JDK源码分析(三)——HashMap 上(基于JDK7)
HashMap概述
前面我们分析了基于数组实现的ArrayList和基于双向链表实现的LinkedList,它们各有优缺点:ArrayList查找元素快但是插入删除元素慢,LinkedList插入删除元素快但是查找元素慢。那么有没有一种数据对象能够做到高效的查询和插入删除呢?答案是有的,HashMap就能够很好的满足这个特性。
由于JDK1.8对HashMap进行了优化,与JDK1.7版本的实现有很大的不同,相对来说也要负责一些,故本文以JDK1.7版本的HashMap为基础进行分析,主要分析HashMap的内部结构及插入扩容原理;将在下一篇文章分析JDK1.8版本的HashMap带来了那些改进和优化。
JDK api是这样介绍HashMap的:
Hash table based implementation of the Map interface. This implementation provides all of the optional map operations, and permits null values and the null key. (The HashMap class is roughly equivalent to Hashtable, except that it is unsynchronized and permits nulls.) This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time.
大意是HashMap是基于哈希表对Map接口的实现,此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了是线程不安全的和允许null键值对插入,HashMap大致等同于HashTable),HashMap不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap数据结构
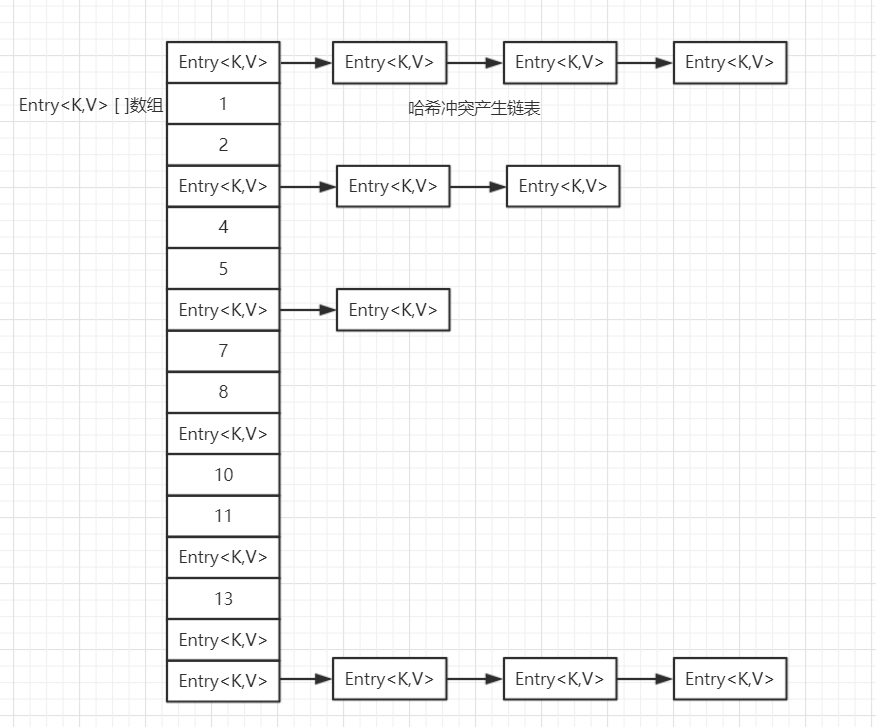
画了个示意图如下,由图可知,HashMap基于数组和单链表实现。使用过HashMap都知道,它储存的是键值对,当我们存储键值对时,先根据哈希算法计算出哈希值,根据计算出来的哈希值映射到数组上得到一个索引,可能会有多个对象映射到同一个索引上,就是图片上出现单链表的情况,这时候就产生了哈希冲突,一个好的算法能够尽量避免哈希冲突。根据哈希值,HashMap能够以几乎O(1)的复杂度存储或查询元素,效率相当高。
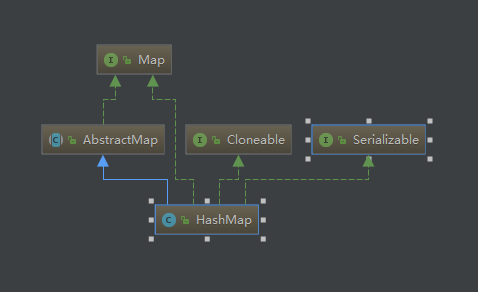
HashMap继承结构
HashMap 继承了 AbstractMap 类,并实现了 Map、Cloneable 和 Serializable 接口。AbstractMap提供了Map接口的抽象实现,并提供了一些方法的基本实现。注意,Map接口属于集合框架,但并没有继承 Collection 接口,实际上Map接口是与Collection接口同级别的接口。
内部字段及构造方法
Entry类
键值对Entry对象存储了键值对key-value,这里的next属性指向发生哈希冲突了的键值对对象。
static class Entry<K,V> implements Map.Entry<K,V> {
//键对象,final修饰,不可变
final K key;
//值对象
V value;
//下一个键值对Entry对象
Entry<K,V> next;
//键对象的哈希值
int hash;
//提供了一个有参构造方法
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
字段属性
HashMap的底层是由数组和链表实现的,JDK注释中把Entry数组称为桶,这里规定了桶的默认容量和最大容量。对于桶的容量JDK官方注释都会有这么一句:MUST be a power of two,桶的容量一定要是2的幂次,这里先说结论:桶的容量是2的N次方能够减少哈希冲突,提高桶的利用率,至于原因我们会在后面分析。
加载因子loadFactor和阈值threshold是一对密不可分的概念,在当前桶的容量下,存储键值对个数超过threshold就会进行扩容,阈值threshold等于桶的容量乘以加载因子;加载因子一般我们就用默认的0.75f,加载因子设置的太小,桶的利用率低,而且频繁扩容也会降低HashMap的性能,设置的加载因子太大,键值对越存越多容易发生哈希冲突,所以0.75是时间复杂度与空间复杂度的一个平衡点。
//桶的初始化默认的长度
static final int DEFAULT_INITIAL_CAPACITY = 16;
//桶的最大长度
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//Entry数组,空桶
transient Entry<K,V>[] table;
//储存元素个数
transient int size;
//桶内存储键值对个数的阈值,超过阈值对桶进行resize
int threshold;
//加载因子
final float loadFactor;
//确保fail-fast机制
transient int modCount;
// 备选的负载值,以String作为Key时的备选负载值。
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
构造方法
我们常用的雾草构造器,会调用的HashMap(int initialCapacity, float loadFactor)构造方法,按照默认初始容量为16,加载因子为0.75构造HashMap对象。
public HashMap(int initialCapacity, float loadFactor) {
//检查参数有效性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
//注意这个容量并不是直接用输入的参数,而是通过循环左移找到比initialCapacity
//且离它最近的2的幂次。如输入12,容量初始化为16
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
//阈值等于桶的容量乘以加载因子(不超过最大容量)
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
//空方法
init();
}
//生成一个空的HashMap,容量大小使用默认值16,负载因子使用默认值0.75
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
//生成一个空的HashMap,并指定其容量大小,负载因子使用默认的0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(Map<? extends K, ? extends V> m) {
//实际容量为m.size/0.75和16较大者,0.75f作为加载因子
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将传入的子Map中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}
存储元素
put(K key, V value)
put(K key, V value)方法将传入的键值对存到HashMap中,如果HashMap存在键相同的键值对,就将这个键值对覆盖,返回被覆盖键值对的值。首先检查键值对的键是否为null,是的话调用putForNullKey方法。如果不是通过hash方法得到键key的值,通过indexFor方法得到键值对映射到桶的索引,在得到了这个索引后,使用for循环去这个索引找这个桶里是否已经存放了键值对,如果已经有键值对,就对这个单向链表遍历,看是否有键值对的键与传入的key相同,判断条件:e.hash == hash && ((k = e.key) == key || key.equals(k)),找到了就替换,找不到调用addEntry方法插入到桶中。
通过以上分析,HashMap在发生了哈希冲突后是以链表的形式仍然保存到桶中,就是我们俗称的拉链法。对于这里的哈希冲突指的是键值对键的哈希值通过indexFor方法得到一个索引值(其实就是哈希值对桶的容量取余),放到同一个桶的键值对并不一定哈希值就相等,但哈希值相等一定会放到同一个桶中。当然我会在indexFor这个方法分析的,putForNullKey方法与put方法流程大致相同,只不过null的哈希值不需要计算,直接规定为0。
indexFor方法传入键的哈希值和桶的容量,那么是怎么映射得到在桶中的索引呢?其实就一句话:h & (length-1)。注意length一定是2的幂次,我们假设为16,那么哈希值就要与15每一位相与,15的二进制形式为1111,就相当于保留哈希值第一位到第四位,就是哈希值与16取余的效果。而桶的容量始终为2的幂次,那么哈希值都要与每一位都是一的二进制做&
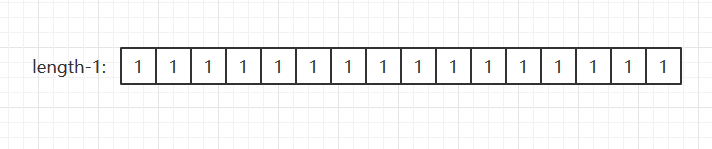
即相当于:h%length,所以发生哈希冲突并不代表哈希值相同,只是哈希值与桶的容量取余的所得到的索引相同
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
//如果table[i]这个桶中存放有元素,查找有没有含有键为key的键值对,
//存在则替换
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//桶中不存在指定键,则调用addEntry方法添加向桶中添加新结点
addEntry(hash, key, value, i);
return null;
}
private V putForNullKey(V value) {
//如果有key为null的键值对,替换值
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//桶中不存在null键,则调用addEntry方法添加向桶中添加新结点
addEntry(0, null, value, 0);
return null;
}
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
//一次散列,调用k的hashCode方法,与hashSeed做异或操作
h ^= k.hashCode();
//二次散列
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果HashMap中条目的数量达到了重构阈值且指定的桶不为null,则对HashMap进行扩容(即增加桶的数量)
if ((size >= threshold) && (null != table[bucketIndex])) {
//调用resize方法对HashMap进行扩容
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
//桶的数量增加,重新计算索引
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
//保存桶中已有元素e
Entry<K,V> e = table[bucketIndex];
//新元素插入桶中,把next指向
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
putAll(Map<? extends K, ? extends V> m)
构造方法HashMap(Map<? extends K, ? extends V> m)调用的是putAll方法,putAll方法把传入的Map对象保存的元素插入到HashMap里面。
public void putAll(Map<? extends K, ? extends V> m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
//如果Map包含的键值对个数大于thrshold,先扩容
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
//调用put方法将键值对放入HashMap总
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
put(e.getKey(), e.getValue());
}
扩容
resize(int newCapacity)
risize扩容方法没有访问修饰符修饰,我们在外部是无法调用的。每次扩容在以前的容量的基础上扩大两倍(从addEntry方法可以看出),扩容分为两部,构建一个新的Entry数组(桶),调用transfer方法将老数组oldTable的数据转移到新数组newTable中。
transfer源码如下,for循环遍历每一个桶,while循环遍历桶中链表,如果桶中键值对e不为空(e!=null),先保存e的下一个键值对next,重新计算e的索引,把e的next指向整个newTable[i]保存的数据,在把e放到新的桶中,下面table[0]元素转移到新桶做了简单的图帮助理解:

由于新插入的元素e的next指向桶中元素,所以新的桶中的元素顺序会倒过来。其实这个图并不严谨,因为元素从旧桶转移到新桶会按照新桶的容量重新计算索引,所以老桶中table[0]并不一定会被映射到新桶的table[0]。
可以看到,HashMap使用riseize扩容,在原来的容量基础上扩大两倍,对原来每一个键值对键重新计算哈希值和索引,然后再移到新桶中,这是很消耗性能的。另外,由于HashMap是线程不安全的,在多线程环境下transfer可能会引发死循环问题,有兴趣的可以了解一下:不正确地使用HashMap引发死循环及元素丢失。
void resize(int newCapacity) {
//保存扩容前的桶
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果目前的容量已经达到了MAXIMUM_CAPACITY,不会扩容,把threshold设置为Integer.MAX_VALUE
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//计算是否需要对键重新进行哈希码的计算
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
/**
* 将原有所有的桶迁移至新的桶数组中,在迁移时,桶在桶数组中的绝对位置可能会发生变化
*/
transfer(newTable, rehash);
table = newTable;
//像构造方法中一样来重新计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//桶的容量增加了,重新计算索引
int i = indexFor(e.hash, newCapacity);
//把e的next指向整个newTable[i]保存的数据
e.next = newTable[i];
//把e放到桶中。
newTable[i] = e;
e = next;
}
}
}
取出元素
get(Object key)
之前我们在分析ArrayList源码的时候,因为ArrayList基于数组实现的所以根据索引查找非常快。而HashMap根据键值对键的哈希值计算得到一个索引,在不考虑哈希冲突的情况下,也能够以O(1)的时间复杂度找到键值对,具有很高的性能。
public V get(Object key) {
//若键为null
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
//规定null的hash为0,在table[0]这个桶里面找键为null的键值对
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
//遍历寻找键为null的键值对
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
//根据键值得到键值对所在桶的索引
int hash = (key == null) ? 0 : hash(key);
//计算出索引,遍历桶中元素,在不发生哈希冲突的情况下,第一个元素就能找到了。
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//条件:比较键的hash值是否相等且键是否==或equals
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
删除元素
remove(Object key)
remove方法根据传入的键从HashMap移除键值对,并返回键值对的值。
public V remove(Object key) {
//调用removeEntryForKey方法
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {
Entry<K,V> next = e.next;
Object k;
//如果找到了,就将键值对从链表删除,这里面一大串就是单链表的删除元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
判断
isEmpty()
public boolean isEmpty() {
//HashMap的size为0,则为空
return size == 0;
}
containsKey(Object key)
public boolean containsKey(Object key) {
//直接调用getEntry方法,判断返回的键值对是否为null
return getEntry(key) != null;
}
containsValue(Object value)
public boolean containsValue(Object value) {
//判断value是否为null,如果是调用containsNullValue方法
if (value == null)
return containsNullValue();
//遍历寻找
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
private boolean containsNullValue() {
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (e.value == null)
return true;
return false;
}
总结
HashMap基于数组加单向链表实现、以Key-Value键值对存储数据,在不考虑哈希冲突的情况下能够以O(1)的复杂度进行存储、查询、删除元素,它通过巧妙的设计结合了ArrayList和LinkedList的优点。HashMap是线程不安全的,所以不建议在多线程环境下使用。JDK8中对HashMap的实现进行了改进,加入了红黑树的设计,将在下一篇文章中介绍。
JDK源码分析(三)——HashMap 上(基于JDK7)的更多相关文章
- JDK源码分析(三)——HashMap 下(基于JDK8)
目录 概述 内部字段及构造方法 哈希值与索引计算 存储元素 扩容 删除元素 查找元素 总结 概述 在上文我们基于JDK7分析了HashMap的实现源码,介绍了HashMap的加载因子loadFac ...
- JDK源码分析之hashmap就这么简单理解
一.HashMap概述 HashMap是基于哈希表的Map接口实现,此实现提供所有可选的映射操作,并允许使用null值和null键.HashMap与HashTable的作用大致相同,但是它不是线程安全 ...
- 【JDK】JDK源码分析-HashMap(1)
概述 HashMap 是 Java 开发中最常用的容器类之一,也是面试的常客.它其实就是前文「数据结构与算法笔记(二)」中「散列表」的实现,处理散列冲突用的是“链表法”,并且在 JDK 1.8 做了优 ...
- JDK 源码分析(4)—— HashMap/LinkedHashMap/Hashtable
JDK 源码分析(4)-- HashMap/LinkedHashMap/Hashtable HashMap HashMap采用的是哈希算法+链表冲突解决,table的大小永远为2次幂,因为在初始化的时 ...
- 【JDK】JDK源码分析-HashMap(2)
前文「JDK源码分析-HashMap(1)」分析了 HashMap 的内部结构和主要方法的实现原理.但是,面试中通常还会问到很多其他的问题,本文简要分析下常见的一些问题. 这里再贴一下 HashMap ...
- JDK源码分析(三)—— LinkedList
参考文档 JDK源码分析(4)之 LinkedList 相关
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(二)
本文继<Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)>,接着讲述MapReduce作业在MRAppMaster上处理总流程,继上篇讲到作业初始化之后的作 ...
- 使用react全家桶制作博客后台管理系统 网站PWA升级 移动端常见问题处理 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi [Abp 源码分析]四、模块配置 [Abp 源码分析]三、依赖注入
使用react全家桶制作博客后台管理系统 前面的话 笔者在做一个完整的博客上线项目,包括前台.后台.后端接口和服务器配置.本文将详细介绍使用react全家桶制作的博客后台管理系统 概述 该项目是基 ...
随机推荐
- 【整理】HTML5游戏开发学习笔记(1)- 骰子游戏
<HTML5游戏开发>,该书出版于2011年,似乎有些老,可对于我这样没有开发过游戏的人来说,却比较有吸引力,选择自己感兴趣的方向来学习html5,css3,相信会事半功倍.不过值得注意的 ...
- 20155233 2016-2017-2 《Java程序设计》第7周学习总结
20155233 2016-2017-2 <Java程序设计>第7周学习总结 学习目标 了解Lambda语法 了解方法引用 了解Fucntional与Stream API 掌握Date与C ...
- 【转】.NET+AE开发中常见几种非托管对象的释放
尝试读取或写入受保护的内存.这通常指示其他内存已损坏. 今天在开发时遇到一个问题:" 未处理 System.AccessViolationException Message="尝试 ...
- UITableView--文档版
CHENYILONG Blog UITableView Fullscreen UITableView技术博客http://www.cnblogs.com/ChenYilong/ 新浪微博http: ...
- Spring4笔记5--基于注解的DI(依赖注入)
基于注解的DI(依赖注入): 对于 DI 使用注解,将不再需要在 Spring 配置文件中声明 Bean 实例.只需要在 Spring 配置文件中配置组件扫描器,用于在指定的基本包中扫描注解. < ...
- 使用pandas把mysql的数据导入MongoDB。
使用pandas把mysql的数据导入MongoDB. 首先说下我的需求,我需要把mysql的70万条数据导入到mongodb并去重, 同时在第二列加入一个url字段,字段的值和第三列的值一样,代码如 ...
- oracle11g字符集问题之一
select * from T_WORK_EXPERIENCE t where ROLE=N'被雇佣者' 因为ROLE为NVARCHAR2(30),所以要加N.pl/sql developer 中可以 ...
- python 之datetime库学习
# -*- coding:utf-8 -*- import refrom datetime import datetime, timezone, timedelta def rec_time(): ...
- android解决AVD中文路径无法启动问题
在as中新建一个AVD,然而启动时却报错,总之是不能找到中文路径 然后这个虚拟设备被默认安装在了C盘我的用户李敏啊,而我用户名是中文名导致无法识别 解决办法,使用链接文件格式修改虚拟设备配置路径, 比 ...
- Linux学习笔记:cp和scp复制文件
拷贝文件和文件夹,在Linux上通过cp命令来实现. cp:用户当前机器的文件复制 scp:通过ssh本机和其他机器的文件复制 secure copy cp a.txt b.txt scp a.txt ...