Nginx随笔
1、用于代理与反代理,处理大量请求的工具。
2、主要有三大模块:handle、upstream、过滤模块。handle用于在nginx内部接到请求并进行处理的状况;upstream用于需要nginx接受请求并传递给处理端的状况;过滤模块则处理过滤任务。
3、事件驱动的典范。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
一、Nginx的模块与工作原理
1、模块
Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(location是Nginx配置中的一个指令,用于URL匹配),而在这个location中所配置的每个指令将会启动不同的模块去完成相应的工作。
Nginx的模块从结构上分为核心模块、基础模块和第三方模块:
核心模块:HTTP模块、EVENT模块和MAIL模块
基础模块:HTTP Access模块、HTTP FastCGI模块、HTTP Proxy模块和HTTP Rewrite模块,
第三方模块:HTTP Upstream Request Hash模块、Notice模块和HTTP Access Key模块。
用户根据自己的需要开发的模块都属于第三方模块。正是有了这么多模块的支撑,Nginx的功能才会如此强大。
Nginx的模块从功能上分为如下三类。
Handlers(处理器模块)。此类模块直接处理请求,并进行输出内容和修改headers信息等操作。Handlers处理器模块一般只能有一个。
Filters (过滤器模块)。此类模块主要对其他处理器模块输出的内容进行修改操作,最后由Nginx输出。
Proxies (代理类模块)。此类模块是Nginx的HTTP Upstream之类的模块,这些模块主要与后端一些服务比如FastCGI等进行交互,实现服务代理和负载均衡等功能。
图1-1展示了Nginx模块常规的HTTP请求和响应的过程。

图1-1展示了Nginx模块常规的HTTP请求和响应的过程。
Nginx本身做的工作实际很少,当它接到一个HTTP请求时,它仅仅是通过查找配置文件将此次请求映射到一个location block,而此location中所配置的各个指令则会启动不同的模块去完成工作,因此模块可以看做Nginx真正的劳动工作者。通常一个location中的指令会涉及一个handler模块和多个filter模块(当然,多个location可以复用同一个模块)。handler模块负责处理请求,完成响应内容的生成,而filter模块对响应内容进行处理。
Nginx的模块直接被编译进Nginx,因此属于静态编译方式。启动Nginx后,Nginx的模块被自动加载,不像Apache,首先将模块编译为一个so文件,然后在配置文件中指定是否进行加载。在解析配置文件时,Nginx的每个模块都有可能去处理某个请求,但是同一个处理请求只能由一个模块来完成。
2、工作原理
在工作方式上,Nginx分为单工作进程和多工作进程两种模式。在单工作进程模式下,除主进程外,还有一个工作进程,工作进程是单线程的;在多工作进程模式下,每个工作进程包含多个线程。Nginx默认为单工作进程模式。
Nginx在启动后,会有一个master进程和多个worker进程。
master进程
主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。
master进程充当整个进程组与用户的交互接口,同时对进程进行监护。它不需要处理网络事件,不负责业务的执行,只会通过管理worker进程来实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。
我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
worker进程:
而基本的网络事件,则是放在worker进程中来处理了。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的。
worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
nginx的进程模型,可以由下图来表示:

二、基础架构
1、内存池
简介:
Nginx里内存的使用大都十分有特色:申请了永久保存,抑或伴随着请求的结束而全部释放,还有写满了缓冲再从头接着写.这么做的原因也主要取决于Web Server的特殊的场景,内存的分配和请求相关,一条请求处理完毕,即可释放其相关的内存池,降低了开发中对内存资源管理的复杂度,也减少了内存碎片的存在.
所以在Nginx使用内存池时总是只申请,不释放,使用完毕后直接destroy整个内存池.我们来看下内存池相关的实现。
结构:
struct ngx_pool_s {
ngx_pool_data_t d;
size_t max;
ngx_pool_t *current;
ngx_chain_t *chain;
ngx_pool_large_t *large;
ngx_pool_cleanup_t *cleanup;
ngx_log_t *log;
};
struct ngx_pool_large_s {
ngx_pool_large_t *next;
void *alloc;
};
typedef struct {
u_char *last;
u_char *end;
ngx_pool_t *next;
ngx_uint_t failed;
} ngx_pool_data_t;
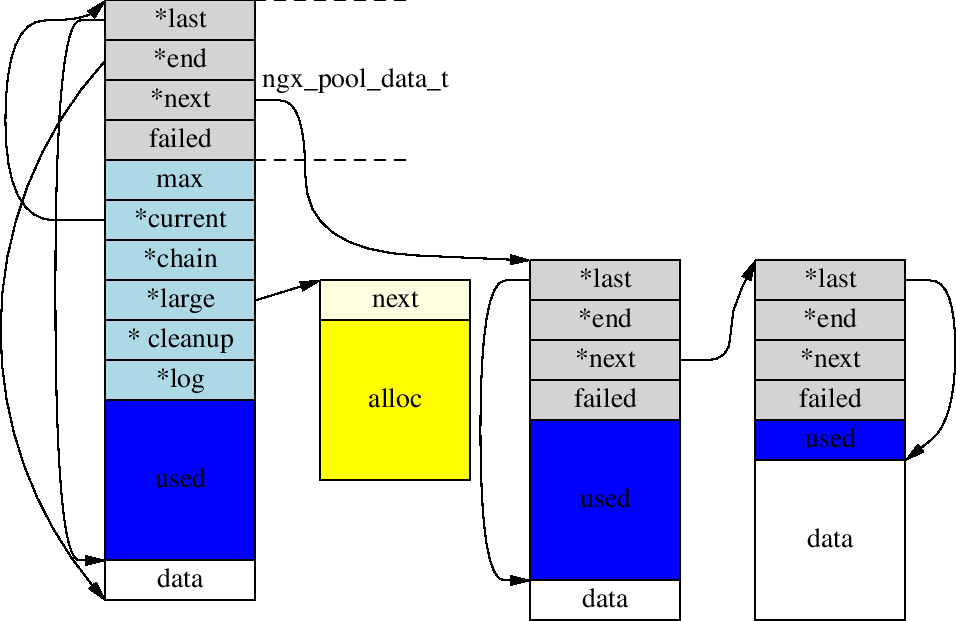
实现:
这三个数据结构构成了基本的内存池的主体.通过ngx_create_pool可以创建一个内存池,通过ngx_palloc可以从内存池中分配指定大小的内存。
ngx_pool_t *
ngx_create_pool(size_t size, ngx_log_t *log)
{
ngx_pool_t *p; p = ngx_memalign(NGX_POOL_ALIGNMENT, size, log);
if (p == NULL) {
return NULL;
} p->d.last = (u_char *) p + sizeof(ngx_pool_t);
p->d.end = (u_char *) p + size;
p->d.next = NULL;
p->d.failed = ; size = size - sizeof(ngx_pool_t);
p->max = (size < NGX_MAX_ALLOC_FROM_POOL) ? size : NGX_MAX_ALLOC_FROM_POOL; p->current = p;
p->chain = NULL;
p->large = NULL;
p->cleanup = NULL;
p->log = log; return p;
}
这里首申请了一块大小为size的内存区域,其前sizeof(ngx_pool_t)字节用来存储ngx_pool_t这个结构体自身自身.所以若size小于sizeof(ngx_pool_t)将会有coredump的可能性。
Nginx的内存池不仅用于内存方面的管理,还可以通过`ngx_pool_cleanup_add`来添加内存池释放时的回调函数,以便用来释放自己申请的其他相关资源。
从代码中可以看出,这些由自己添加的释放回调是以链表形式保存的,也就是说你可以添加多个回调函数来管理不同的资源。
2、共享内存
在Nginx里,一块完整的共享内存以数据结构ngx_shm_zone_t来封装表示。
typedef struct {
u_char *addr; // 分配的共享内存的实际地址(这里实际共享内存的分配,根据当前系统可提供的接口,可以调用mmap或者shmget来进行分配,具体的用法,自己man吧)
size_t size; // 共享内存的大小
ngx_str_t name; // 该字段用作共享内存的唯一标识,能让Nginx知道想使用哪个共享内存
ngx_log_t *log;
ngx_uint_t exists; /* unsigned exists:1; */
} ngx_shm_t;
typedef struct ngx_shm_zone_s ngx_shm_zone_t;
typedef ngx_int_t (*ngx_shm_zone_init_pt) (ngx_shm_zone_t *zone, void *data);
struct ngx_shm_zone_s {
void *data; // 指向自定义数据结构,一般用来初始化时使用,可能指向本地地址
ngx_shm_t shm; // 真正的共享内存所在
ngx_shm_zone_init_pt init; // 这里有一个钩子函数,用于实际共享内存进行分配后的初始化
void *tag; // 区别于shm.name,shm.name没法让Nginx区分到底是想新创建一个共享内存,还是使用已存在的旧的共享内存
// 因此这里引入tag字段来解决该问题,tag一般指向当前模块的ngx_module_t变量,见:...
};
要在Nginx里使用一个共享内存,需要在配置文件里加上该共享内存的相关信息(添加一条指令),如:共享内存的名称,共享内存的大小等。因此在配置解析阶段,解析到相应的指令时,会创建对应的共享内存(此时创建的仅仅是代表共享内存的结构体:ngx_shm_zone_t,真实共享内存的分配在ngx_init_cycle(&init_cycle)解析完配置后进行并初始化)。见:
int ngx_cdecl
main(int argc, char *const *argv) // 在master进程中
{
cycle = ngx_init_cycle(&init_cycle);
{
if (ngx_conf_parse(&conf, &cycle->conf_file) != NGX_CONF_OK) { // 解析配置
{
解析到http指令(进入ngx_http_block())
{
// 会依次执行
typedef struct {
ngx_int_t (*preconfiguration)(ngx_conf_t *cf); /* 执行顺序4 */
ngx_int_t (*postconfiguration)(ngx_conf_t *cf); /* 执行顺序8 */ void *(*create_main_conf)(ngx_conf_t *cf); /* 执行顺序1 */
char *(*init_main_conf)(ngx_conf_t *cf, void *conf); /* 执行顺序5 */ void *(*create_srv_conf)(ngx_conf_t *cf); /* 执行顺序2 */
char *(*merge_srv_conf)(ngx_conf_t *cf, void *prev, void *conf); /* 执行顺序6 */ void *(*create_loc_conf)(ngx_conf_t *cf); /* 执行顺序3 */
char *(*merge_loc_conf)(ngx_conf_t *cf, void *prev, void *conf); /* 执行顺序7 */
} ngx_http_module_t;
同时,还有个执行顺序4.:
struct ngx_command_s { /* 执行顺序4.5 */
ngx_str_t name;
ngx_uint_t type;
char *(*set)(ngx_conf_t *cf, ngx_command_t *cmd, void *conf);
ngx_uint_t conf;
ngx_uint_t offset;
void *post;
}; for (m = ; ngx_modules[m]; m++) {
if (module->create_main_conf) {ctx->main_conf[mi] = module->create_main_conf(cf);}
if (module->create_srv_conf) {ctx->srv_conf[mi] = module->create_srv_conf(cf);}
if (module->create_loc_conf) {ctx->loc_conf[mi] = module->create_loc_conf(cf);}
}
for (m = ; ngx_modules[m]; m++) {
if (module->preconfiguration) {if (module->preconfiguration(cf) != NGX_OK) {}
} rv = ngx_conf_parse(cf, NULL);
{
/*
* 指令的解析
* 共享内存配置相关的指令也在这里进行解析
* 详细见:
* ngx_shm_zone_t *
* ngx_shared_memory_add(ngx_conf_t *cf, ngx_str_t *name, size_t size, void *tag)
*/
} for (m = ; ngx_modules[m]; m++) {
if (module->init_main_conf) {rv = module->init_main_conf(cf, ctx->main_conf[mi]);}
rv = ngx_http_merge_servers(cf, cmcf, module, mi);
}
for (m = ; ngx_modules[m]; m++) {
if (module->postconfiguration) {if (module->postconfiguration(cf) != NGX_OK)}
}
}
} // in ngx_init_cycle(&init_cycle)
line: if (ngx_shm_alloc(&shm_zone[i].shm) != NGX_OK) /* 实际共享内存分配的地方 */
line: if (ngx_init_zone_pool(cycle, &shm_zone[i]) != NGX_OK)
/* 共享内存管理机制的初始化
* 共享内存的使用涉及另外两个主题:
* 1、多进程共同使用时之间的互斥问题
* 2、引入特定的使用方式(slab机制,这在下一个主题:“Nginx源码分析(2)之——共享内存管理之slab机制”中进行介绍),以提高性能
*/
line: if (shm_zone[i].init(&shm_zone[i], NULL) != NGX_OK) /* 分配之后的初始化 */
}
} ngx_shm_zone_t *
ngx_shared_memory_add(ngx_conf_t *cf, ngx_str_t *name, size_t size, void *tag)
{
ngx_uint_t i;
ngx_shm_zone_t *shm_zone;
ngx_list_part_t *part; /*
* Nginx中所有的共享内存都以list链表的形式组织在全局变量cf->cycle->shared_memory中
* 在创建新的共享内存之前,会对该链表进行遍历查找以及冲突检测,
* 对于已经存在且不存在冲突时,对共享内存直接进行返回并引用
* 存在且不存在冲突:共享内存的名称相同,大小相同,且tag指向的是同一个模块
* 有冲突,则报错
* 否则,重新分配ngx_shm_zone_t,并挂到全局链表cf->cycle->shared_memory中,最后进行结构初始化
* shm_zone = ngx_list_push(&cf->cycle->shared_memory);
* 至此:
* 仅仅是创建了共享内存的结构体:ngx_shm_zone_t,ngx_shm_zone_t.shm.addr指向的真实共享内存并没有进行实际的分配
*/
part = &cf->cycle->shared_memory.part;
shm_zone = part->elts; for (i = ; /* void */ ; i++) { if (i >= part->nelts) {
if (part->next == NULL) {
break;
}
part = part->next;
shm_zone = part->elts;
i = ;
} if (name->len != shm_zone[i].shm.name.len) {
continue;
} if (ngx_strncmp(name->data, shm_zone[i].shm.name.data, name->len)
!= )
{
continue;
} if (tag != shm_zone[i].tag) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, ,
"the shared memory zone \"%V\" is "
"already declared for a different use",
&shm_zone[i].shm.name);
return NULL;
} if (size && size != shm_zone[i].shm.size) {
ngx_conf_log_error(NGX_LOG_EMERG, cf, ,
"the size %uz of shared memory zone \"%V\" "
"conflicts with already declared size %uz",
size, &shm_zone[i].shm.name, shm_zone[i].shm.size);
return NULL;
} return &shm_zone[i];
} shm_zone = ngx_list_push(&cf->cycle->shared_memory); if (shm_zone == NULL) {
return NULL;
} shm_zone->data = NULL;
shm_zone->shm.log = cf->cycle->log;
shm_zone->shm.size = size;
shm_zone->shm.name = *name;
shm_zone->shm.exists = ;
shm_zone->init = NULL;
shm_zone->tag = tag; return shm_zone;
}
三、工作模型中的基础架构及原理
由master进程分配接到的任务给worker进程
1、惊群现象
主进程(master 进程)首先通过 socket() 来创建一个 sock 文件描述符用来监听,然后fork生成子进程(workers 进程),子进程将继承父进程的 sockfd(socket 文件描述符),之后子进程 accept() 后将创建已连接描述符(connected descriptor)),然后通过已连接描述符来与客户端通信。
那么,由于所有子进程都继承了父进程的 sockfd,那么当连接进来时,所有子进程都将收到通知并“争着”与它建立连接,这就叫“惊群现象”。大量的进程被激活又挂起,只有一个进程可以accept() 到这个连接,这当然会消耗系统资源。
2、锁机制
Nginx 提供了一个 accept_mutex 这个东西,这是一个加在accept上的一把互斥锁。即每个 worker 进程在执行 accept 之前都需要先获取锁,获取不到就放弃执行 accept()。有了这把锁之后,同一时刻,就只会有一个进程去 accpet(),这样就不会有惊群问题了。accept_mutex 是一个可控选项,我们可以显示地关掉,默认是打开的。
Nginx事件处理的入口函数是ngx_process_events_and_timers(),下面是部分代码,可以看到其加锁的过程:
if (ngx_use_accept_mutex) {
if (ngx_accept_disabled > ) {
ngx_accept_disabled--;
} else {
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
在ngx_trylock_accept_mutex()函数里面,如果拿到了锁,Nginx会把listen的端口读事件加入event处理,该进程在有新连接进来时就可以进行accept了。注意accept操作是一个普通的读事件。下面的代码说明了这点:
(void) ngx_process_events(cycle, timer, flags);
if (ngx_posted_accept_events) {
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
}
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
ngx_process_events()函数是所有事件处理的入口,它会遍历所有的事件。抢到了accept锁的进程跟一般进程稍微不同的是,它被加上了NGX_POST_EVENTS标志,也就是说在ngx_process_events() 函数里面只接受而不处理事件,并加入post_events的队列里面。直到ngx_accept_mutex锁去掉以后才去处理具体的事件。为什么这样?因为ngx_accept_mutex是全局锁,这样做可以尽量减少该进程抢到锁以后,从accept开始到结束的时间,以便其他进程继续接收新的连接,提高吞吐量。
ngx_posted_accept_events和ngx_posted_events就分别是accept延迟事件队列和普通延迟事件队列。可以看到ngx_posted_accept_events还是放到ngx_accept_mutex锁里面处理的。该队列里面处理的都是accept事件,它会一口气把内核backlog里等待的连接都accept进来,注册到读写事件里。
而ngx_posted_events是普通的延迟事件队列。一般情况下,什么样的事件会放到这个普通延迟队列里面呢?我的理解是,那些CPU耗时比较多的都可以放进去。因为Nginx事件处理都是根据触发顺序在一个大循环里依次处理的,因为Nginx一个进程同时只能处理一个事件,所以有些耗时多的事件会把后面所有事件的处理都耽搁了。
除了加锁,Nginx也对各进程的请求处理的均衡性作了优化,也就是说,如果在负载高的时候,进程抢到的锁过多,会导致这个进程被禁止接受请求一段时间。
比如,在ngx_event_accept函数中,有类似代码:
ngx_accept_disabled = ngx_cycle->connection_n /
- ngx_cycle->free_connection_n;
表明,当已使用的连接数占到在nginx.conf里配置的worker_connections总数的7/8以上时,ngx_accept_disabled为正,这时本worker将ngx_accept_disabled减1,而且本次不再处理新连接。
3、AIO(异步IO)
监听accept后建立的连接,对读写事件进行添加删除。事件处理模型和Nginx的非阻塞IO模型结合在一起使用。当IO可读可写的时候,相应的读写事件就会被唤醒,此时就会去处理事件的回调函数。
特别对于Linux,Nginx大部分event采用epoll EPOLLET(边沿触发)的方法来触发事件,只有listen端口的读事件是EPOLLLT(水平触发)。对于边沿触发,如果出现了可读事件,必须及时处理,否则可能会出现读事件不再触发,连接饿死的情况。
epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树),其工作流程分为三部分:
、调用 int epoll_create(int size)建立一个epoll对象,内核会创建一个eventpoll结构体,用于存放通过epoll_ctl()向epoll对象中添加进来的事件,这些事件都会挂载在红黑树中。
、调用 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event) 在 epoll 对象中为 fd 注册事件,所有添加到epoll中的事件都会与设备驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个sockfd的回调方法,将sockfd添加到eventpoll 中的双链表。
、调用 int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout) 来等待事件的发生,timeout 为 - 时,该调用会阻塞知道有事件发生
这样,注册好事件之后,只要有 fd 上事件发生,epoll_wait() 就能检测到并返回给用户,用户就能”非阻塞“地进行 I/O 了。
epoll() 中内核则维护一个链表,epoll_wait 直接检查链表是不是空就知道是否有文件描述符准备好了。(epoll 与 select 相比最大的优点是不会随着 sockfd 数目增长而降低效率,使用 select() 时,内核采用轮训的方法来查看是否有fd 准备好,其中的保存 sockfd 的是类似数组的数据结构 fd_set,key 为 fd,value 为 0 或者 1。)
能达到这种效果,是因为在内核实现中 epoll 是根据每个 sockfd 上面的与设备驱动程序建立起来的回调函数实现的。那么,某个 sockfd 上的事件发生时,与它对应的回调函数就会被调用,来把这个 sockfd 加入链表,其他处于“空闲的”状态的则不会。在这点上,epoll 实现了一个”伪”AIO。但是如果绝大部分的 I/O 都是“活跃的”,每个 socket 使用率很高的话,epoll效率不一定比 select 高(可能是要维护队列复杂)。
可以看出,因为一个进程里只有一个线程,所以一个进程同时只能做一件事,但是可以通过不断地切换来“同时”处理多个请求。
例子:Nginx 会注册一个事件:“如果来自一个新客户端的连接请求到来了,再通知我”,此后只有连接请求到来,服务器才会执行 accept() 来接收请求。又比如向上游服务器(比如 PHP-FPM)转发请求,并等待请求返回时,这个处理的 worker 不会在这阻塞,它会在发送完请求后,注册一个事件:“如果缓冲区接收到数据了,告诉我一声,我再将它读进来”,于是进程就空闲下来等待事件发生。
这样,基于 多进程+epoll, Nginx 便能实现高并发。
使用 epoll 处理事件的一个框架,代码转自:http://www.cnblogs.com/fnlingnzb-learner/p/5835573.html
for( ; ; ) // 无限循环
{
nfds = epoll_wait(epfd,events,,); // 最长阻塞 500s
for(i=;i<nfds;++i)
{
if(events[i].data.fd==listenfd) //有新的连接
{
connfd = accept(listenfd,(sockaddr *)&clientaddr, &clilen); //accept这个连接
ev.data.fd=connfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev); //将新的fd添加到epoll的监听队列中
}
else if( events[i].events&EPOLLIN ) //接收到数据,读socket
{
n = read(sockfd, line, MAXLINE)) < //读
ev.data.ptr = md; //md为自定义类型,添加数据
ev.events=EPOLLOUT|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);//修改标识符,等待下一个循环时发送数据,异步处理的精髓
}
else if(events[i].events&EPOLLOUT) //有数据待发送,写socket
{
struct myepoll_data* md = (myepoll_data*)events[i].data.ptr; //取数据
sockfd = md->fd;
send( sockfd, md->ptr, strlen((char*)md->ptr), ); //发送数据
ev.data.fd=sockfd;
ev.events=EPOLLIN|EPOLLET;
epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev); //修改标识符,等待下一个循环时接收数据
}
else
{
//其他的处理
}
}
}
参考:
http://blog.csdn.net/stfphp/article/details/52936490:初步探索Nginx高并发原理
https://www.cnblogs.com/linguoguo/p/5511293.html:Nginx工作原理和优化
http://blog.csdn.net/russell_tao/article/details/7204260:“惊群”,看看nginx是怎么解决它的
http://tengine.taobao.org/book/chapter_02.html:Nginx开发从入门到精通
Nginx随笔的更多相关文章
- Nginx 随笔
使用包管理工具安装nginx Linux(基于deb) sudo apt-get install nginx Linux(基于rpm) sudo yum install nginx FreeBSD s ...
- Ribbon负载均衡及其应用
nginx - 随笔分类 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中涉及到负载均衡,为何此处由涉及Ribbon负载均衡呢?那是因为ngnix是服务端的负责均衡,而Ribbon是客户 ...
- Nginx学习随笔
题外话 第一份工作中项目中有DBA和运维,所以平时也只关注开发部分,对数据库和服务器关注比较少,记得那时有用户反馈网站很慢,老大让我联系运维看看是不是服务器的问题,那时也不知道Nginx是个什么东西. ...
- 【随笔】nginx add_header指令的使用
nginx配置文件通过使用add_header指令来设置response header. 具体方法如下: add_header key value add_header Cache-Control n ...
- 【随笔】nginx重启问题和mysql挂了的解决办法
租了一个阿里云服务器,然后需要一个nginx来处理一下静态文件的访问和动态文件的转发,头一天没有什么问题,第二次打开,各种问题就出来了!解决方法记录一下.... Can't connect to lo ...
- 【随笔】nginx下的301跳转,两个域名指向同一个服务器ip
301跳转 页面永久性移走,通常叫做301跳转,也叫301重定向,301转向. 指的是当用户点击一个网址时,通过技术手段,跳转到指定的一个网站. 用以解决两个域名指向同一个服务器ip,当访问m.xxx ...
- Flutter随笔(二)——使用Flutter Web + Docker + Nginx打造一个简单的Web项目
前言 Flutter作为一个跨平台UI框架,功能十分强大,仅用一套代码便能编译出Android.iOS.Web.windows.macOS.Windows.Linux等平台上的应用,各平台应用体验高度 ...
- NGINX配置小随笔
达到以下效果: 1,特定目录被指定IP访问 2,不是指定的IP地址不能执行URI中特定字符串 3,特定目录中不能执行PHP文件 set $self_visit ''; if ( $request_ur ...
- 手把手教你玩转nginx负载均衡(四)--源码安装nginx
引言: 在上一篇,我们已经装好了虚拟机,并且已经配置好了网络,那么今天我们就要开始安装nginx服务器了. 安装工具以及过程 安装gcc编译套件以及nginx依赖模块 yum -y install g ...
随机推荐
- 支付宝支付-常用支付API详解(查询、退款、提现等)-转
所有的接口支持沙盒环境的测试 1.前言 前面几篇文件详细介绍了 支付宝提现.扫码支付.条码支付.Wap支付.App支付 支付宝支付-提现到个人支付宝 支付宝支付-扫码支付 支付宝支付-刷卡支付(条码支 ...
- SQLServer存储过程返回值总结
1. 存储过程没有返回值的情况(即存储过程语句中没有return之类的语句) 用方法 int count = ExecuteNonQuery(..)执行存储过程其返回值只有两种情况 (1)假如通 ...
- Java工程师成神之路 转
一.基础篇 1.1 JVM 1.1.1. Java内存模型,Java内存管理,Java堆和栈,垃圾回收 http://www.jcp.org/en/jsr/detail?id=133 http:/ ...
- GlobalGetAtomName GlobalDeleteAtom 引用 WinAPI: AddAtom、DeleteAtom、FindAtom、GetAtomName、GlobalAddAtom、GlobalDeleteAtom、GlobalFindAtom、GlobalGetAtomName
http://www.cnblogs.com/del/archive/2008/02/28/1085124.html 这是储存字符串的一组 API.通过 AddAtom 储存一个字符串, 返回一个 I ...
- Java 复制大文件方式(nio2 FileChannel 拷贝文件能力测试)
目前为止,我们已经学习了很多 Java 拷贝文件的方式,除了 FileChannel 提供的方法外,还包括使用 Files.copy() 或使用字节数组的缓冲/非缓冲流.那个才是最好的选择呢?这个问题 ...
- [Git] Git fetch和git pull的区别
reference : http://blog.csdn.net/hudashi/article/details/7664457 Git中从远程的分支获取最新的版本到本地有这样2个命令:1. git ...
- C错误异常处理,异常处理
预处理器标识#error的目的是什么啊? 指令 用途 # 空指令,无任何效果 #include 包含一个源代码文件 #define 定义宏 #undef 取消已定义的宏 #if 如果给定条件为真,则编 ...
- Yarn 详解
唐 清原, 咨询顾问 简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架 ...
- Python在Windows下操作CH341DLL
#! /usr/bin/env python #coding=utf-8 import os import time from ctypes import * class USBI2C(): ch34 ...
- 简单MapReduce思维导图