Scrapy爬取携程桂林问答
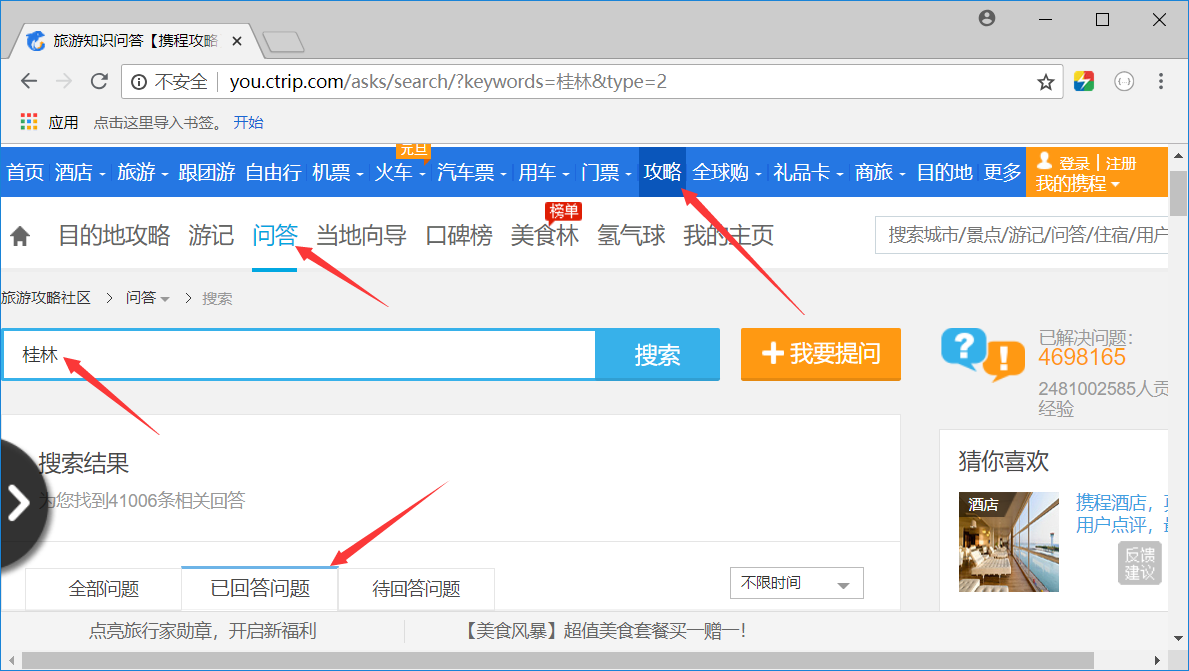
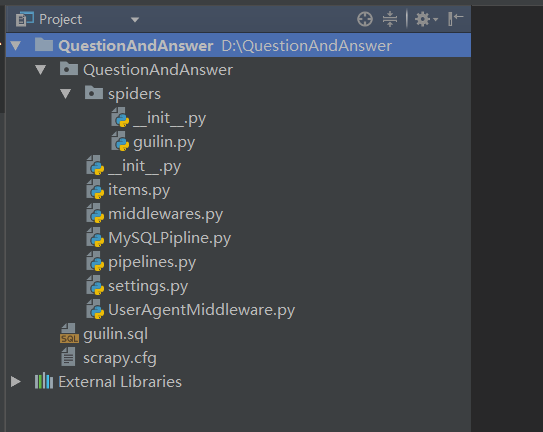
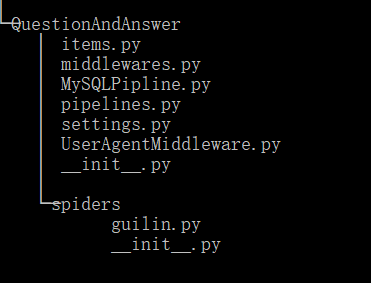
guilin.sql:
CREATE TABLE `guilin_ask` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`question` VARCHAR(255) DEFAULT NULL COMMENT '问题的标题',
`full_question` VARCHAR(255) DEFAULT NULL COMMENT '问题的详情',
`keyword` VARCHAR(255) DEFAULT NULL COMMENT '关键字',
`ask_time` VARCHAR(255) DEFAULT NULL COMMENT '提问时间',
`accept_answer` TEXT COMMENT '提问者采纳的答案',
`recommend_answer` TEXT COMMENT '旅游推荐的答案',
`agree_answer` TEXT COMMENT '赞同数最高的答案',
PRIMARY KEY (`id`),
UNIQUE KEY `question` (`question`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='桂林_问答表'
guilin.py:
# -*- coding: utf-8 -*- import scrapy
from scrapy import Request from QuestionAndAnswer.items import QuestionandanswerItem
from pyquery import PyQuery as pq class GuilinSpider(scrapy.Spider):
name = 'guilin'
allowed_domains = ['you.ctrip.com'] def start_requests(self):
# 重写start_requests方法
ctrip_url = "http://you.ctrip.com/asks/search/?keywords=%e6%a1%82%e6%9e%97&type=2"
# 携程~攻略~问答~桂林~已回答问题 yield Request(ctrip_url, callback=self.list_page) def list_page(self, response):
result = pq(response.text)
# 调用pyquery.PyQuery
result_list = result(".cf")
# 问题列表
question_urls = []
# 问题链接列表
for ask_url in result_list.items():
question_urls.append(ask_url.attr("href"))
while None in question_urls:
question_urls.remove(None)
# 去除None for url in question_urls:
yield response.follow(url, callback=self.detail_page) result.make_links_absolute(base_url="http://you.ctrip.com/")
# 把相对路径转换成绝对路径
next_link = result(".nextpage")
next_url = next_link.attr("href")
# 下一页
if next_url is not None:
# 如果下一页不为空
yield scrapy.Request(next_url, callback=self.list_page) def detail_page(self, response):
detail = pq(response.text)
question_frame = detail(".detailmain")
# 问答框 for i_item in question_frame.items():
ask = QuestionandanswerItem()
ask["question"] = i_item(".ask_title").text()
ask["full_question"] = i_item("#host_asktext").text()
ask["keyword"] = i_item(".asktag_oneline.cf").text()
ask["ask_time"] = i_item(".ask_time").text().strip("发表于")
ask["accept_answer"] = i_item(".bestanswer_con > div > p.answer_text").text()
ask["recommend_answer"] = i_item(".youyouanswer_con > div > p.answer_text").text()
ask["agree_answer"] = i_item("#replyboxid > ul > li:nth-child(1) > div > p.answer_text").text()
yield ask
items.py:
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class QuestionandanswerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() question = scrapy.Field()
# 问题的标题
full_question = scrapy.Field()
# 问题的详情
keyword = scrapy.Field()
# 关键字
ask_time = scrapy.Field()
# 提问时间
accept_answer = scrapy.Field()
# 提问者采纳的答案
recommend_answer = scrapy.Field()
# 旅游推荐的答案
agree_answer = scrapy.Field()
# 赞同数最高的答案
MySQLPipline.py:
from pymysql import connect class MySQLPipeline(object):
def __init__(self):
self.connect = connect(
host='192.168.1.108',
port=3306,
db='scrapy',
user='root',
passwd='Abcdef@123456',
charset='utf8',
use_unicode=True)
# MySQL数据库
self.cursor = self.connect.cursor()
# 使用cursor()方法获取操作游标 def process_item(self, item, spider):
self.cursor.execute(
"""select * from guilin_ask WHERE question = %s""",
item['question'])
# 是否有重复问题
repetition = self.cursor.fetchone() if repetition:
pass
# 丢弃 else:
self.cursor.execute(
"""insert into guilin_ask(
question, full_question, keyword, ask_time, accept_answer, recommend_answer, agree_answer)
VALUE (%s, %s, %s, %s, %s, %s, %s)""",
(item['question'],
item['full_question'],
item['keyword'],
item['ask_time'],
item['accept_answer'],
item['recommend_answer'],
item['agree_answer']
))
# 执行sql语句,item里面定义的字段和表字段一一对应
self.connect.commit()
# 提交
return item
# 返回item def close_spider(self, spider):
self.cursor.close()
# 关闭游标
self.connect.close()
# 关闭数据库连接
Scrapy爬取携程桂林问答的更多相关文章
- 使用requests、re、BeautifulSoup、线程池爬取携程酒店信息并保存到Excel中
import requests import json import re import csv import threadpool import time, random from bs4 impo ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页. 这里以简书里的优选连载网页为例分享一下我的爬取过程. 网址为: ht ...
- Scrapy爬取静态页面
Scrapy爬取静态页面 安装Scrapy框架: Scrapy是python下一个非常有用的一个爬虫框架 Pycharm下: 搜索Scrapy库添加进项目即可 终端下: #python2 sudo p ...
随机推荐
- 20165318 2017-2018-2 《Java程序设计》第九周学习总结
20165318 2017-2018-2 <Java程序设计>第九周学习总结 目录 学习过程遇到的问题及总结 教材学习内容总结 第13章 Java网络编程 代码托管 代码统计 学习过程遇到 ...
- 1854. [SCOI2010]游戏【二分图】
Description lxhgww最近迷上了一款游戏,在游戏里,他拥有很多的装备,每种装备都有2个属性,这些属性的值用[1,10000]之间的数表示.当他使用某种装备时,他只能使用该装备的某一个属性 ...
- juquery去除字符串前后的空格
1. 去掉字符串前后所有空格: 代码如下: function Trim(str) { return str.replace(/(^\s*)|(\s*$)/g, ""); }
- Spring Boot中使用EhCache实现缓存支持
SpringBoot提供数据缓存功能的支持,提供了一系列的自动化配置,使我们可以非常方便的使用缓存.,相信非常多人已经用过cache了.因为数据库的IO瓶颈.一般情况下我们都会引入非常多的缓存策略, ...
- 专家PID控制
1.专家PID控制原理 PID专家控制的实质是,基于受控对象和控制规律的各种知识,无需知道被控对象的精确模型,利用专家经验来设计PID参数.专家PID控制是一种直接型专家控制器. 典型的二阶系统单位阶 ...
- 优化升级logging封装RotatingFileHandler
1.升级优化,提供用户自定义日志level文件夹生成控制,提供日志错误显示到日志打印异常补获到日志 # coding=utf-8 import logging import time import o ...
- ZOJ3211-Dream City(贪心思想+变形的01背包)
Dream City Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%lld & %llu Submit Sta ...
- 使用CoreAnimation 实现相机拍摄照片之后动画效果
废话不多说,先看上效果,由于动画录制的时候帧率限制,只能将动画放慢了进行录制,更容易看到效果 这是点击开始之后代码 -(IBAction)btnStartClick:(id)sender { CABa ...
- CTF-i春秋网鼎杯第二场misc部分writeup
CTF-i春秋网鼎杯第二场misc部分writeup 套娃 下载下来是六张图片 直接看并没有什么信息 一个一个查看属性 没有找到有用信息 到winhexv里看一下 都是标准的png图片,而且没有fla ...
- C语言学习记录_2019.02.23
char类型的输出: scanf("%d",&i);//i=49; char x=i; printf("x=%d\n",x); printf(" ...