K:单词查找树(Trie)
单词查找树,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。Trie可以看作是一个确定有限状态自动机(DFA)。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。 Trie这个术语来自于retrieval。根据词源学。本博文主要讲解了单词查找树的相关知识及其实现。
如下所示为一棵单词查找树:
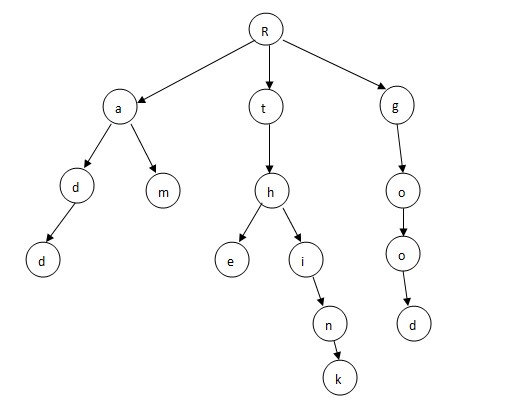
与二叉查找树不同,Trie树的键不是直接保存在节点中,而是由节点在树中的位置决定。
对于Trie树它有3个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符都不相同。
Trie树效率分析:
Trie树优点是最大限度地减少无谓的字符串比较,查询效率比较高。核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
- 插入、查找的时间复杂度均为O(M),其中M为字符串长度。
- 对于英文字母的字典树,其空间复杂度是26^n 级别的数字的字典树是10^n 级别的,非常庞大。
Trie树创建:
Trie树的创建要考虑的是父节点如何保存孩子节点,主要有链表和数组两种方式:
使用节点数组,因为是英文字符,可以用Node[26]来保存孩子节点(如果是数字我们可以用Node[10]),这种方式最快,但是并不是所有节点都会有很多孩子,所以这种方式浪费的空间太多
用一个链表根据需要动态添加节点。这样我们就可以省下不小的空间,但是缺点是搜索的时候需要遍历这个链表,增加了时间复杂度。
可以结合hash表来存储其对应的孩子节点,以孩子节点的值为键,指向孩子节点的指针为值。这样在理论上可以做到时间复杂度为O(1)的情况,且空间的浪费程度不高。
Trie树实现:
对于trie树,其使用得较频繁点的功能是查找和插入,为此,此处主要讲解Trie树的插入和查找功能。
在讲解其相应的功能之前,我们先定义Trie树节点类:
class TrieNode{
/**
* 该节点的值
*/
String value;
/**
* 该节点的孩子节点
*/
Map<String,TrieNode> children;
/**
*用于判断该孩子节点是否为最终节点,即对应的单词的末尾字符
*/
boolean isEnd;
public TrieNode(){
this(null);
}
public TrieNode(String value){
this(value,false);
}
public TrieNode(String value,boolean isEnd){
this.value=value;
this.isEnd=isEnd;
children=new HashMap<String,TrieNode>();
}
/**
* 用于设置当前节点的值
* @param value 当前节点的值
*/
public void setValue(String value){
this.value=value;
}
/**
* 用于获取其当前节点的值
* @return 当前节点值
*/
public String getValue(){
return this.value;
}
/**
* 用于设置当前节点的字符是否为字符串的最后一个字符
* @param isEnd true表示当前字符为字符串的最后一个字符
*/
public void setIsEnd(boolean isEnd){
this.isEnd=isEnd;
}
/**
* 用于获取其当前节点是否为单词末尾字符的判断
* @return 返回其对应的结果
*/
public boolean getIsEnd(){
return this.isEnd;
}
/**
* 用于添加当前节点的孩子节点
* @param value 孩子节点的值
* @param node 指向当前节点的孩子节点的指针
*/
public void addChild(String value,TrieNode node){
children.put(value,node);
}
/**
* 用于获取当前节点的孩子节点
* @param value 孩子节点的值
* @return 其对应的孩子节点的指针
*/
public TrieNode getChild(String value){
return children.get(value);
}
}
- 插入:
对于插入操作,无非是逐一把单词的每个字符插入到对应前缀的后面,使其成为该前缀的孩子节点。需要注意的是,在插入之前,先查看前缀是否存在,如果存在就共享,否则穿件对应的节点和边。
其插入操作的相关代码如下:
public void add(String value){
TrieNode node=head;
for(int i=0;i<value.length();i++){
String v=String.valueOf(value.charAt(i));
TrieNode child=node.getChild(v);
//该字符并没有在相应的孩子节点中
if(child==null){
child=new TrieNode(v);
node.addChild(v,child);
}
//当其为该单词的最后一个字符时
if(i==value.length()-1){
child.setIsEnd(true);
}
node=child;
}
}
- 查找:
对于查找操作而言,其较为简单,只需要沿着字典树的链接,从上往下查找即可。
具体代码如下:
/**
* 用于判断其对应单词是否在其对应的字典树中
* @param value 需要查找的单词
* @return 是否在字典树中的判断
*/
public boolean search(String value){
TrieNode node = head;
for(int i=0;i<value.length();i++){
String v=String.valueOf(value.charAt(i));
TrieNode child=node.getChild(v);
if(child==null){
return false;
}
//当为最后一个字符,且其不为截止字符的时候,表示该单词不在字典树中
if(i==value.length()-1&&!child.getIsEnd()){
return false;
}
node=child;
}
return true;
}
完整代码如下:
import java.util.HashMap;
import java.util.Map;
/**
* @author 学徒
* 用于实现Trie树
*/
public class Trie {
/**
* 该trie树的根节点
*/
private TrieNode head=new TrieNode();
/**
* Trie树对应的节点类
*/
private class TrieNode{
/**
* 该节点的值
*/
String value;
/**
* 该节点的孩子节点
*/
Map<String,TrieNode> children;
/**
*用于判断该孩子节点是否为最终节点,即对应的单词的末尾字符
*/
boolean isEnd;
public TrieNode(){
this(null);
}
public TrieNode(String value){
this(value,false);
}
public TrieNode(String value,boolean isEnd){
this.value=value;
this.isEnd=isEnd;
children=new HashMap<String,TrieNode>();
}
/**
* 用于设置当前节点的值
* @param value 当前节点的值
*/
public void setValue(String value){
this.value=value;
}
/**
* 用于获取其当前节点的值
* @return 当前节点值
*/
public String getValue(){
return this.value;
}
/**
* 用于设置当前节点的字符是否为字符串的最后一个字符
* @param isEnd true表示当前字符为字符串的最后一个字符
*/
public void setIsEnd(boolean isEnd){
this.isEnd=isEnd;
}
/**
* 用于获取其当前节点是否为单词末尾字符的判断
* @return 返回其对应的结果
*/
public boolean getIsEnd(){
return this.isEnd;
}
/**
* 用于添加当前节点的孩子节点
* @param value 孩子节点的值
* @param node 指向当前节点的孩子节点的指针
*/
public void addChild(String value,TrieNode node){
children.put(value,node);
}
/**
* 用于获取当前节点的孩子节点
* @param value 孩子节点的值
* @return 其对应的孩子节点的指针
*/
public TrieNode getChild(String value){
return children.get(value);
}
}
/**
* 用于Trie树的插入操作
* @param value
*/
public void add(String value){
TrieNode node=head;
for(int i=0;i<value.length();i++){
String v=String.valueOf(value.charAt(i));
TrieNode child=node.getChild(v);
//该字符并没有在相应的孩子节点中
if(child==null){
child=new TrieNode(v);
node.addChild(v,child);
}
//当其为该单词的最后一个字符时
if(i==value.length()-1){
child.setIsEnd(true);
}
node=child;
}
}
/**
* 用于判断其对应单词是否在其对应的字典树中
* @param value 需要查找的单词
* @return 是否在字典树中的判断
*/
public boolean search(String value){
TrieNode node = head;
for(int i=0;i<value.length();i++){
String v=String.valueOf(value.charAt(i));
TrieNode child=node.getChild(v);
if(child==null){
return false;
}
//当为最后一个字符,且其不为截止字符的时候,表示该单词不在字典树中
if(i==value.length()-1&&!child.getIsEnd()){
return false;
}
node=child;
}
return true;
}
}
Trie树应用场景:
1. 字符串检索
事先将已知的一些字符串(字典)的有关信息保存到trie树里,查找另外一些未知字符串是否出现过或者出现频率。
举例:
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
给出一个词典,其中的单词为不良单词。单词均为小写字母。再给出一段文本,文本的每一行也由小写字母构成。判断文本中是否含有任何不良单词。例如,若rob是不良单词,那么文本problem含有不良单词。
2. 字符串最长公共前缀
Trie树利用多个字符串的公共前缀来节省存储空间,反之,当我们把大量字符串存储到一棵trie树上时,我们可以快速得到某些字符串的公共前缀。
举例:
给出N个小写英文字母串,以及Q 个询问,即询问某两个串的最长公共前缀的长度是多少?
解决方案: 首先对所有的串建立其对应的字母树。此时发现,对于两个串的最长公共前缀的长度即它们所在结点的公共祖先个数,于是,问题就转化为了离线(Offline)的最近公共祖先(Least Common Ancestor,简称LCA)问题。
而最近公共祖先问题同样是一个经典问题,可以用下面几种方法:
利用并查集(Disjoint Set),可以采用经典的Tarjan 算法;
求出字母树的欧拉序列(Euler Sequence )后,就可以转为经典的最小值查询(Range Minimum Query,简称RMQ)问题了;
3. 排序
Trie树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
比如给你N个互不相同的仅由一个单词构成的英文名,让你将它们按字典序从小到大排序输出。
4. 作为其他数据结构和算法的辅助结构
如后缀树,AC自动机等
5. 词频统计
trie树在这里的应用类似哈夫曼树,
比如词频统计使用哈希表或者堆都可以,但是如果内存有限,就可以用trie树来压缩空间,因为trie树的公共前缀都是用一个节点保存的。
6. 字符串搜索的前缀匹配
trie树常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。
Trie树检索的时间复杂度可以做到O(M),M是要检索单词的长度,如果使用暴力检索,需要指数级O(M^2)的时间复杂度。
博文参考自:字典树(Trie树)的实现及应用
K:单词查找树(Trie)的更多相关文章
- cogs 293. [NOI 2000] 单词查找树 Trie树字典树
293. [NOI 2000] 单词查找树 ★★☆ 输入文件:trie.in 输出文件:trie.out 简单对比时间限制:1 s 内存限制:128 MB 在进行文法分析的时候,通常需 ...
- codevs 1729 单词查找树
二次联通门 : codevs 1729 单词查找树 /* codevs 1729 单词查找树 Trie树 统计节点个数 建一棵Trie树 插入单词时每新开一个节点就计数器加1 */ #include ...
- Trie树,又称单词查找树、字典
在百度或淘宝搜索时,每输入字符都会出现搜索建议,比如输入“北京”,搜索框下面会以北京为前缀,展示“北京爱情故事”.“北京公交”.“北京医院”等等搜索词.实现这类技术后台所采用的数据结构是什么?[中国某 ...
- 【数据结构】关于前缀树(单词查找树,Trie)
前缀树的说明和用途 前缀树又叫单词查找树,Trie,是一类常用的数据结构,其特点是以空间换时间,在查找字符串时有极大的时间优势,其查找的时间复杂度与键的数量无关,在能找到时,最大的时间复杂度也仅为键的 ...
- COGS 293.[NOI2000] 单词查找树
★ 输入文件:trie.in 输出文件:trie.out 简单对比 时间限制:1 s 内存限制:128 MB 在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里.为了提高 ...
- [NOI2000] 单词查找树
★★ 输入文件:trie.in 输出文件:trie.out 简单对比 时间限制:1 s 内存限制:128 MB 在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里.为了提 ...
- 293. [NOI2000] 单词查找树——COGS
293. [NOI2000] 单词查找树 ★★ 输入文件:trie.in 输出文件:trie.out 简单对比时间限制:1 s 内存限制:128 MB 在进行文法分析的时候,通常需要检 ...
- 解题报告:luogu P5755 [NOI2000]单词查找树
题目链接:P5755 [NOI2000]单词查找树 曾几何时,NOI 也有这么水的题( 裸的\(Trie\),只用维护插入即可,记得\(+1\)就好了,真没用讲的. \(Code\): #includ ...
- 【NOI2000】 单词查找树
问题描述 在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里.为了提高查找和定位的速度,通常都画出与单词列表所对应的单词查找树,其特点如下: 根结点不包含字母,除根结点外每一个结点都仅包 ...
随机推荐
- 听补天漏洞审核专家实战讲解XXE漏洞
对于将“挖洞”作为施展自身才干.展现自身价值方式的白 帽 子来说,听漏洞审核专家讲如何挖掘并验证漏洞,绝对不失为一种快速的成长方式! XXE Injection(XML External Entity ...
- cmd下查看应用端口情况
在win10开始窗口右侧的空白处点击CMD,在上方弹出窗口中选择命令提示符,双击进入 在弹出命令界面中,输入netstat -na命令后回车,如下图所示,可以看到所有目前打开的端口 如果要查看打开端口 ...
- 大白dmeo (转的)
<!doctype html><html> <head> <meta charset="utf-8"> <title>B ...
- Java爬虫——Gecco简单入门程序(根据下一页一直爬数据)
为了完成作业,所以学习了一下爬虫Gecco,这个爬虫集合了以往所有的爬虫的特点,但是官方教程中关于Gecco的教程介绍的过于简单,本篇博客是根据原博客的地址修改的,原博客中只有程序的截图,而没有给出一 ...
- uiautomatorviewer 双击闪退问题解决
最近在学习app自动测试,结果在打开uiautomatorviewer查看app界面元素时,就出现了闪退的问题,找了很多很多方法,最后终于可以解决了,详情请继续往下看 首次安装adt的步骤 将下载的压 ...
- node开发环境配置
node开发环境配置 用处 NodeJS——后台 JavaScript-前台 后台其他语言 1.PHP 2.Java 3.Pythonnode优势 1.性能高 nodejs php 86 1s 1分半 ...
- Windows10下简单搭建zookeeper
转载请注明源出处:http://www.cnblogs.com/lighten/p/6798669.html 1 简介 zookeeper是Apache的一个开源项目,致力于开发和维护一个开源的服务器 ...
- MAC帧格式、IPV4数据报格式、TCP报文格式、UDP数据报格式
1.MAC帧格式 类型:2字节,指出数据域中携带的数据应交给哪些协议实体处理 校验码:校验数据段(采用32位CRC冗余校验方式进行校验) 2.IPV4数据报 版本:IP协议版本,这里为4 首部长度:占 ...
- gitHub-高仿58同城加载动画
导入方式: /build.gradle repositories { maven { url "https://jitpack.io" } } /app/build.gradle ...
- Javac语法糖之内部类
在Javac中解语法糖主要是Lower类来完成,调用这个类的入口函数translateTopLevelClass即可.这个方法只是JavacCompiler类的desugar方法中进行了调用. 首先来 ...