题目大意:
S.X.
..X.
..XD
....
给出一个由以上四种符号组成的“迷宫”,‘.’代表可以通行的块,‘X’代表墙不能通过,‘S’代表起点,‘D’代表终点,每秒都必须且只能走一步(上、下、左、右),判断能否恰好在第T秒,到达终点D。其中每次走过的‘.’块都会立刻消失不能再走。
当然了,算法就是dfs了,其实也就是暴力枚举,对走的每一步都进行4个方向上的分支判断,再加上一定的剪枝,舍去一些明显不合题意的结果,以满足时间上的要求。
先贴上代码吧:
#include<cstdlib>
#include<cstring>
#include<iostream>
using namespace std;
char map[][];//输入的迷宫矩阵
int dir[][] = {{, }, {, }, {-, }, {, -}};//4个方向
int OK = ;
int N, M, T, si, sj, di, dj;
int dfs(int si, int sj, int cnt)
{
if (si <= || sj <= || si > N || sj > M)//超出边界就说明这条路已经死了,则返回
{
return ;
}
if (si == di && sj == dj && cnt == T)//找到终点就返回,把标志位置为1
{
OK = ;
}
if (OK)
{
return ;
}
int temp = T - cnt - abs(di - si) - abs(dj - sj);//这里就是剪枝,开始没写这里,Time Limit Exceeded了十几次...下面细谈
if (temp < || temp & )
{
return ;
}
for (int i = ; i < ; ++i)//对走到的每个结点都进行四个方向的探索
{
if (map[si+dir[i][]][sj+dir[i][]] != 'X')
{
map[si+dir[i][]][sj+dir[i][]] = 'X';//走过的路不能走,就先置为墙
dfs(si+dir[i][], sj+dir[i][], cnt + );
map[si+dir[i][]][sj+dir[i][]] = '.';//探索下一条路时,这个结点要恢复成可以走的状态
}
}
return ;
}
int main()
{
while(cin >> N >> M >> T)
{
int wall = ;
OK = ;
if (N == && M == && T == )
{
break;
}
for (int i = ; i <= N; ++i)
{
for (int j = ; j <= M; ++j)
{
cin >> map[i][j];//这里开始还写的scanf("%c", &map[i][j]);蠢的不谈了... 不过可以这样在for(i)的循环里面写 scanf("%s", &map[i]);
if (map[i][j] == 'S')
{
si = i;
sj = j;
}else if (map[i][j] == 'D')
{
di = i;
dj = j;
}else if (map[i][j] == 'X')
{
wall++;
}
}
}
if (N * M - wall <= T)//一个小剪枝
{
cout << "NO" << endl;
continue;
}
map[si][sj] = 'X';
dfs(si, sj, );
if (OK)
{
cout << "YES" << endl;
}else
{
cout << "NO" << endl;
}
}
return ;
}
先借助代码谈一下dfs的过程:
从S开始,i = 0,往右探索,只要没有return,就一直往右走,return了就回溯,回溯的过程呢,就是从i = 0转到i = 1了,这就是回溯的实现过程...
一个小技巧,初始化这个迷宫矩阵的时候,i = 0 , j = 0, i = n + 1, j = m + 1都进行初始化,但是不存储数据,这样相当于在迷宫外面的四面都加上了墙,这样在dfs过程中就不用判断是否出界了...
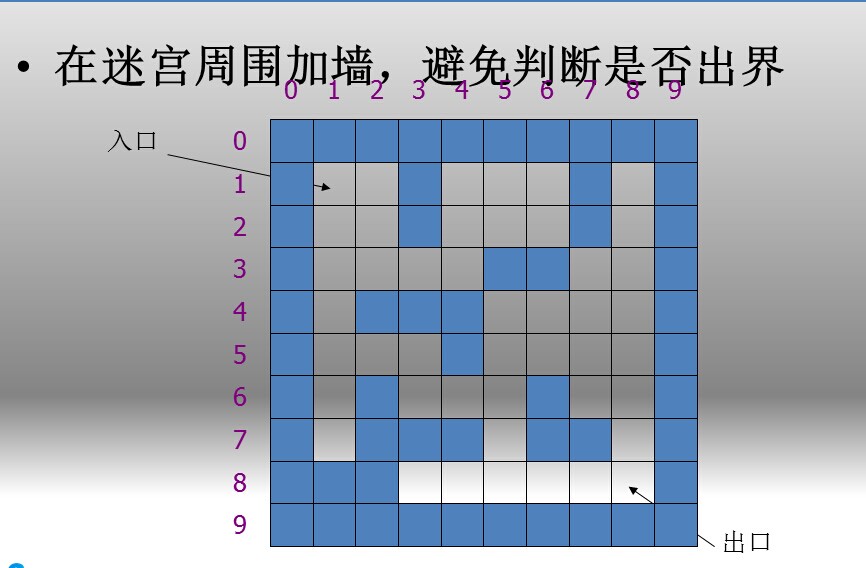
下面谈一下剪枝:
1、如果可走的块数小于T,则肯定不能到达,这就是main()中的那个小剪枝
2、奇偶性剪枝:
所以当遇到从 0 走向 0 但是要求时间是奇数的,或者, 从 1 走向 0 但是要求时间是偶数的 都可以直接判断不可达!
这就是dfs中那个剪枝,也就是最主要的剪枝,其中用了&与运算来判断是不是偶数...
提醒:
算法中最基本和常用的是搜索,这里要说的是,有些初学者在学习这些搜索基本算法是不太注意剪枝,这是十分不可取的,因为所有搜索的题目给你的测试用例都不会有很大的规模,你往往察觉不出程序运行的时间问题,但是真正的测试数据一定能过滤出那些没有剪枝的算法。
实际上参赛选手基本上都会使用常用的搜索算法,题目的区分度往往就是建立在诸如剪枝之类的优化上了。 ”
搜索入门之dfs--经典的迷宫问题解析的更多相关文章
- 『ACM C++』HDU杭电OJ | 1416 - Gizilch (DFS - 深度优先搜索入门)
从周三课开始总算轻松了点,下午能在宿舍研究点题目啥的打一打,还好,刚开学的课程还算跟得上,刚开学的这些课程也是复习以前学过的知识,下半学期也不敢太划水了,被各种人寄予厚望之后瑟瑟发抖,只能努力前行了~ ...
- POJ 1579 Function Run Fun 【记忆化搜索入门】
题目传送门:http://poj.org/problem?id=1579 Function Run Fun Time Limit: 1000MS Memory Limit: 10000K Tota ...
- 【算法导论】图的深度优先搜索遍历(DFS)
关于图的存储在上一篇文章中已经讲述,在这里不在赘述.下面我们介绍图的深度优先搜索遍历(DFS). 深度优先搜索遍历实在访问了顶点vi后,访问vi的一个邻接点vj:访问vj之后,又访问vj的一个邻接点, ...
- Lucene建立索引搜索入门实例
第一部分:Lucene建立索引 Lucene建立索引主要有以下两步:第一步:建立索引器第二步:添加索引文件准备在f盘建立lucene文件夹,然后 ...
- 搜索分析(DFS、BFS、递归、记忆化搜索)
搜索分析(DFS.BFS.递归.记忆化搜索) 1.线性查找 在数组a[]={0,1,2,3,4,5,6,7,8,9,10}中查找1这个元素. (1)普通搜索方法,一个循环从0到10搜索,这里略. (2 ...
- 视音频数据处理入门:H.264视频码流解析
===================================================== 视音频数据处理入门系列文章: 视音频数据处理入门:RGB.YUV像素数据处理 视音频数据处理 ...
- Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析
Java生鲜电商平台-电商中海量搜索ElasticSearch架构设计实战与源码解析 生鲜电商搜索引擎的特点 众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才 ...
- 搜索入门_简单搜索bfs dfs大杂烩
dfs题大杂烩 棋盘问题 POJ - 1321 和经典的八皇后问题一样. 给你一个棋盘,只有#区域可以放棋子,同时同一行和同一列只能有一个棋子. 问你放k个棋子有多少种方案. 很明显,这是搜索题. ...
- HDU 1728 逃离迷宫(DFS经典题,比赛手残写废题)
逃离迷宫 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
随机推荐
- js replace如何实现replaceAll
js下string对象的replace方法的定义如下: stringObject.replace(regexp/substr,replacement) 其中: 参数 | ...
- 2017易观OLAP算法大赛
大赛简介 目前互联网领域有很多公司都在做APP领域的“用户行为分析”产品,与Web时代的行为分析相类似,其目的都是帮助公司的运营.产品等部门更好地优化自家产品,比如查看日活和月活,查看渠道来源 ...
- VMware 安装Ubuntu16.04时显示不全的解决方法
实际安装时发现进行到分区这个步骤时,看不到下面的按钮, 百度后得知有此遭遇的不在少数,是因为系统默认分辨率与电脑分辨率的差异导致的. 解决方法也很简单粗暴: 左手按住alt键右手鼠标往上拖动安装界面, ...
- Python【yagmail】模块发邮件
#步骤一:import yagmail #步骤二:实例化一个发邮件的对象username = '553637138@qq.com' #邮箱账号pwd='sa2008' #授权码mail = yagma ...
- GO_07:GO语言基础之method
方法 method 1. Go 中虽没有 class,但依旧有 method 2. 通过显示说明 receiver 来实现与某个类型的组合 3. 只能为同一个包中的类型定义方法 4. Receiver ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
- Java基础-IO流对象之打印流(PrintStream与PrintWriter)
Java基础-IO流对象之打印流(PrintStream与PrintWriter) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.打印流的特性 打印对象有两个,即字节打印流(P ...
- Java基础-IO流对象之序列化(ObjectOutputStream)与反序列化(ObjectInputStream)
Java基础-IO流对象之序列化(ObjectOutputStream)与反序列化(ObjectInputStream) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.对象的序 ...
- 博世传感器调试笔记(一)----加速度传感器BMA253
公司是bosch的代理商,最近一段时间一直在公司开发的传感器demo板上调试bosch sensor器件.涉及到的器件有7,8款,类型包括重力加速度.地磁.陀螺仪.温度.湿度.大气压力传感器等.在调试 ...
- SQL语句(十九)——存储过程(练习)
select * From Student select * From Course select * from SC --INSERT INTO SC (Sno, Cno, Grade) --VAL ...