TensorFlow学习笔记3-从MNIST开始
TensorFlow学习笔记3-从MNIST开始学习softmax
本笔记内容为“从MNIST学习softmax regression算法的实现”。
注意:由于我学习机器学习及之前的书写习惯,约定如下:
\(X\)表示训练集的设计矩阵,其大小为m行n列,m表示训练集的大小(size),n表示特征的个数;
\(W\)表示权重矩阵,其大小是n行k列,n为输入特征的个数,k为输出(特征)的个数;
\(\boldsymbol{y}\)表示训练集对应标签,其大小为m行,m表示训练集的大小(size);
\(\boldsymbol{y’}\)表示将测试向量\(x\)输入后得到的测试结果;
总之:
注意区分这里的:\(\boldsymbol{y'}=XW+\boldsymbol{b}\) 表示矩阵形式的预测结果(\(\boldsymbol{y’}\)和\(\boldsymbol{b}\)是向量);
之前机器学习中的是(如《机器学习实战》中SVM一章):$y’=\omega^T x+b $ 表示向量形式的预测结果(\(y'\)和\(b\)是标量);
算法部分:包括预测模型和优化目标
以手写输入MNIST为例:
预测模型
\]
其中softmax函数是归一化函数:
\]
其中\(i , j\)的范围为1~10。softmax函数将\(\boldsymbol{z}\)归一化之后变为\(\boldsymbol{y’}\)(预测值)。如下图。
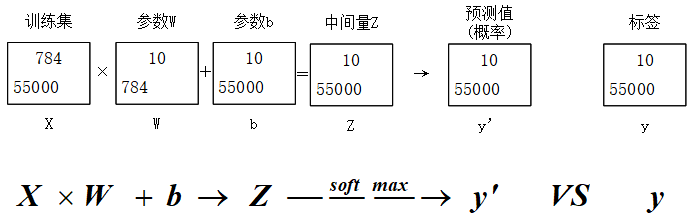
- 训练集:共55000条数据,每条数据中有784个特征(将28*28个像素点进行展开,忽略了像素间的结构关系),矩阵中m=55000,n=784;
- 参数\(W\)中的元素\(W_{i,j}\)的含义是:第i个像素点在数字j中占的权重,意思是如果很多数字j的实例中都有i,说明像素点i很大可能代表数字j,那么其权重会很大。
- 参数\(b\)中的元素\(b_{i,j}\)的含义是:第i个像素点在数字j的偏置量,意思是如果大部分数字都是0,则0的特征对应的bias值会很大。

优化目标:交叉熵的最小化
交叉熵:
\]
其中,
每个batch中的所有预测项的交叉熵的平均值为评价指标。
实现部分:
用随机梯度下降优化器对评价指标进行优化。
每次随机选取训练集中的100个子集作为batch(桶)进行训练,共训练1000次。
预测模型的评价
统计准确率。
附代码:
import tensorflow as tf
# 1 Collect data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True);
print(mnist.train.images.shape, mnist.train.labels.shape);
print(mnist.test.images.shape,mnist.test.labels.shape);
print(mnist.validation.images.shape,mnist.validation.labels.shape);
# 2 Create Model
X = tf.placeholder(tf.float32,[None,784]);
y = tf.placeholder(tf.float32,[None,10]);
W = tf.Variable(tf.random_uniform([784,10],-1,1));
b = tf.Variable(tf.zeros([10]));
z = tf.matmul(X,W)+b;
y_ = tf.nn.softmax(z);
# 3 loss function
loss = -tf.reduce_mean(tf.reduce_sum(y*tf.log(y_),axis=1));
optimizer = tf.train.GradientDescentOptimizer(0.5);
train = optimizer.minimize(loss);
# 4 initialzer
init = tf.initialize_all_variables();
sess = tf.InteractiveSession();
sess.run(init);
# 5 Train
for step in range(1000):
x_batch,y_batch = mnist.train.next_batch(100);
sess.run(train,feed_dict={X:x_batch,y:y_batch});
if step%10 ==0:
print(step/10,"%",sess.run(loss,feed_dict={X:x_batch,y:y_batch}));
# 6 Output
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1));
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32));
print(accuracy.eval({X:mnist.test.images,y:mnist.test.labels}));
sess.close();
更进一步
- 使用
InteractiveSession将这个session注册为默认的session,之后的运算都默认跑在这个session里,不同session之间的运算与数据相互独立。
比较
batch_xs, batch_ys = mnist.train.next_batch(100) # 使用minibatch,一个batch大小为100
train_step.run({x: batch_xs, y: batch_ys})
与
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
的异同。
本质没有区别:也就是说只要是字典dict形式的写法,就是输入;否则就是输出。
TensorFlow学习笔记3-从MNIST开始的更多相关文章
- tensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
刚开始学习tf时,我们从简单的地方开始.卷积神经网络(CNN)是由简单的神经网络(NN)发展而来的,因此,我们的第一个例子,就从神经网络开始. 神经网络没有卷积功能,只有简单的三层:输入层,隐藏层和输 ...
- Tensorflow学习笔记(对MNIST经典例程的)的代码注释与理解
1 #coding:utf-8 # 日期 2017年9月4日 环境 Python 3.5 TensorFlow 1.3 win10开发环境. import tensorflow as tf from ...
- tensorflow学习笔记五:mnist实例--卷积神经网络(CNN)
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(2)
tensorflow学习笔记——使用TensorFlow操作MNIST数据(1) 一:神经网络知识点整理 1.1,多层:使用多层权重,例如多层全连接方式 以下定义了三个隐藏层的全连接方式的神经网络样例 ...
- tensorflow学习笔记——使用TensorFlow操作MNIST数据(1)
续集请点击我:tensorflow学习笔记——使用TensorFlow操作MNIST数据(2) 本节开始学习使用tensorflow教程,当然从最简单的MNIST开始.这怎么说呢,就好比编程入门有He ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- ensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试
http://www.cnblogs.com/denny402/p/5852983.html ensorflow学习笔记四:mnist实例--用简单的神经网络来训练和测试 刚开始学习tf时,我们从 ...
随机推荐
- SpringMVC处理器拦截器 Interceptor
拦截器概念 Java 里的拦截器是动态拦截action调用的对象.它提供了一种机制可以使开发者可以定义在一个action执行的前后执行的代码,也可以在一个action执行前阻止其执行,同时也提供了一种 ...
- k8s结合helm部署
一.安装Helm helm教程以及安装可以参考这篇文章 二.Heml说明 常见的helm模板如下 myapp - chart 包目录名 ├── charts - 依赖的子包目录,里面可以包含多个依赖的 ...
- javascript(DOM)实例
JavaScript学习笔记 JS补充笔记 实例之跑马灯,函数创建.通过ID获取标签及内部的值,字符串的获取与拼接.定时器的使用 使用定时器实现在console中打印内容 Dom选择器使用与调试记录 ...
- oracle学习笔记(四) DML数据控制语言和TCL 事务控制语言
DML 数据管理语言 Data manage language insert, update, delete以及select语句,不过,有人也把select单独出来,作为DQL 数据查询语言 data ...
- ulimit 管理系统资源
具体的 options 含义以及简单示例可以参考以下表格. 选项 含义 例子 -H 设置硬资源限制,一旦设置不能增加. ulimit – Hs 64:限制硬资源,线程栈大小为 64K. -S 设置软资 ...
- linux下挂载U盘方法
1.使用 cat /proc/partitions 查看系统现在有哪些分区:[root@localhost ~]# cat /proc/partitions major minor #blocks ...
- Taro -- 定义全局变量
Taro定义全局变量 方法1:在taro中 getApp()只能取到一开始定义的值,并不能取到改变后的值 // app.js文件中 class App extends Component { cons ...
- python基础--2 字符串
整型 int python3里,不管数字多大都是int类型 python2里面有长整型long 将整型字符串转换为数字 # a='123' # print(type(a),a) # b=int(a) ...
- oracle常用操作方法
---oracle创建数据库,基于plsqldev工具 1.创建表空间,创建空内容的物理文件create tablespace db_test --表空间名 datafile 'D:\test.dbf ...
- [sqlmap源码阅读] 数据库识别
通过网页返回的数据库错误信息识别网站所有数据库类型,用到的正则表达式及支持识别的数据库类型,这些信息以xml文件的形式存在,使用 sax 解析xml.