Lucene系列-facet--转
https://blog.csdn.net/whuqin/article/details/42524825
1.facet的直观认识
facet:面、切面、方面。个人理解就是维度,在满足query的前提下,观察结果在各维度上的分布(一个维度下各子类的数目)。
如jd上搜“手机”,得到4009个商品。其中品牌、网络、价格就是商品的维度(facet),点击某个品牌或者网络,获取更细分的结果。

点击品牌小米,获得小米手机的结果,显示27个。
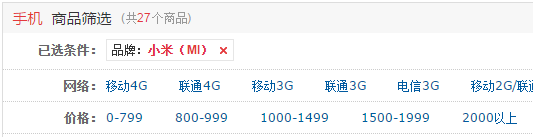
点击移动4G,获得移动4G、小米手机,显示4个。
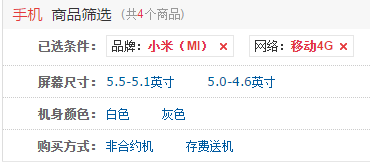
2.facet特性
facet counting:返回一个facet下某子类的结果数。如上面的品牌维度下小米子类中满足查询"手机"的结果有27个。
facet associations:一个文档与某子类的关联度,如一本书30%讲lucene,70%讲solor,这个百分比就是书与分类的关联度(匹配度、信心度)。
multiple facet requests:支持多facet查询(多维度查询)。如查询品牌为小米、网络为移动4G的手机。
3.实例
一个facet简单使用例子,依赖于lucene-facet-4.10.0。讲述了从搜手机到品牌、到网络向下browser的过程。
public class SimpleFacetsExample {
private final Directory indexDir = new RAMDirectory();
private final Directory taxoDir = new RAMDirectory();
private final FacetsConfig config = new FacetsConfig();
/** Empty constructor */
public SimpleFacetsExample() {
config.setHierarchical("Publish Date", true);
}
/** Build the example index. */
private void index() throws IOException {
IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig(Version.LUCENE_4_10_0,
new WhitespaceAnalyzer()));
// Writes facet ords to a separate directory from the main index
DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir);
Document doc = new Document();
doc.add(new TextField("device", "手机", Field.Store.YES));
doc.add(new TextField("name", "米1", Field.Store.YES));
doc.add(new FacetField("brand", "小米"));
doc.add(new FacetField("network", "移动4G"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new TextField("device", "手机", Field.Store.YES));
doc.add(new TextField("name", "米4", Field.Store.YES));
doc.add(new FacetField("brand", "小米"));
doc.add(new FacetField("network", "联通4G"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new TextField("device", "手机", Field.Store.YES));
doc.add(new TextField("name", "荣耀6", Field.Store.YES));
doc.add(new FacetField("brand", "华为"));
doc.add(new FacetField("network", "移动4G"));
indexWriter.addDocument(config.build(taxoWriter, doc));
doc = new Document();
doc.add(new TextField("device", "电视", Field.Store.YES));
doc.add(new TextField("name", "小米电视2", Field.Store.YES));
doc.add(new FacetField("brand", "小米"));
indexWriter.addDocument(config.build(taxoWriter, doc));
taxoWriter.close();
indexWriter.close();
}
private void facetsWithSearch() throws IOException {
DirectoryReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher searcher = new IndexSearcher(indexReader);
TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir);
FacetsCollector fc = new FacetsCollector();
//1.查询手机
System.out.println("-----手机-----");
TermQuery query = new TermQuery(new Term("device", "手机"));
FacetsCollector.search(searcher, query, 10, fc);
Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc);
List<FacetResult> results = facets.getAllDims(10);
//手机总共有3个,品牌维度:小米2个,华为1个;网络维度:移动4G 2个,联通4G 1个
for (FacetResult tmp : results) {
System.out.println(tmp);
}
//2.drill down,品牌选小米
System.out.println("-----小米手机-----");
DrillDownQuery drillDownQuery = new DrillDownQuery(config, query);
drillDownQuery.add("brand", "小米");
FacetsCollector fc1 = new FacetsCollector();//要new新collector,否则会累加
FacetsCollector.search(searcher, drillDownQuery, 10, fc1);
facets = new FastTaxonomyFacetCounts(taxoReader, config, fc1);
results = facets.getAllDims(10);
//获得小米手机的分布,总数2个,网络:移动4G 1个,联通4G 1个
for (FacetResult tmp : results) {
System.out.println(tmp);
}
//3.drill down,小米移动4G手机
System.out.println("-----移动4G小米手机-----");
drillDownQuery.add("network", "移动4G");
FacetsCollector fc2 = new FacetsCollector();
FacetsCollector.search(searcher, drillDownQuery, 10, fc2);
facets = new FastTaxonomyFacetCounts(taxoReader, config, fc2);
results = facets.getAllDims(10);
for (FacetResult tmp : results) {
System.out.println(tmp);
}
//4.drill sideways,横向浏览
//如果已经进入了小米手机,但是还想看到其他牌子(华为)的手机数目,就用到了sideways
System.out.println("-----小米手机drill sideways-----");
DrillSideways ds = new DrillSideways(searcher, config, taxoReader);
DrillDownQuery drillDownQuery1 = new DrillDownQuery(config, query);
drillDownQuery1.add("brand", "小米");
DrillSidewaysResult result = ds.search(drillDownQuery1, 10);
results = result.facets.getAllDims(10);
for (FacetResult tmp : results) {
System.out.println(tmp);
}
indexReader.close();
taxoReader.close();
}
/** Runs the search and drill-down examples and prints the results. */
public static void main(String[] args) throws Exception {
SimpleFacetsExample example = new SimpleFacetsExample();
example.index();
example.facetsWithSearch();
}
}
输出:
-----手机-----
//总数3个,2个子类
dim=brand path=[] value=3 childCount=2
小米 (2)
华为 (1)
dim=network path=[] value=3 childCount=2
移动4G (2)
联通4G (1)
-----小米手机-----
//普通向下浏览,丢失了同一维度,其他子类的统计
dim=brand path=[] value=2 childCount=1
小米 (2)
dim=network path=[] value=2 childCount=2
移动4G (1)
联通4G (1)
-----移动4G小米手机-----
dim=brand path=[] value=1 childCount=1
小米 (1)
dim=network path=[] value=1 childCount=1
移动4G (1)
-----小米手机drill sideways-----
//drill sideways, 保留了该drill维度的其他子类统计
dim=brand path=[] value=3 childCount=2
小米 (2)
华为 (1)
//小米手机中的网络分布
dim=network path=[] value=2 childCount=2
移动4G (1)
联通4G (1)
Lucene系列-facet--转的更多相关文章
- Lucene系列-facet
1.facet的直观认识 facet:面.切面.方面.个人理解就是维度,在满足query的前提下,观察结果在各维度上的分布(一个维度下各子类的数目). 如jd上搜“手机”,得到4009个商品.其中品牌 ...
- Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
一.Lucene介绍 1. Lucene简介 最受欢迎的java开源全文搜索引擎开发工具包.提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言).Lucene的目的是为软件开发人 ...
- lucene中facet实现统计分析的思路——本质上和word count计数无异,像splunk这种层层聚合(先filed1统计,再field2统计,最后field3统计)lucene是排序实现
http://stackoverflow.com/questions/185697/the-most-efficient-way-to-find-top-k-frequent-words-in-a-b ...
- Lucene系列-FieldCache
域缓存,加载所有文档中某个特定域的值到内存,便于随机存取该域值. 用途及使用场景 当用户需要访问各文档中某个域的值时,IndexSearcher.doc(docId)获得Document的所有域值,但 ...
- [lucene系列笔记1]lucene6的安装与配置(Windows系统)
lucene是一个java开源的高效全文检索工具包,最近做项目要用到,把学习的过程记录一下. 第一步:下载安装jdk 1.首先从官网下载jdk(下载之前先查看你的电脑是多少位操作系统,如果是32就下载 ...
- Lucene系列-索引文件
本文介绍下lucene生成的索引有哪些文件组成,每个文件包含了什么信息.基于Lucene 4.10.0. 数据结构 索引(index)包含了存储的文档(document)正排.倒排信息,用于文本搜索. ...
- Lucene系列-近实时搜索(1)
近实时搜索(near-real-time)可以搜索IndexWriter还未commit的内容,介于immediate和eventual之间,在数据比较大.更新较频繁的情况下使用.本文主要来介绍下如何 ...
- Lucene系列-搜索
Lucene搜索的时候就要构造查询语句,本篇就介绍下各种Query.IndexSearcher是搜索主类,提供的常用查询接口有: TopDocs search(Query query, int n); ...
- Lucene系列-分析器
分析器介绍 搜索的基础是对文本信息进行分析,Lucene的分析工具在org.apache.lucene.analysis包中.分析器负责对文本进行分词.语言处理得到词条,建索引和搜索的时候都需要用到分 ...
随机推荐
- JProfiler 简要使用说明
1.简介 JProfiler是一个ALL-IN-ONE的JAVA剖析工具,可以方便地监控Java程序的CPU.内存使用状况,能够检查垃圾回收.分析性能瓶颈. 本说明文档基于JProfiler 9.2编 ...
- 使用 Project Siena 生成一个 Windows Store 应用
继 App Studio 之后微软又一力作 Project Siena [Win8 应用神器]给初学开发 或 对 Windows Store 应用感兴趣的同学们的一个福利,可以通过 一个简单的应用可以 ...
- 客户端Git代码的下载与提交
(1)git clone 服务器用户名@服务器IP:~/Git目录/.git 功能:下载服务器端Git仓库中的文件或目录到本地当前目录. (2)对Git目录中的文件进行修改. (3)git statu ...
- 打开AVD时报”Data partition already in use. Changes will not persist!”
错误信息 WARNING: Data partition already in use. Changes will not persist! WARNING: SD Card image alread ...
- 经典串匹配算法(KMP)解析
一.问题重述 现有字符串S1,求S1中与字符串S2完全匹配的部分,例如: S1 = "ababaababc" S2 = "ababc" 那么得到匹配的结果是5( ...
- C#模拟请求,模拟登录,Cookie设置、文件上传等问题汇总
由于业务需求,最近需要模拟完成登陆某个网站,并上传所需要的文件.在开发途中,遇到了很多问题,现在,就我遇到的一些问题及解决办法说明如下,希望对遇到同样问题的人有所帮助.因为技术有限,可能有些内容并不完 ...
- (C#)冒泡排序
//冒泡排序 public static int[] Bubbling(int[] s) { int a; for (int i = 0; i < s.Length-1; i++) { for ...
- 【Cocos2d-Js实战教学(1)横版摇杆八方向移动】
本教程主要通过搭建一个横版摇杆八方向移动的实例,让大家如何用Cocos2dx-Js来做一款游戏,从基础了解Cocos2dx-Js的基本实现原理,从创建工程,到各个知识点的梳理. 教程分为上下两讲: 上 ...
- XCode - vmware虚拟机安装XCode进行iPhone真机调试
1.vmware安装黑苹果,然后在appStore安装XCode http://blog.csdn.net/forgot2015/article/details/51104329 2.真机调试证书等申 ...
- 600. Non-negative Integers without Consecutive Ones
Given a positive integer n, find the number of non-negative integers less than or equal to n, whose ...