postgresql主从同步配置
前言
不久前,公司的一台物理机器硬件坏了,导致运行在其上的虚拟机都挂了。很不凑巧的是,我负责的那台虚拟机的系统盘坏了(ps:感觉老天在玩我),导致里面的数据永远的离我而去(ps:当时我的内心是崩溃的)。为了避免再次发生这种事情,就想到了主从备份君。由于之前虚拟机使用的的是postgresql,因此本博是对postgresql主从备份的配置。写本博的主要目的有以下几点:
1.记录下来配置的方法,以便以后使用
2.希望能够帮助那些配置postgresql主从备份的人
3.希望大神可以提供更好的配置方案,指出本博理解不对的地方,以便本人改进
系统环境
- 操作系统:centos-release-7-2.1511.el7.centos.2.10.x86_64(ps:可以使用 rpm -q centos-release 查看)
- postgresql版本:postgresql96-server-9.6.3-1PGDG.rhel7.x86_64(ps:可以使用 rpm -aq | grep postgres 查看)
配置步骤(ps:postgresql的安装这里就不在阐述,还请各位大佬自行百度)
注: #{xxx} 为你需要填的参数
主库操作步骤
创建角色replica并且设置密码
操作步骤:
1.进入root用户
sudo -i
2.切换到postgres用户
su - postgres
3.登录postgresql
pslq
4.创建角色replic并且设置密码
create role replic login replication encrypted password '#{password}'
5.查看角色是否创建成功
\du
出现以下记录则创建成功:

6.退出数据库
\q
修改postgresql配置文件
1.打开配置文件 pg_hba.conf (ps:寻找配置文件 find / -name pg_hba.conf )
vim /var/lib/pgsql/9.6/data/pg_hba.conf
2.在文件末尾增加以下代码:(ps:参数3为刚刚创建的role,参数4为从库的IP地址和子网掩码)
host replication replic 172.17.10.0/24 md5host all replic 172.17.10.0/24 trust3.保存设置并且退出
4.打开配置文件 postgresql.conf
vim /var/lib/pgsql/9.6/data/postgresql.conf
5.修改以下几个配置项
listen_addresses = '*' #设置所有主机可以访问
wal_level = hot_standby #热备模式
max_wal_senders= 6 #可以设置最多几个流复制链接,差不多有几个从,就设置多少
wal_keep_segments = 10240 #设置流复制保留的最多的xlog数目
wal_send_timeout = 60s
max_connections = 512 #从库的 max_connections要大于主库
archive_mode = on #允许归档
archive_command = 'cp %p /url/path%f' #根据实际情况设置
6.退出并且保存
重启postgres服务
1.执行命令重启postgres
/usr/pgsql-9.6/bin/pg_ctl restart
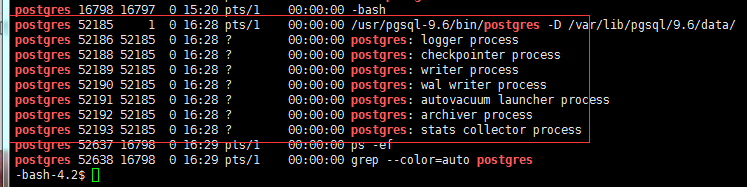
2.查看postgres是否重启成功
ps -ef | grep postgres
下面图片上的输出说明已经启动:
从库操作步骤
创建文件夹(ps:在这里我将该文件夹命名为data2,可以自行命名)
1.切换到root用户
sudo -i
2.切换到postgres用户
su - postgres
3.创建文件夹 data2
mkdir /var/lib/pgsql/9.6/data2
备份主库的数据到data2文件夹下
1.输入以下指令执行备份
/usr/pgsql-9.6/bin/pg_basebackup -F p --progress -D /var/lib/pgsql/9.6/data2 -h #{ip} -p 5432 -U #{role} --password
注:ip为主库的ip地址,role为上面主库创建的role
出现下图提示表示备份完毕:

2.按住 ctrl+c 退出
复制 recovery.conf 文件到 data2 文件夹下,并且修改文件夹的权限
1.找到recovery.conf.sample文件
find / -name recovery.conf.sample
2.复制文件到data2文件夹下
cp /usr/pgsql-9.6/share/recovery.conf.sample /var/lib/pgsql/9.6/data2/recovery.conf
3.修改data2文件夹的权限(ps:否则postgres启动不了,报错:Permissions should be u=rwx (0700))
chmod -R 0700 /var/lib/pgsql/9.6/data2
修改配置文件 recovery.conf
1.打开配置文件recovery.conf
vim /var/lib/pgsql/9.6/data2/recovery.conf
2.修改下面的配置项
standby_mode = on # 这个说明这台机器为从库
primary_conninfo = 'host=#{ip} port=5432 user=#{role} password=#{password}' # 这个说明这台机器对应主库的信息
recovery_target_timeline = 'latest' # 这个说明这个流复制同步到最新的数据
注:ip为主库的ip地址,role为上面主库创建的role,password你懂得
3.保存并且退出编辑
修改配置文件 postgresql.conf
1.打开配置文件postgresql.conf
vim /var/lib/pgsql/9.6/data2/postgresql.conf
2.修改以下配置项
max_connections = 1000 # 一般查多于写的应用从库的最大连接数要比较大
hot_standby = on # 说明这台机器不仅仅是用于数据归档,也用于数据查询
max_standby_streaming_delay = 30s # 数据流备份的最大延迟时间
wal_receiver_status_interval = 1s # 多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,这里只是设置最长的间隔时间
hot_standby_feedback = on # 如果有错误的数据复制,是否向主进行反馈
3.保存并突出
启动postgres
1.输入启动命令
/usr/pgsql-9.6/bin/pg_ctl -D /var/lib/pgsql/9.6/data2 start
注意:现在的数据地址变成了data2,并且如果之前已经启动,请将其关闭
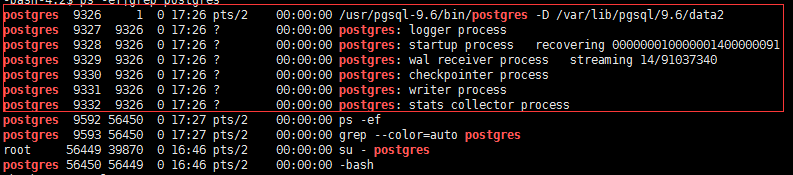
2.查看启动是否完成
ps -ef|grep postgres
出现下图的输出说明启动完成:
遇到的问题:
1.启动报错: It occurs when either the system limit for the maximum number of semaphore sets (SEMMNI)
问题分析: max_connections 是指的值超过了操作系统的最大值,因此报错,经过百度找到了解决方案
解决方案:https://my.oschina.net/Kenyon/blog/120355(这里有大神的解决方案)
验证主从配置是否成功(ps:以下操作针对主库)
1.在主库的数据库中执行以下语句
select client_addr,sync_state from pg_stat_replication;
若输出如下,说明成功:

postgresql主从同步配置的更多相关文章
- mysql主从同步配置(windows环境)
mysql主从同步配置(mysql5.5,windows环境) A主机(作为主服务器)环境:windows8.mysql5.5 ip:192.168.1.100(自己填) B主机(作为从服务器,由 ...
- Docker Mysql主从同步配置搭建
Docker Mysql主从同步配置搭建 建立目录 在虚拟机中建立目录,例如路径/home/mysql/master/data,目录结构如下: Linux中 新建文件夹命令:mkdir 文件夹名 返回 ...
- Docker Mysql数据库主从同步配置方法
一.背景 最近在做内部平台架构上的部署调整,顺便玩了一下数据库的主从同步,特此记录一下操作- 二.具体操作 1.先建立数据存放目录(-/test/mysql_test/) --mysql --mast ...
- Linux下MySQL数据库主从同步配置
说明: 操作系统:CentOS 5.x 64位 MySQL数据库版本:mysql-5.5.35 MySQL主服务器:192.168.21.128 MySQL从服务器:192.168.21.129 准备 ...
- DNS 主从同步配置
DNS 主从同步配置 主从同步:主每次修改配置文件需要修改一下序列号,主从同步主要 看序列号. 从DNS:从是可以单独修改,主从不会报错.但从修改后,主端同步给从后 从端修改数据会丢失 主从原理:从会 ...
- Mysql 5.6主从同步配置
主从同步,本质是利用数据库日志,将主库数据复制一份到从库,本质上是使用了数据复制技术. 本文概要 主库的基本配置 从库的基本配置 完全同步的步骤 注意事项 工作原理 1. 主库的基本配置 做两件事:启 ...
- centos:mysql主从同步配置(2018)
centos:mysql主从同步配置(2018) https://blog.csdn.net/liubo_2016/article/details/82379115 主服务器:10.1.1.144; ...
- MySql数据主从同步配置
由于需要配置MySQL的主从同步配置,现将配置过程记录下,已被以后不时之需 MySql数据主从同步 1.1. 同步介绍 Mysql的 主从同步 是一个异步的复制过程,从一个 Master复制到另一 ...
- centos 6.5 中设置mysql 5.1.73 主从同步配置过程
本文章给大家介绍centos 6.5设置mysql主从同步过程记录,希望文章对各位会带来帮助. 涉及到的centos系统均为虚拟机,VM下安装的版本. 在centos 6.5上设置了mysql主从功 ...
随机推荐
- vue中淡入淡出示例
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- FineTuning机制的分析
FineTuning机制的分析 为什么用FineTuning 使用别人训练好的网络模型进行训练,前提是必须和别人用同一个网络,因为参数是根据网络而来的.当然最后一层是可以修改的,因为我们的数据可能并没 ...
- Azylee.Utils 工具组
https://github.com/yuzhengyang/Fork Fork 是平时做 C# 软件的时候,整合各种轮子的一个工具项目,包括并不仅限于:各种常用数据处理方法,文件读写 加密 搜索,系 ...
- Jenkins持续集成_04_解决HTML测试报告样式丢失问题
前言 最近进行Jenkins自动化测试持续集成,配置HTML测试报告后,但是点击进去发现测试报告样式丢失,未加载CSS&JS样式,如下图: 由于Jenkins中配置了CSP(Content S ...
- SocketChannel 读取ByteBuf 的过程
SocketChannel 读取ByteBuf 的过程: 我们首先看NioEventLoop 的processSelectedKey 方法: private void processSelectedK ...
- 《剑指offer》面试题21 包含min函数的栈 Java版
(min函数的作用是返回栈内最小值) 首先这个栈要具有普通栈所具有的push()和pop()方法,那么内部一定包含一个Stack.至于还要能实现min函数,而且还是在O(1)时间复杂度内,我们不得不考 ...
- 13 个设计 REST API 的最佳实践
原文 RESTful API Design: 13 Best Practices to Make Your Users Happy 写在前面 之所以翻译这篇文章,是因为自从成为一名前端码农之后,调接口 ...
- Webpack4、iView、Vue开发环境的搭建
导读 项目使用了 yarn ,一个快速.可靠.安全的依赖管理工具.yarn 是一个类似于npm的包管理工具,它是由 facebook 推出并开源,它在速度,离线模式,版本控制的方面具有独到的优势.此项 ...
- Webpack和Gulp对比
Webpack和Gulp对比 作者 彬_仔 关注 2016.10.19 22:42* 字数 8012 阅读 2471评论 18喜欢 68 在现在的前端开发中,前后端分离.模块化开发.版本控制.文件合并 ...
- typescript总结
1,基础类型 { 布尔值,let isDone:Boolean=true; 数字,let decLiteral:number=true; 字符串,let name:string=" ...