开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop、Spark、Hbase、Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索。
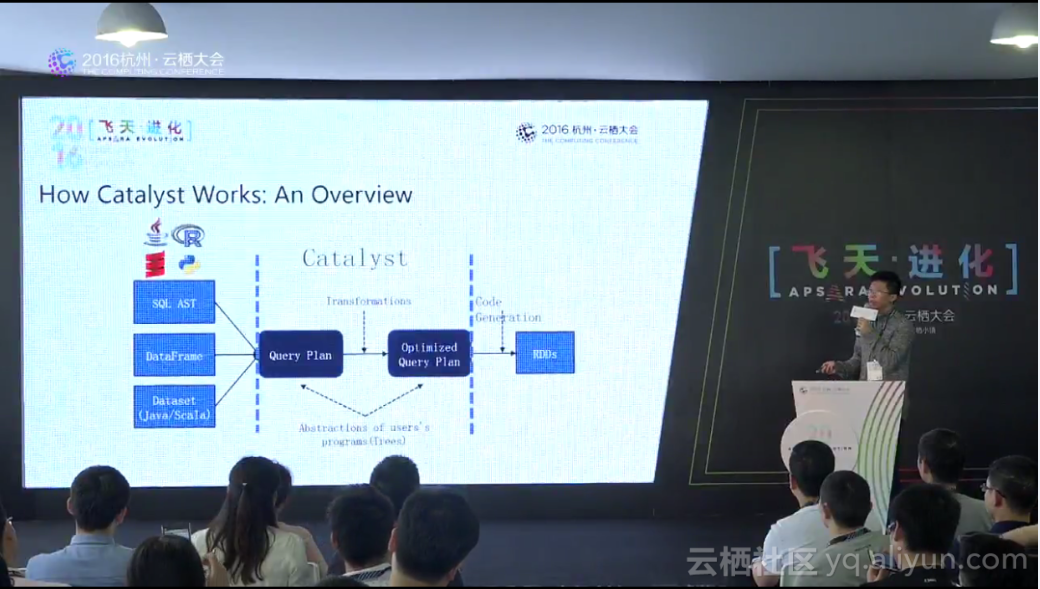
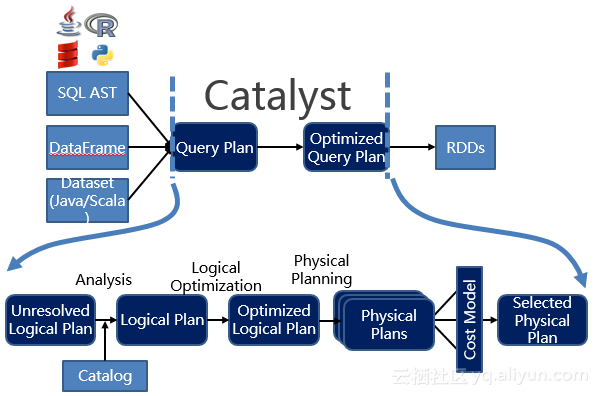
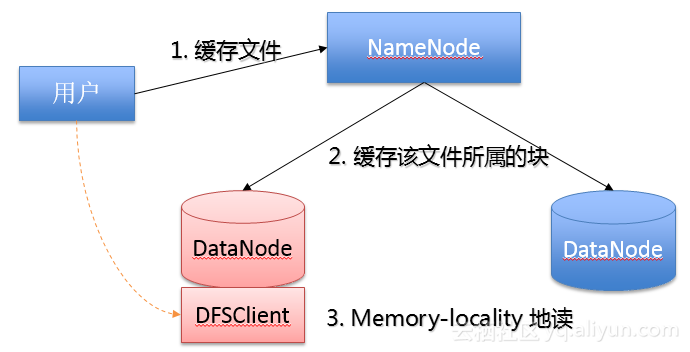
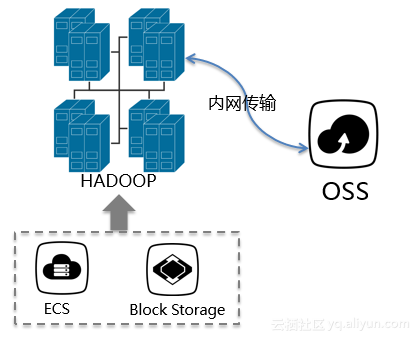
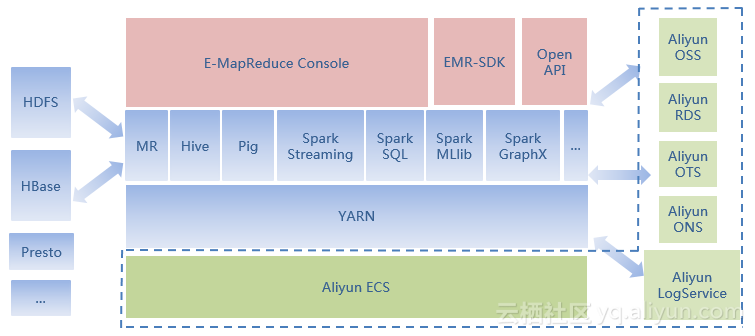
(2)HDFS HSM多层次存储体系:
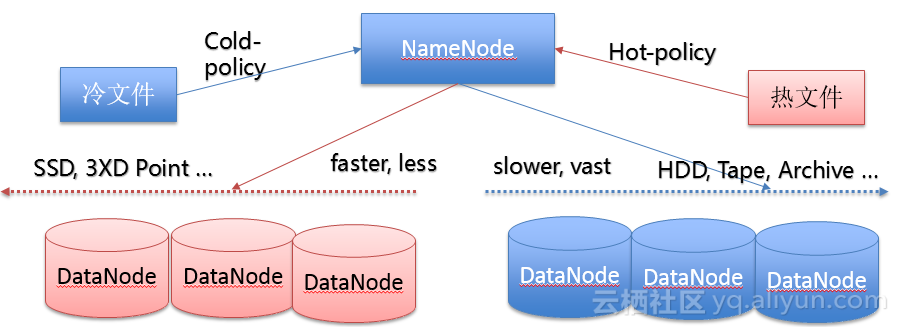
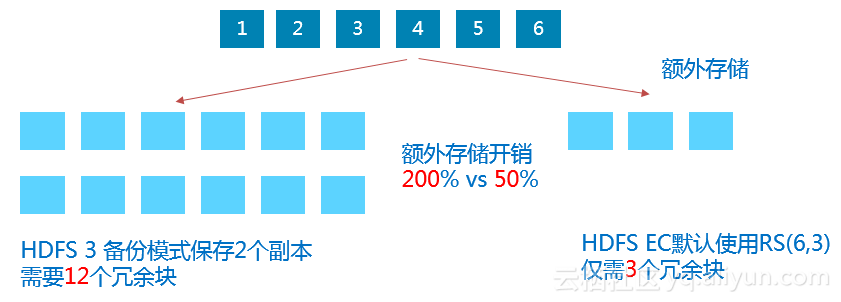
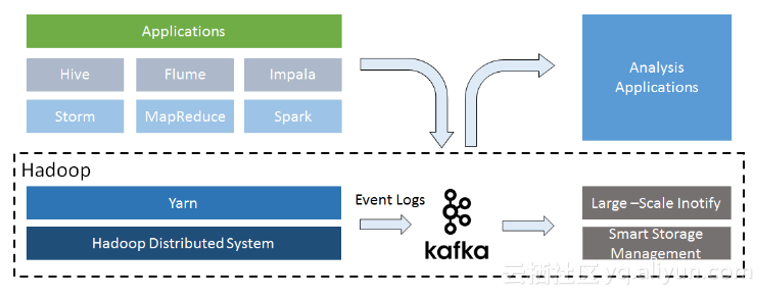
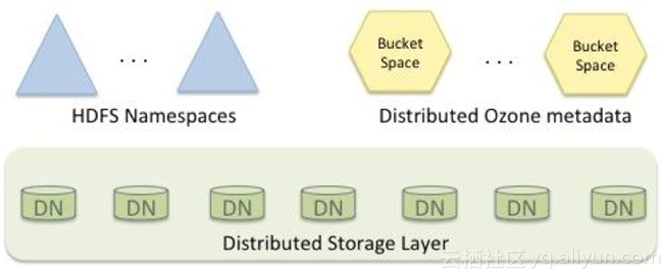

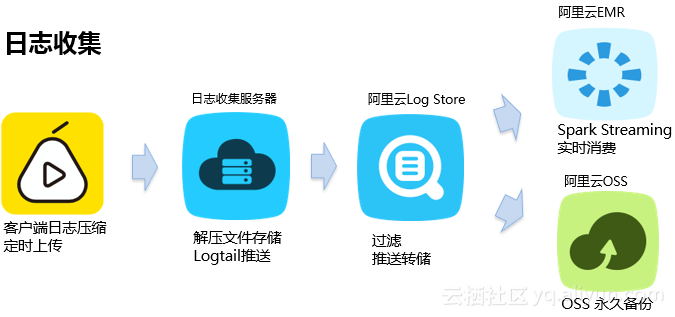
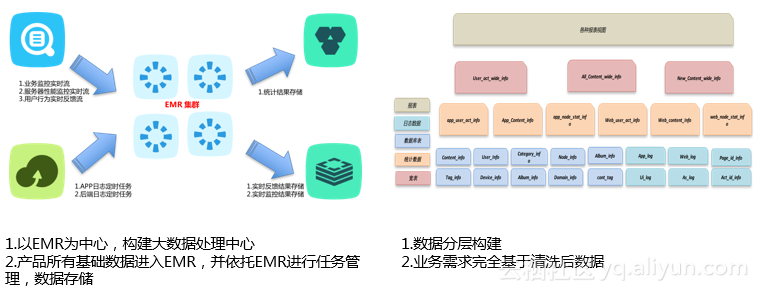

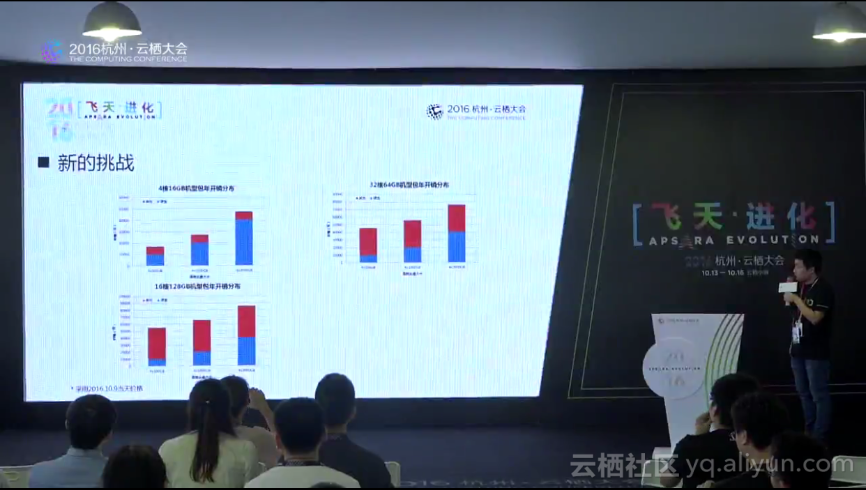
随后他提到了阿里云上的集群混合部署带来的新的挑战:1,冷数据不断积累,存储成本比较高;2,存储质量下降;3,数据Balance代价上升,集群维护成本也升高;4,数据服务性的要求越来越高。
开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践的更多相关文章
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- TOP100summit:【分享实录-WalmartLabs】利用开源大数据技术构建WMX广告效益分析平台
本篇文章内容来自2016年TOP100summitWalmartLabs实验室广告平台首席工程师.架构师粟迪夫的案例分享. 编辑:Cynthia 粟迪夫:WalmartLabs实验室广告平台首席工程师 ...
- 开源大数据引擎:Greenplum 数据库架构分析
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库.商务智能(OLAP)和数据挖掘等.自2015年10月正式开源以来,受到国内外业内人士的广泛关注 ...
- 思迈特软件Smartbi:利用大数据为产业赋能,且看这家风电巨头的实践之路!
随着大数据技术成为各行各业转型升级的"新动能",数字化风电.智慧风电场也成为风电行业的高频词,大数据已经逐渐被用于风场从测风到运维的各个环节. Smartbi的某客户是国内风电装备 ...
- 构建AR视频空间大数据平台(物联网及工业互联网、视频、AI场景识别)
目 录 1. 应用背景... 2 2. 系统框架... 2 3. AI场景识别算法和硬件... 3 4. AR视频空间管理系统... 5 5. ...
- 零基础学习云计算及大数据DBA集群架构师【企业级运维技术及实践项目2015年1月29日周五】
LNMP/LEMP项目搭建 { 项目框架 # Linux_____WEB_____PHP_____DB # rhel7_____apache__-(libphp5.so)-__php__-(php-m ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- 零基础大数据入门教程:Java调用阿里云短信通道服务
这里我们使用SpringBoot 来调用阿里通信的服务. 阿里通信,双11.收到短信,日发送达6亿条.保障力度非常高. 使用的步骤: 1.1. 第一步:需要开通账户 1.2. 第二步:阅读接口文档 1 ...
随机推荐
- 算法:快速排序(Quick Sort)
算法定义 目前学习是五种排序(冒泡.插入.选择.合并.快速)中,快速排序是最让我喜欢的算法(因为我想不到),其定义如下: 随机的从数组中选择一个元素,如:item. 对数组进行分区,将小于等于 ite ...
- appium+python自动化53-adb logcat查看日志
前言 做app测试,遇到异常情况,查看日志是必不可少的,日志如何输出到手机sdcard和电脑的目录呢?这就需要用logcat输出日志了 以下操作是基于windows平台的操作:adb logcat | ...
- Android之在Tab更新两个ListView,让一个listview有按下另个一个listview没有的效果
直接上代码,不说了 UpdateListViewItem.zip
- c++反汇编与逆向分析 小结
第一章 熟悉工作环境和相关工具 1.1 熟悉OllyDBG 操作技巧 1.2 反汇编静态分析工具 IDA(最专业的逆向工具) 快捷键 功能 Enter 跟进函数实现 ...
- WebService—CXF整合Spring实现接口发布和调用过程
一.CXF整合Spring实现接口发布 发布过程如下: 1.引入jar包(基于maven管理) <!-- cxf --> <dependency> <groupId> ...
- 混沌数学之Henon吸引子
Henon吸引子是混沌与分形的著名例子. 相关软件:混沌数学及其软件模拟相关代码: // http://wenku.baidu.com/view/d51372a60029bd64783e2cc0.ht ...
- 【Todo】React & Nodejs学习 &事件驱动,非阻塞IO & JS知识栈:Node为主,JQuery为辅,Bootstrap & React为辅辅,其他如Angular了解用途即可
JS知识栈:Node为主,JQuery为辅,Bootstrap & React为辅辅,其他如Angular了解用途即可 今天在学习ReactJS和NodeJS,看到关于ReactJS的这篇文章 ...
- linux C 多线程/线程池编程 同步实例
在多线程.线程池编程中经常会遇到同步的问题. 1.创建线程 函数原型:int pthread_create(pthread_t *thread, const pthread_attr_t *attr, ...
- Android 时间日期Widget 开发详解
桌面Widget其实就是一个显示一些信息的工具(现在也有人开发了一些有实际操作功能的widget.例如相机widget,可以直接桌面拍照).不过总的来说,widget主要功能就是显示一些信息.我们今天 ...
- N-Queens II leetcode java
题目: Follow up for N-Queens problem. Now, instead outputting board configurations, return the total n ...