hadoop之shuffle详解
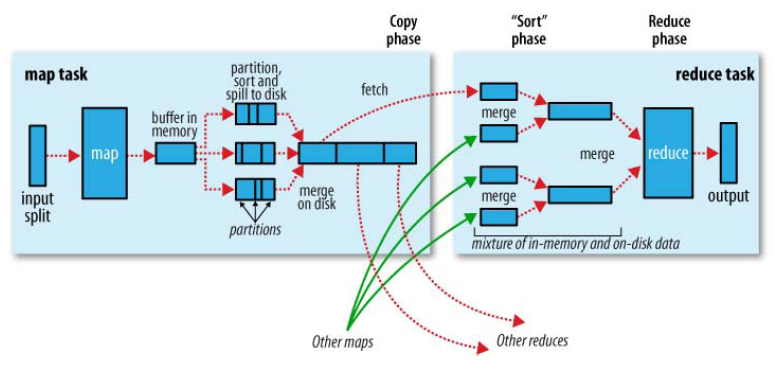
Shuffle描述着数据从map task输出到reduce task输入的这段过程。
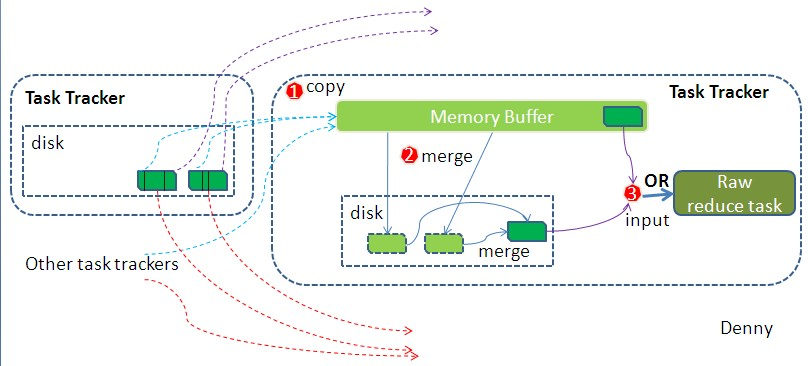
如map 端的细节图,Shuffle在reduce端的过程也能用图上标明的三点来概括。当前reduce copy数据的前提是它要从JobTracker获得有哪些map task已执行结束,这段过程不表,有兴趣的朋友可以关注下。Reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地在做。下面分段地描述reduce 端的Shuffle细节:
1. Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2. Merge(合并)阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3. Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
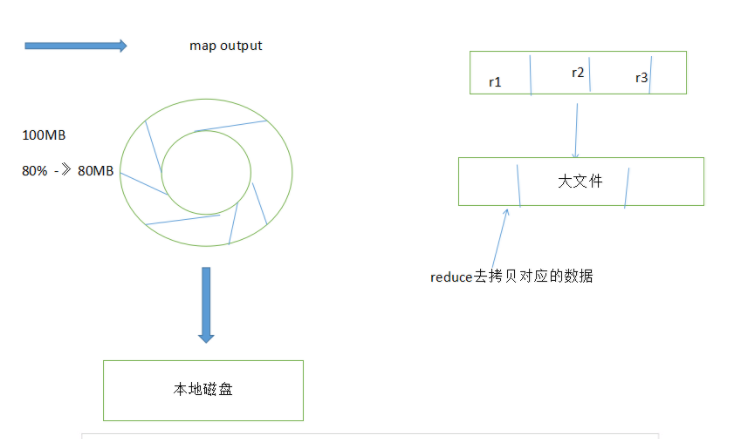
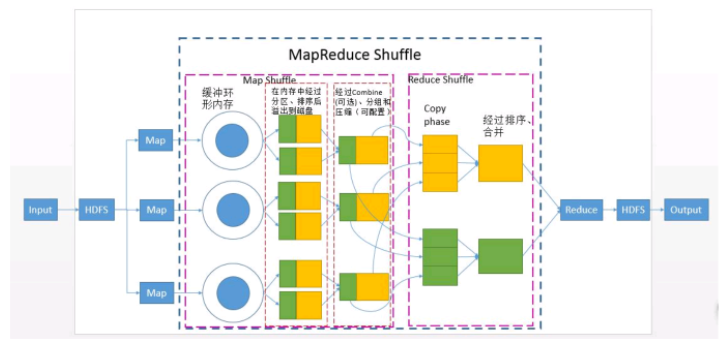
共可分为6个详细的阶段:
1).Collect阶段:将MapTask的结果输出到默认大小为100M的MapOutputBuffer内部环形内存缓冲区,保存
的是key/value,Partition分区
2).Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘
之前需要对数据进行一次排序的操作,先是对partition分区号进行排序,再对key排序,如果配置了
combiner,还会将有相同分区号和key的数据进行排序,如果有压缩设置,则还会对数据进行压缩操作。
3).Combiner阶段:等MapTask任务的数据处理完成之后,会对所有map产生的数据结果进行一次合并操作,
以确保一个MapTask最终只产生一个中间数据文件。
4).Copy阶段:当整个MapReduce作业的MapTask所完成的任务数据占到MapTask总数的5%时,JobTracker就会
调用ReduceTask启动,此时ReduceTask就会默认的启动5个线程到已经完成MapTask的节点上复制一份属于自
己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写
到磁盘之上。
5).Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存中和本地中的数据文件进行
合并操作。
6).Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,
ReduceTask只需做一次归并排序就可以保证Copy的数据的整体有效性。
文章来源:http://langyu.iteye.com/blog/992916
http://blog.csdn.net/haoyuexihuai/article/details/53037374
hadoop之shuffle详解的更多相关文章
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
- 【转载】Hadoop历史服务器详解
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:过往记忆(http://www.iteblog.com/) 原文地址: ...
- hadoop hdfs uri详解
body{ font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI& ...
- hadoop基础-SequenceFile详解
hadoop基础-SequenceFile详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.SequenceFile简介 1>.什么是SequenceFile 序列文件 ...
- Hadoop RPC机制详解
网络通信模块是分布式系统中最底层的模块,他直接支撑了上层分布式环境下复杂的进程间通信逻辑,是所有分布式系统的基础.远程过程调用(RPC)是一种常用的分布式网络通信协议,他允许运行于一台计算机的程序调用 ...
- hadoop之yarn详解(框架进阶篇)
前面在hadoop之yarn详解(基础架构篇)这篇文章提到了yarn的重要组件有ResourceManager,NodeManager,ApplicationMaster等,以及yarn调度作业的运行 ...
- Hadoop之WordCount详解
花了好长时间查找资料理解.学习.总结 这应该是一篇比较全面的MapReduce之WordCount文章了 耐心看下去 1,创建本地文件 在hadoop-2.6.0文件夹下创建一个文件夹data,在其中 ...
- Spark中的Spark Shuffle详解
Shuffle简介 Shuffle描述着数据从map task输出到reduce task输入的这段过程.shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过s ...
- hadoop之mapreduce详解(基础篇)
本篇文章主要从mapreduce运行作业的过程,shuffle,以及mapreduce作业失败的容错几个方面进行详解. 一.mapreduce作业运行过程 1.1.mapreduce介绍 MapRed ...
随机推荐
- Thymeleaf 常用th标签基础整理
(一)Thymeleaf 是个什么? 简单说, Thymeleaf 是一个跟 Velocity.FreeMarker 类似的模板引擎,它可以完全替代 JSP .相较与其他的模板引擎,它有如下 ...
- 『AngularJS』Service
理解Angular 服务 什么是Angular Service Angular 服务是为web应用执行特定任务的单例对象或方法. 注:如果组件是为了内容呈现的功能复用,那么服务就是为组件进行功能复用. ...
- C#调用C++编写的dll
界面还是C#写的方便点,主要是有一个可视化的编辑器,不想画太多的时间在界面上.但是自己又对C++了解的多一些,所以在需要一个良好的界面的情况下,使用C++来写代码逻辑,将其编译成一个dll,然后用C# ...
- QC的使用学习(三)
一.需求转换测试 1.自动转换方法: (1)将最底层的子需求转换成设计步骤:即将最底层的子要求转换成测试用例的步骤. (2)将最底层的子要求转换成测试:即将最底层的要求转换成单个测试用例(建议使用) ...
- windowsserver2008 重新启动计算机命令
在windowsserver2008中,若要重新启动计算机,可以输入以下命令即可立即重启计算机shutdown -r -t 0命令意义:shutdown在英文中意为关掉,在计算机中即为关机参数意义:- ...
- Week2 Teamework from Z.XML 软件分析与用户需求调查(四)Bing桌面及助手的现状与发展
一.Bing搜索的相关背景 第一,必应搜索前几年的发展重点在于欧美市场,并且取得了一定的成效:根据 Hitwise 的统计数据,Bing 在 2011年3 月份市场占有率突破了 30% 大关,达到 3 ...
- ArcGis下的叠加分析
1矢量与矢量叠加的话就用ToolBox里有Overlay: 2如果是矢量和栅格叠加的话用Spatial analysis模块中的 zonal statistics: 3还有就是栅格与栅格的叠加S ...
- Mac系统中常用快捷键
刚刚接触IOS系统,收集了一些快捷键和系统指令,以便能更好的学习IOS开发. 一.文件操作 复制:Command + C 粘贴:Command + V 回退:Command + ...
- 附录A培训实习生-面向对象基础方法重载(3)
就上一篇代码而言,你如果写Cat cat = new Cat();会直接报错错误 : 1 “Cat”方法没有采用“0”个参数的重载 E:\大话设计模式学习\BigDesignPattern ...
- C#判断字符串是否为数字字符串
在进行C#编程时候,有的时候我们需要判断一个字符串是否是数字字符串,我们可以通过以下两种方法来实现.[方法一]:使用 try{} catch{} 语句. 我们可以在try语句块中试图将str ...