Mysql基础2-数据定义语言DDL
主要:
- 数据库操作语句
- 数据表操作语句
- 视图定义语句
- 数据库表设计原则

DDL: Data Definition Language 数据定义语言
数据库操作语句
创建库
创建数据库: create database dbname [charset 字符编码] [collate 排序规则]; 如:
create database db charset utf8 collate utf8_general_ci;
查询库
1) 查看所有可用的字符编码: show charset;
2) 查看所有可用的排序规则: show collation
3)显示所有数据库: show databases;
4) 显示一个数据库的创建语句: show create database 数据库名; 如 show create database test;
删除库
删除数据库: drop database [if exists] 数据库名
drop database if exists db;
修改库
修改数据库(只能修改数据库的选项): alter database 数据库名 charset 新的编码 collate 新的排序规则
数据库修改只能修改: 修改编码,修改排序规则
选择库
选择数据库: use dbname;
表操作语句
创建表
基本形式:
-- 形式1:
create table [if not exists] 表名 (字段列表[, 索引或约束列表])[表选项] -- 形式2:
create table [if not exists] 表名 (字段1, 字段2, ..... [, 索引1, 索引2,...., 约束1, 约束2, ......])
字段设定形式:
字段名 类型 [字段属性1 字段属性2 ...]
字段属性
auto_increment: 仅用于整数类型。设定的字段的值自动获得增长值
not null: 用于设定该字段不能为空null, 没有设置,则默认可以为空
primary key: 设定字段为主键。
unique key: 设置字段 唯一,既不重复
default 默认值: 设置字段的默认值。 在insert时,没赋值则使用该默认值。
comment 说明字段
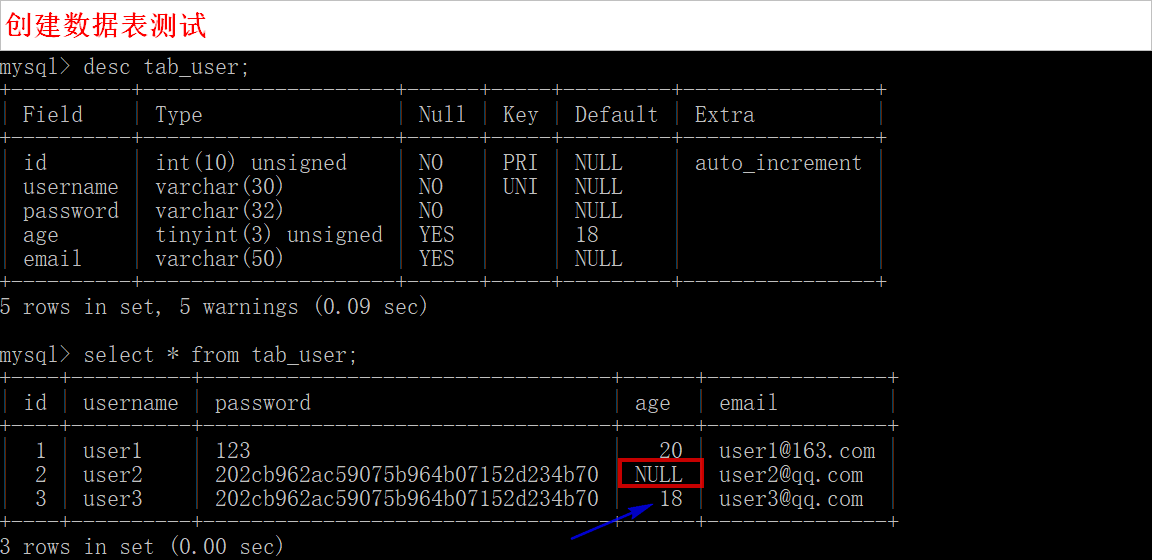
create table tab_user(
id int unsigned auto_increment primary key comment '主键',
username varchar(30) not null unique key comment '用户名',
password varchar(32) not null comment '密码',
age tinyint unsigned default 18 comment '年龄',
email varchar(50) comment '电子邮箱'
);
-- 查看表结构
desc tab_user; insert into tab_user (id, username, password, age, email) values(1,'user1','',20,'user1@163.com'),(null,'user2',md5(''),null,'user2@qq.com'); insert into tab_user (username,password,email) values('user3',md5(''),'user3@qq.com'); select * from tab_user;
【点击查看】创建数据表Demo
索引
概念:
是系统内部自动维护的隐藏的“数据表”。其中的数据是自动排好序的。
一个表可以设定或添加多个索引,对应则会有多个排序。
在数据库内部,数据库管理系统会创建并维护一个与当前表关联的“索引表”。该表数据按一定的方式进行了排序。
作用:
加快查询速度。 对没有索引的数据表查询数据,需要进行全表扫描。
过多索引会消耗资源,加速了数据读取,同时加重了数据库的增删改执行的负担
故: 索引一盘创建在 搜索, 排序, 分组等涉及经常查询的数据列上。
创建索引
形式: 索引类型(要建立索引的字段名)
创建索引: 有3种方式创建
方式1: 使用关键字 key 或 index 随表一起创建
方式2: 表已经被创建了, 使用create index 命令创建.
如 create index ue on tab_user(username, email); #创建名称为ue的索引为tab_user表的两个列
方式3: 表已经被创建了, 使用alter table 命令创建
查看索引
查看索引: 生成索引清单
show index from 表名; 如 show index from tab_user;
删除索引
删除指定的索引: drop index 索引名称 on 表名; 如 drop index ue on tab_user;
索引类别:
1)普通索引: index
设定形式: key [索引名] (字段名1[, 字段名2,....])
key与index是同义词
作用: 加快查询速度。 但会占用磁盘空间,减慢在索引数据列上的插入,修改和删除操作。
2) 唯一索引
作用: 设定某字段唯一避免数据重复, 且建立索引,加快查询速度
设定形式: unique [key] [索引名] (字段名1[, 字段名2, .....])
使用情形: 当确定某个数据列将只包含不重复的值时。 如果数据表中已经存在该字段,则会拒绝插入。 如 : 注册邮箱
3) 主键索引
作用: 设定某字段为主键, 且建立索引,具有唯一性。
主键与unique区别:
唯一性可以为空null, 而主键不能为空;
每个数据表有且只能有1个主键索引, 但可以有多个唯一索引
主键索引是唯一索引的特例
设定形式: primary key [索引名] (字段名1[, 字段名2, .....])
联合主键: 多个字段确定主键
4) 全文索引
设定某字段可以进行全文查找
设定形式: fulltext [key] [索引名] (字段名1[, 字段名2, .....])
5) 外键索引
形式: foreign key (字段名) references 其他表 (对应其他表中的字段名);
外键: 指设定的某个表tabel的某个字段column1, 它的数据值必须是在另一个表table2中的某个字段f2中存在。
如果给一个设定了外键的字段插入一个值,而该值并没有在该外键所指定的外部表的对应字段中出现,则该值就会插入失败
-- 索引创建语法
create table tab_index(
id int auto_increment,
user_name varchar(20),
email varchar(50),
age int,
key (email), # 普通索引
primary key(id), # 主键索引
unique key(user_name) # 唯一索引
); show index from tab_index; -- 常规索引
create table carts (
cid int(10) not null auto_increment,
uid int(10) not null,
bid int(10) not null,
num int(10) not null,
primary key (cid),
key ind(uid,bid) -- 如果未给出索引名ind ,系统会根据第一个索引列的名称自动选一个
) -- 建议使用“表名_列表”为索引命名
engine=innodb,
charset=utf8,
auto_increment=1,
comment '常规索引的创建'; show index from carts ;
【点击查看】创建索引Demo
-- 外键索引
create table departs(
id int auto_increment primary key,
name varchar(20) unique key comment '部门名称',
pid int comment '上级部门',
created_at date comment '创建时间'
)engine=innodb,
charset=utf8,
auto_increment=1,
comment '部门表'
; create table depart_user(
id int auto_increment primary key,
name varchar(10),
age tinyint,
depart_id int comment '部门id', -- 插入该列数据时,必须是departs表中id中已经存在的值才能成功插入
foreign key (depart_id ) references departs(id)
)engine=innodb,
charset=utf8,
auto_increment=1,
comment '用户表'
; -- 测试SQL
insert into departs (id, name, pid, created_at) values (null, 'market', 0, now()); -- depart_user 中插入的depart_id值在departs存在时,可以插入
insert into depart_user (id, name, age, depart_id) values(null, 'Tom',20,1); -- depart_user 中插入的depart_id值在departs不存在时,不能插入
insert into depart_user (id, name, age, depart_id) values(null, 'Tom',20,10);
【点击查看】外键索引Demo

约束
约束是要求数据需要满足指定条件的一种规定
1) 主键约束
形式: primary key(字段名)
作用: 设定的字段的值用于唯一确定一行数据。
2) 唯一约束
形式: unique key(字段名)
作用: 使设定字段的值具有 “唯一性”
3)外键约束
形式: foreign key(字段名) references 其他表(对应其他表中的字段名)
作用: 该设定字段的值,必须在其设定的对应表中的对应字段中已经有该值。
4) 非空约束
形式: not null
作用: 设定的字段不能为空。 该约束只能写在字段属性上
5) 默认约束
形式: default XX值
作用: 当插入数据时,没有给该设定的字段赋值,则该字段使用default 的默认值。 只能写在字段属性上
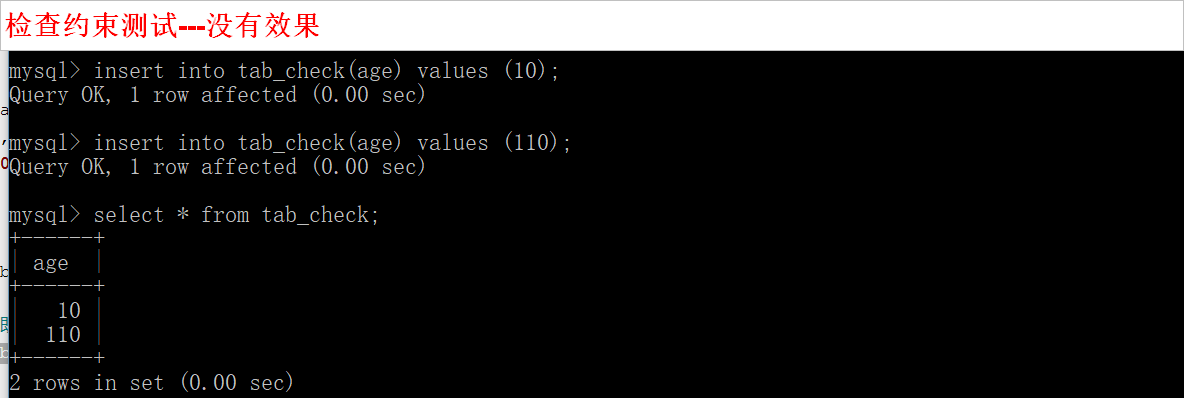
6) 检查约束
形式: check(某种判断语句) 如: create table tab (age tinyint, check(age > 0 and age < 100));
作用: 设定的字段必须满足check条件
mysql支持性不好, 有的版本插入不满足要求的数据时,会报错。如版本5.7
本次测试在5.5.53中,超出数据可以插入,并没有作用。
-- 检查约束测试
create table tab_check(
age tinyint,
check (age>=0 and age<100) -- 检查约束
); -- 测试数据
insert into tab_check(age) values (10); -- 插入非法数据 既不在0~100之间
insert into tab_check(age) values (110); select * from tab_check;
【点击查看】检查约束
表选项列表
各个表选项之间使用逗号或空格隔开
-- 表选项
create table 表名(
....
....
)
charset = 字符编码,
engine = 存储引擎(也叫表类型),
auto_increment = 表自增长字段的初始值,默认是1,
comment = '表说明文字....'
;
1) charset=字符编码; 设定的字符编码是为了跟数据库设定的不一样。如果相同则可以不用设定
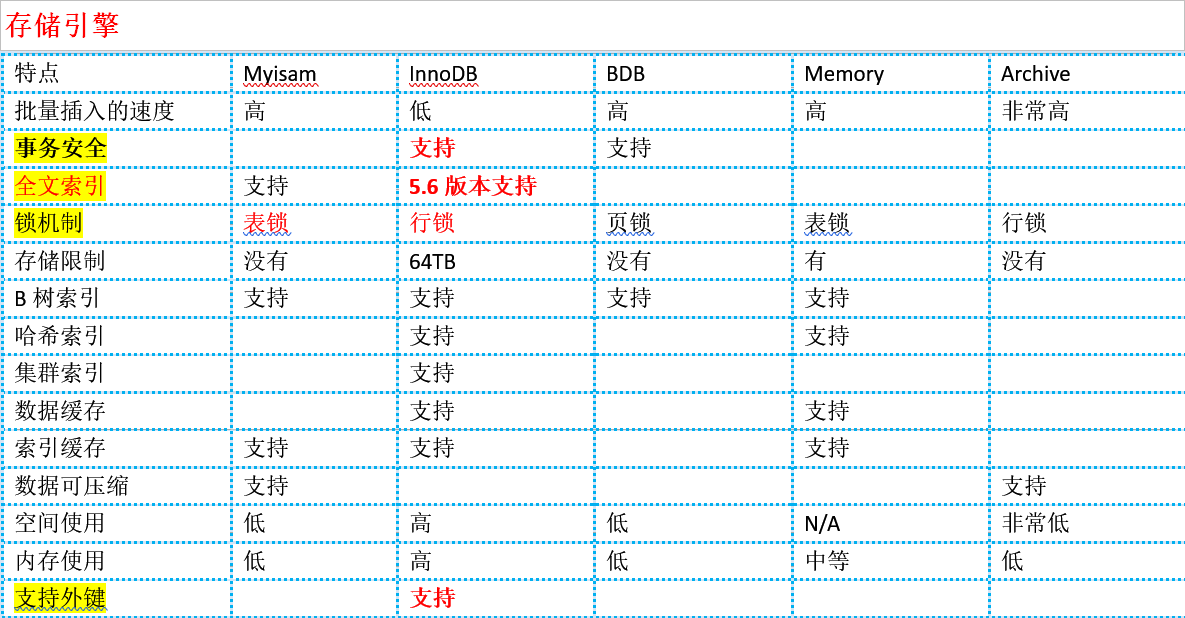
2) engine=存储引擎(也叫表类型)。是指一个表中的数据以何种方式存放在文件或内存中
常见存储引擎: InnoDB, MyIsam,BDB,archive,Memory
存储引擎: 是将数据存储到硬盘的机制。不同的存储机制主要从2大层面考虑
1-快速度, 2-多功能
3) auto_increment=表自增长字段的初始值,默认是1
4) comment='该表的一些说明文字'
不同的存储引擎(表类型)提供不同的性能特性和可用功能: 实际使用根据数据的具体使用情形(需求)来选择合适的存储引擎
-- 表选项
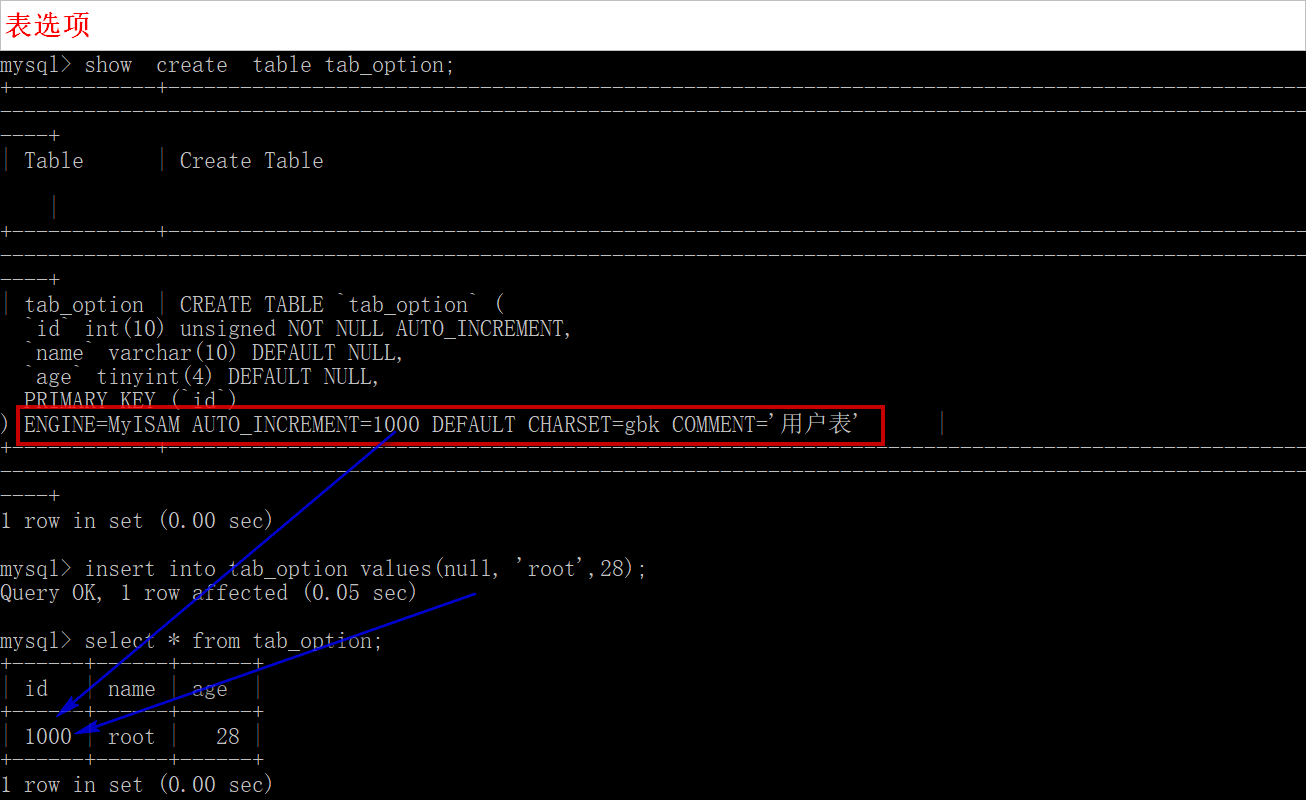
create table tab_option(
id int unsigned auto_increment primary key,
name varchar(10),
age tinyint
)
charset = gbk, #当前数据库的字符编码是utf8
engine = MyIsam,
auto_increment = 1000,
comment = '用户表'; -- 查看表创建语句
show create table tab_option;
【点击查看】表选项Demo
修改表
对于字段: 添加,删除,修改
对于索引: 添加,删除
1)表重命名:
alter table 表名 rename to 新表名
2)添加字段:
alter table 表名 add [column] 新字段名 字段类型 [字段属性列表]
3)修改字段并改名:
alter table 表名 change [column] 旧字段名 新字段名 新字段类型 [新字段属性列表]
4)修改字段仅改属性:
alter table 表名 modify [column] 字段名 新字段类型 [新字段属性列表]
5) 删除字段:
alter table 表名 drop [colomn] 字段名
6)添加字段默认值
alter table 表名 alter [column] 字段名 set default 默认值
7)删除字段默认值:
alter table 表名 alter [column] 字段名 drop default 默认值
8)修改表名
alter table 表名 rename [to] 新表名
9) 修改表选项
alter table 表名 选项1=选项值1, 选项2=选项值2,....
删除表
drop table [if exists] 表名
显示表信息
1) 显示所有表: show tables;
2) 显示表结构:
desc 表名;
description 表名;
3) 显示表创建语句
show create table 表名
复制表
1) 复制表结构: 从已存在的表复制表结构
create table [if not exists] 新表名 like 旧表名;
2) 表的完整复制包含数据
方式1: create table 表1 as select * from B.表2 #将B库中的表2 复制到 当前库命名为表1, 包括数据
方式2:
create table [if not exists] 新表名 like 旧表名;
insert into 新表名 select * from 旧表名
索引操作
1)创建索引
create [unique | fulltext] index 索引名 on 表名 (字段1,字段2,....)
实际在系统内部会映射为一条"alter table"的添加索引语句
2) 查看表索引
show index from 表名
3)删除索引
drop index 索引名 on 表名 如: drop index ind on tab_option; 【实际会映射一条alter table 的删除索引语句】
alter table 表名 drop index 索引名
alter table 表名 drop key 索引名
4) 删除主键
alter table 表名 drop primary key
5) 删除外键
alter table 表名 drop foreign key 键名
6)添加普通索引
alter table 表名 add key [索引名] (字段名1[, 字段名2,....])
7) 添加唯一索引
alter table 表名 add unique key [索引名] (字段名1[,字段名2,...])
8) 添加主键索引
alter table 表名 add primary key [索引名] (字段名1[,字段名2,...])
9) 添加外键索引
alter table 表名 add foreign key (字段名1[,字段名2,....]) refrences 表名2 (字段名1[, 字段名2,....])
视图定义语句
视图: 就是1个虚拟表,内容由一条查询语句定义。 既是一条select语句的查询结果,预先放在数据库中。可以当做一张表来使用
使用视图: 当做一个表使用
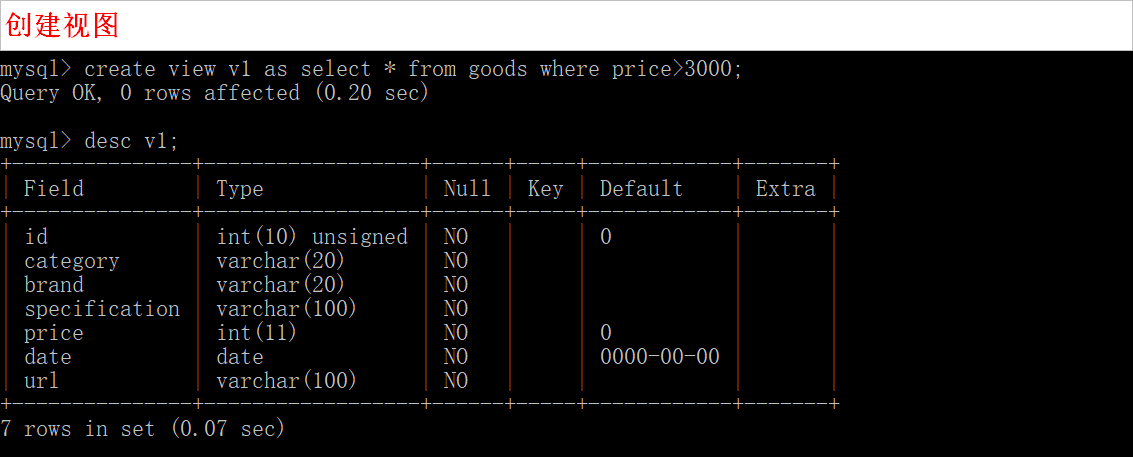
创建视图
create view 视图名 [(列1, 列2, ....)] as select 语句;
修改视图
alter view 视图名 [(列1,列2,列3,....)] as select 语句;
删除视图
drop view [if exists] 视图名
数据库表设计原则
数据库设计原则--也称为数据库设计三范式(3NF)
1) 第一范式(1NF): 原子性,数据不可再分
一个表中的数据(字段值)不可再分
2) 第二范式(2NF): 唯一性, 消除部分依赖
使每一行数据具有唯一性,并消除数据之间的“部分依赖”,使一个表中的非主键字段,完全依赖于主键字段
容易出现违背2NF情形: 存在联合主键的表
保证唯一性: 给表设计主键即可实现
什么是依赖? 表中字段B可以由另一字段A来决定 , 则表示 B依赖于字段A, 或A决定字段B
含义:如果根据字段A的某个值,一定可以找出一个确定的字段B的值,就是A决定B
如: 主键决定其他字段,其他字段依赖主键
什么是部分依赖? 如果某个字段只依赖 部分主键字段 。
发生前提: 主键字段有多个
什么是完全依赖? 既某个字段,是依赖于 主键的所有 字段。
如果一个表的主键只有一个字段, 则此时必是完全依赖
3) 第三范式(3NF): 独立性, 消除传递依赖
一个表中任何一个非主键,完全依赖于主键,而不能依赖于另外的非主键
出现违背情形:如果一个表中的一个非主键字段(B)依赖于另一个非主键字段(A)
因为A作为非主键字段,自然是依赖于主键字段的(范式2所决定的),则此时就会出现传递依赖
通常: 一个表存储一种数据 即可满足第3范式
16.00
Normal
0
7.8 磅
0
2
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:普通表格;
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0cm 5.4pt 0cm 5.4pt;
mso-para-margin:0cm;
mso-para-margin-bottom:.0001pt;
mso-pagination:widow-orphan;
font-size:10.5pt;
mso-bidi-font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;
mso-font-kerning:1.0pt;}
Mysql基础2-数据定义语言DDL的更多相关文章
- <MySQL>入门三 数据定义语言 DDL
-- DDL 数据定义语言 /* 库和表的管理 一.库的管理:创建.修改.删除 二.表的管理:创建.修改.删除 创建:create 修改:alter 删除:drop */ 1.库的管理 -- 库的管理 ...
- 【MySQL笔记】数据定义语言DDL
1.创建基本表 create table <表名> (<列名><数据类型>[列级完整性约束条件] ...
- SQLite基础-4.数据定义语言(DDL)
目录 一.创建数据库 1. 创建方式 2. 数据库命名规范 二. 创建表 1. 基本用法 2. 数据表命名规范 3. 字段命名规范 三. 删除表 一.创建数据库 1. 创建方式 在第二章中我们讲了如何 ...
- MySQL之数据定义语言(DDL)
写在前面 本文中 [ 内容 ] 代表啊可选项,即可写可不写. SQL语言的基本功能介绍 SQL是一种结构化查询语言,主要有如下几个功能: 数据定义语言(DDL):全称Data Definition L ...
- ODPS SQL <for 数据定义语言 DDL>
数据定义语言:(DDL) 建表语句: CREATE TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment ...
- 30441数据定义语言DDL
数据定义:指对数据库对象的定义.删除和修改操作. 数据库对象主要包括数据表.视图.索引等. 数据定义功能通过CREATE.ALTER.DROP语句来完成. 按照操作对象分类来介绍数据定义的SQL语法. ...
- mysql数据库-mysql数据定义语言DDL (Data Definition Language)归类(六)
0x01 创建数据库并指定字符集和排序规则 -- 三种实例写法 create database temptab2 character set utf8 collate utf8_general_ci; ...
- mysql数据定义语言DDL
库的管理 创建 create 语法:create database 库名 [character set 字符集] # 案例:创建库 create database if not exists book ...
- oracle 数据定义语言(DDL)语法
DDL语言包括数据库对象的创建(create).删除(drop)和修改(alter)的操作 1.创建表语法 create table table_name( column_name datatype ...
随机推荐
- Sql根据经纬度算出距离
SELECT ISNULL((2 * 6378.137 * ASIN(SQRT(POWER(SIN((117.223372- ISNULL(Latitude,0) )*PI()/360),2)+CO ...
- 如何将一个PDF文件里的图片批量导出
假设我有下面这个PDF文件,里面有很多图片,我想把这些图片批量导出,而不是在Adobe Acrobat Reader里一张张手动拷贝: 本文介绍一种快捷做法. 用PDF-XChange Editor打 ...
- OC typedef(起别名)
// #define Integer int // 给基本数据类型起别名 void test() { typedef int Integer; typedef Integer MyInteger; t ...
- Uva 12298 超级扑克2
题目链接:https://vjudge.net/problem/UVA-12298 题意: 1.超级扑克,每种花色有无数张牌,但是,这些牌都是合数:比如黑桃:4,6,8,9,10,,,, 2.现在拿走 ...
- linux服务基础之CentOS6编译安装mariadb
1. 下载mariadb https://downloads.mariadb.org/mariadb/+releases/ 2. 解压到指定目录 # tar xf mariadb--linux-x86 ...
- POJ 3233 Matrix Power Series 【经典矩阵快速幂+二分】
任意门:http://poj.org/problem?id=3233 Matrix Power Series Time Limit: 3000MS Memory Limit: 131072K To ...
- C# 利用HttpWebRequest进行HTTPS的post请求的示例
最近一个推送信息的目标接口从http格式换成https格式,原来的请求无法正常发送,所以修改了发送请求的方法.标红的代码是新加了,改了之后就可以正常访问(不检测证书的) public static s ...
- VS Code 中 HTML 文档注释 js 语句异常
今天用 VS Code 编辑 html 文档时,发现快捷键注释 js 代码显示成 “<!-- …… -->”,怀疑是不是因为安装了某个插件,随后排查出系 Jinja 所致,将其禁用之后就 ...
- intellig idea中jsp或html数据没有自动保存和更换字体
主题一:保存数据jsp intellig idea是自动保存数据的,看到没有保存 解决方案: 成功解决 主题二:更换字体: 或者快捷键Ctel+Alt+s 成功解决
- Android学习笔记_60_Android常用ADB命令
第一部分: 1. ubuntu下配置环境anroid变量: 在终端执行 sudo gedit /etc/profile 打开文本编辑器,在最后追加#set android environment 2. ...