大数据入门第十天——hadoop高可用HA
一、HA概述
1.引言
正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制
2.运行机制
实现高可用最关键的是消除单点故障
hadoop-ha严格来说应该分成各个组件的HA机制——HDFS的HA、YARN的HA
详解:
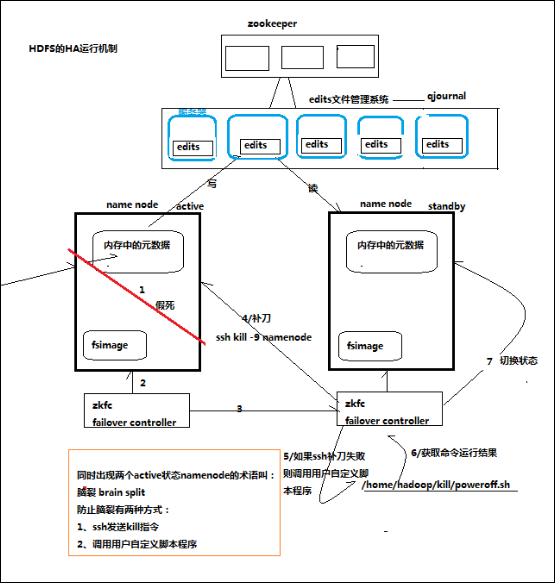
通过双namenode消除单点故障
双namenode协调工作的要点:
A、元数据管理方式需要改变:
内存中各自保存一份元数据
Edits日志只能有一份,只有Active状态的namenode节点可以做写操作
两个namenode都可以读取edits
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)
B、需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点
每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识
当需要进行状态切换时,由zkfailover来负责切换
切换时需要防止brain split现象的发生
原理图:
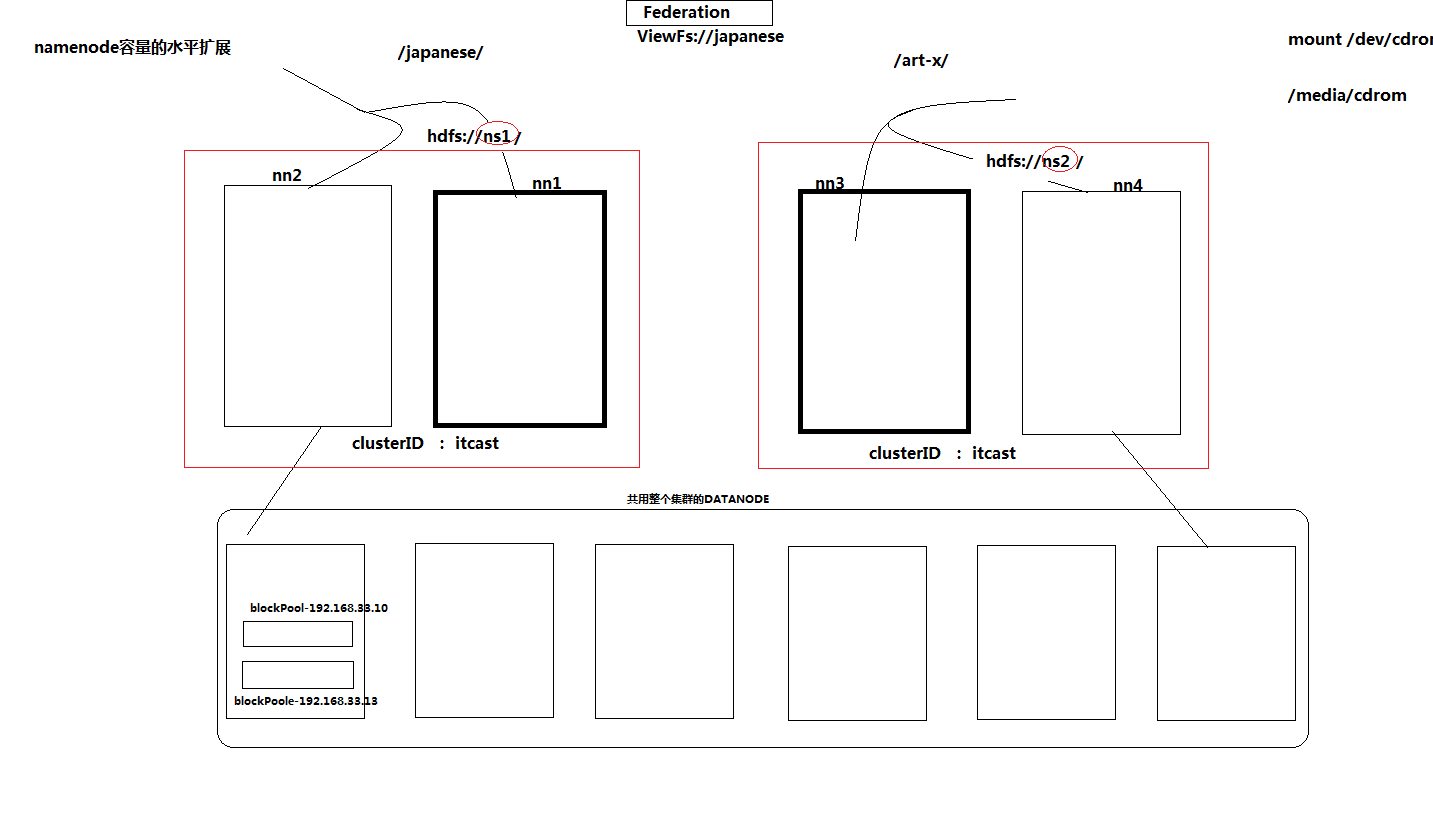
3.水平拓展namenode的联邦机制
4.高可用的解决方案
从官网介绍来看,主要有2种:
5.更多参考
完整介绍与实践,参考:http://blog.csdn.net/bingduanlbd/article/details/51946540
二、实践配置
完整流程:
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA、YARN等。最新的hadoop-2.6.4又增加了YARN HA 注意:apache提供的hadoop-2.6.4的安装包是在32位操作系统编译的,因为hadoop依赖一些C++的本地库,
所以如果在64位的操作上安装hadoop-2.6.4就需要重新在64操作系统上重新编译
(建议第一次安装用32位的系统,我将编译好的64位的也上传到群共享里了,如果有兴趣的可以自己编译一下) 前期准备就不详细说了,课堂上都介绍了
.修改Linux主机名
.修改IP
.修改主机名和IP的映射关系 /etc/hosts
######注意######如果你们公司是租用的服务器或是使用的云主机(如华为用主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
.关闭防火墙
.ssh免登陆
.安装JDK,配置环境变量等 集群规划:
主机名 IP 安装的软件 运行的进程
mini1 192.168.1.200 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
mini2 192.168.1.201 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
mini3 192.168.1.202 jdk、hadoop ResourceManager
mini4 192.168.1.203 jdk、hadoop ResourceManager
mini5 192.168.1.205 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
mini6 192.168.1.206 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
mini7 192.168.1.207 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain 说明:
.在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态
.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.6.4解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
安装步骤:
.安装配置zooekeeper集群(在hadoop05上)
.1解压
tar -zxvf zookeeper-3.4..tar.gz -C /home/hadoop/app/
.2修改配置
cd /home/hadoop/app/zookeeper-3.4./conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=/home/hadoop/app/zookeeper-3.4./tmp
在最后添加:
server.=hadoop05::
server.=hadoop06::
server.=hadoop07::
保存退出
然后创建一个tmp文件夹
mkdir /home/hadoop/app/zookeeper-3.4./tmp
echo > /home/hadoop/app/zookeeper-3.4./tmp/myid
.3将配置好的zookeeper拷贝到其他节点(首先分别在hadoop06、hadoop07根目录下创建一个hadoop目录:mkdir /hadoop)
scp -r /home/hadoop/app/zookeeper-3.4./ hadoop06:/home/hadoop/app/
scp -r /home/hadoop/app/zookeeper-3.4./ hadoop07:/home/hadoop/app/ 注意:修改hadoop06、hadoop07对应/hadoop/zookeeper-3.4./tmp/myid内容
hadoop06:
echo > /home/hadoop/app/zookeeper-3.4./tmp/myid
hadoop07:
echo > /home/hadoop/app/zookeeper-3.4./tmp/myid .安装配置hadoop集群(在hadoop00上操作)
.1解压
tar -zxvf hadoop-2.6..tar.gz -C /home/hadoop/app/
.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1..0_55
export HADOOP_HOME=/hadoop/hadoop-2.6.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin #hadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.6./etc/hadoop 2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1..0_55 ############################################################################### 2.2.2修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bi/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hdpdata/</value>
</property> <!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>mini5:,mini6:,mini7:</value>
</property>
</configuration> ############################################################################### 2.2.3修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>bi</value>
</property>
<!-- bi下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.bi</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.bi.nn1</name>
<value>mini1:</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bi.nn1</name>
<value>mini1:</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.bi.nn2</name>
<value>mini2:</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.bi.nn2</name>
<value>mini2:</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://mini5:8485;mini6:8485;mini7:8485/bi</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.bi</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value></value>
</property>
</configuration> ############################################################################### 2.2.4修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> ############################################################################### 2.2.5修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>mini3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>mini4</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>mini5:,mini6:,mini7:</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 2.2.6修改slaves(slaves是指定子节点的位置,因为要在hadoop01上启动HDFS、在hadoop03启动yarn,所以hadoop01上的slaves文件指定的是datanode的位置,hadoop03上的slaves文件指定的是nodemanager的位置)
mini5
mini6
mini7 2.2.7配置免密码登陆
#首先要配置hadoop00到hadoop01、hadoop02、hadoop03、hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop01上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点,包括自己
ssh-coyp-id hadoop00
ssh-coyp-id hadoop01
ssh-coyp-id hadoop02
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07
#配置hadoop02到hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop02上生产一对钥匙
ssh-keygen -t rsa
#将公钥拷贝到其他节点
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07
#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置hadoop01到hadoop00的免登陆
在hadoop01上生产一对钥匙
ssh-keygen -t rsa
ssh-coyp-id -i hadoop00 .4将配置好的hadoop拷贝到其他节点
scp -r /hadoop/ hadoop02:/
scp -r /hadoop/ hadoop03:/
scp -r /hadoop/hadoop-2.6./ hadoop@hadoop04:/hadoop/
scp -r /hadoop/hadoop-2.6./ hadoop@hadoop05:/hadoop/
scp -r /hadoop/hadoop-2.6./ hadoop@hadoop06:/hadoop/
scp -r /hadoop/hadoop-2.6./ hadoop@hadoop07:/hadoop/ ###注意:严格按照下面的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
.5启动zookeeper集群(分别在mini5、mini6、mini7上启动zk)
cd /hadoop/zookeeper-3.4./bin/
./zkServer.sh start
#查看状态:一个leader,两个follower
./zkServer.sh status .6启动journalnode(分别在在mini5、mini6、mini7上执行)
cd /hadoop/hadoop-2.6.
sbin/hadoop-daemon.sh start journalnode
#运行jps命令检验,hadoop05、hadoop06、hadoop07上多了JournalNode进程 .7格式化HDFS
#在mini1上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/hadoop/hadoop-2.6./tmp,然后将/hadoop/hadoop-2.6./tmp拷贝到hadoop02的/hadoop/hadoop-2.6./下。
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.6./
##也可以这样,建议hdfs namenode -bootstrapStandby .8格式化ZKFC(在mini1上执行一次即可)
hdfs zkfc -formatZK .9启动HDFS(在mini1上执行)
sbin/start-dfs.sh .10启动YARN(#####注意#####:是在hadoop02上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh 到此,hadoop-2.6.4配置完毕,可以统计浏览器访问:
http://hadoop00:50070
NameNode 'hadoop01:9000' (active)
http://hadoop01:50070
NameNode 'hadoop02:9000' (standby) 验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill - <pid of NN>
通过浏览器访问:http://192.168.1.202:50070
NameNode 'hadoop02:9000' (active)
这个时候hadoop02上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r--r-- root supergroup -- : /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'hadoop01:9000' (standby) 验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4..jar wordcount /profile /out OK,大功告成!!! 测试集群工作状态的一些指令 :
bin/hdfs dfsadmin -report 查看hdfs的各节点状态信息 bin/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态 sbin/hadoop-daemon.sh start namenode 单独启动一个namenode进程 ./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
搭建HA
完整过程,参考:https://www.cnblogs.com/yxysuanfa/p/7105180.html
配置,参考 http://linxiao.iteye.com/blog/2271362
大数据入门第十天——hadoop高可用HA的更多相关文章
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据学习(7)Hadoop高可用
HDFS高可用 通过主从切换实现单NameNode高可用.通过Federation:水平扩展来联合多NameNode个: NameNode高可用 把edits日志从原来的nameNode中分离出来,存 ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十六天——流式计算之storm详解(二)常用命令与wc实例
一.常用命令 1.提交命令 提交任务命令格式:storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称] torm jar examples/storm-starter/storm-st ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
随机推荐
- leetCode题解之寻找插入位置
1.问题描述 Search Insert Position Given a sorted array and a target value, return the index if the targe ...
- 关于sys CPU usage 100%问题的分析
最近一个客户抱怨他的核心EBS数据库出现性能问题.这是一个10.2.0.3的数据库,运行在Red Hat Enterprise Linux Server release 5.5 (Linux x86- ...
- MySQL Flashback 工具介绍
MySQL Flashback 工具介绍 DML Flashback 独立工具,通过伪装成slave拉取binlog来进行处理 MyFlash 「大众点点评」 binlog2sql 「大众点评(上海) ...
- Azure Document DB 存储过程、触发器、自定义函数的实现
阅读 大约需要 4 分钟 在上一篇随笔中记录的是关于Azure Cosmos DB 中SQL API (DocumentDB) 的简介和Repository 的实现.本随笔是Document DB 中 ...
- swift关于UIView设置frame值的extension
swift关于UIView设置frame值的extension 使用 说明 1. 使用如上图,很简单,不再赘述 2. 在extension给添加的计算属性提供getter,setter方法即可 源码 ...
- url用法
url中的name用法: 0.定义主rul.py urlpatterns = [ url(r'^sinfors/', include('sinfors.urls', namespace="s ...
- Python入门-模块4(序列化----json模块和pickle模块)
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes.反之,把硬盘里面的数据读到内存里,叫反序列化.
- python---九九乘法表代码
#_*_ coding:utf-8 _*_# author choco ''' #while循环num1=0while num1<9: num1+=1 num2=1 while num2< ...
- 激活office软件
1. 打开校园软件正版化激活网址 http://nic.seu.edu.cn/2015/0113/c12333a115290/page.htm 2. 下载KMS激活脚本 3. 登陆easyconnec ...
- python pandas dataframe 操作记录
从数据看select出数据后如何转换为dataframe df = DataFrame(cur.fetchall()) 如何更改列名,选取列,进行groupby操作 df.columns = ['me ...