使用SGD(Stochastic Gradient Descent)进行大规模机器学习
原贴地址:http://fuliang.iteye.com/blog/1482002
其它参考资料:http://en.wikipedia.org/wiki/Stochastic_gradient_descent
1. 基于梯度下降的学习
对于一个简单的机器学习算法,每一个样本包含了一个(x,y)对,其中一个输入x和一个数值输出y。我们考虑损失函数 ,它描述了预测值
,它描述了预测值 和实际值y之间的损失。预测值是我们选择从一函数族F中选择一个以w为参数的函数
和实际值y之间的损失。预测值是我们选择从一函数族F中选择一个以w为参数的函数 的到的预测结果。
的到的预测结果。
我们的目标是寻找这样的函数 ,能够在训练集中最小化平均损失函数 :
,能够在训练集中最小化平均损失函数 : 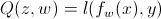
由于我们不知道数据的真实分布,所以我们通常使用 
来代替 
经验风险 用来衡量训练集合的效果。期望风险E(f)描述了泛化(generation)的效果,预测未知样例的能力。
用来衡量训练集合的效果。期望风险E(f)描述了泛化(generation)的效果,预测未知样例的能力。
如果函数族F进行足够的限制(sufficiently restrictive ),统计机器学习理论使用经验风险来代替期望风险。
1.1 梯度下降
我们经常使用梯度下降(GD)的方式来最小化期望风险,每一次迭代,基于 更新权重w:
更新权重w:  ,
, 为学习率,如果选择恰当,初始值选择合适,这个算法能够满足线性的收敛。也就是:
为学习率,如果选择恰当,初始值选择合适,这个算法能够满足线性的收敛。也就是: ,其中
,其中 表示残余误差(residual error)。
表示残余误差(residual error)。
基于二阶梯度的比较出名的算法是牛顿法,牛顿法可以达到二次函数的收敛。如果代价函数是二次的,矩阵 是确定的,那么这个算法可以一次迭代达到最优值。如果足够平滑的话,
是确定的,那么这个算法可以一次迭代达到最优值。如果足够平滑的话, 。但是计算需要计算偏导hession矩阵,对于高维,时间和空间消耗都是非常大的,所以通常采用近似的算法,来避免直接计算hession矩阵,比如BFGS,L-BFGS。
。但是计算需要计算偏导hession矩阵,对于高维,时间和空间消耗都是非常大的,所以通常采用近似的算法,来避免直接计算hession矩阵,比如BFGS,L-BFGS。
1.2 随机梯度下降
SGD是一个重要的简化,每一次迭代中,梯度的估计并不是精确的计算 ,而是基于随即选取的一个样例
,而是基于随即选取的一个样例 :
: 
随机过程
依赖于每次迭代时随即选择的样例,尽管这个简化的过程引入了一些噪音,但是我们希望他的表现能够和GD的方式一样。
随机算法不需要记录哪些样例已经在前面的迭代过程中被访问过,有时候随机梯度下降能够直接优化期望风险,因为样例可能是随机从真正的分布中选取的。
随机梯度算法的收敛性已经在随机近似算法的论文所讨论。收敛性要满足:  并且
并且
二阶随机梯度下降: 
这种方法并没有减少噪音,也不会对计算 有太大改进。
有太大改进。
1.3 随即梯度的一些例子
下面列了一些比较经典的机器学习算法的随机梯度, 
使用SGD(Stochastic Gradient Descent)进行大规模机器学习的更多相关文章
- 逻辑回归:使用SGD(Stochastic Gradient Descent)进行大规模机器学习
Mahout学习算法训练模型 mahout提供了许多分类算法,但许多被设计来处理非常大的数据集,因此可能会有点麻烦.另一方面,有些很容易上手,因为,虽然依然可扩展性,它们具有低开销小的数据集.这样一个 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- Stochastic Gradient Descent
一.从Multinomial Logistic模型说起 1.Multinomial Logistic 令为维输入向量; 为输出label;(一共k类); 为模型参数向量: Multinomial Lo ...
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 基于baseline和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.1 部分内容(其余部分会陆续补充上来). koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文 ...
- Stochastic Gradient Descent 随机梯度下降法-R实现
随机梯度下降法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 批量梯度下降法在权值更新前对所有样本汇总 ...
- Stochastic Gradient Descent收敛判断及收敛速度的控制
要判断Stochastic Gradient Descent是否收敛,可以像Batch Gradient Descent一样打印出iteration的次数和Cost的函数关系图,然后判断曲线是否呈现下 ...
- 基于baseline、svd和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.3部分内容(其余部分会陆续补充上来).koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文章目 ...
随机推荐
- Web安全漏洞深入分析及其安全编码
摘自:http://blog.nsfocus.net/web-vulnerability-analysis-coding-security/ 超全Web漏洞详解及其对应的安全编码规则,包括:SQL注入 ...
- 前端安全系列之二:如何防止CSRF攻击?
背景 随着互联网的高速发展,信息安全问题已经成为企业最为关注的焦点之一,而前端又是引发企业安全问题的高危据点.在移动互联网时代,前端人员除了传统的 XSS.CSRF 等安全问题之外,又时常遭遇网络劫持 ...
- python 与 mongodb的交互---查找
python与mongo数据库交互时,在查找的时候注意的一些小问题: 代码: from pymongo import * def find_func(): #创建连接对象 client = Mongo ...
- 出现报错: module build failed error couldn't find preset es2015 relative to directory
当用webpack 进行 build 的时候, 会出现如上标题的错误, 解决方式是在 上级 或者 上上级目录,删除 .babelrc 文件
- Python进阶篇:Python简单爬虫
目录 前言 要解决的问题 设计方案 代码说明 小结 前言 前一段一直在打基础,已经学习了变量,流程控制,循环,函数这几块的知识点,就想通过写写小程序来实践一下,来加深知识点的记忆和理解.首先考虑的就是 ...
- Java重写、重载与覆盖
Java继承.重载与重写 一.继承(单继承) 1.利用extends关键字一个方法继承另一个方法,而且只能直接继承一个类. 2.当Sub类和Base类在同一个包时,Sub类继承Base类中的publi ...
- 4040 EZ系列之奖金
4040 EZ系列之奖金 时间限制: 1 s 空间限制: 64000 KB 题目等级 : 钻石 Diamond 题目描述 Description 由于无敌的WRN在2015年世界英俊帅气男总决选中 ...
- 【MPI】并行奇偶交换排序
typedef long long __int64; #include "mpi.h" #include <cstdio> #include <algorithm ...
- 【对比分析六】JavaScript中GET和POST的区别及使用场景
区别: GET:一般用于信息获取,使用URL传递参数,对所发送信息的数量也有限制,一般在2000个字符 POST:一般用于修改服务器上的资源,对所发送的信息没有限制 GET方式需要使用 Request ...
- 一行代码提取url中querystring的某个key的值
var itemdata = "OrderFilter=0&ProjectTag=15&DateType=0"; var projectTag = itemdata ...