实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB
豆瓣TOP网址:传送门
一、连接数据库
打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,db文件夹即用于存储数据
在bin路径下输入配置信息——>mongod --dbpath D:\MongoDB\data\db (此处为存储文件路径)
再打开新的命令行窗口,输入——>mongo
注意:启动服务的命令行窗口不要关闭
打开可视化管理工具Robomongo,点击Connections对话框,在右侧新建connect
保持默认设置,单击save,最后单击Connect即可连接到数据库
### 二、运行爬虫
# -*- coding:utf-8 -*-import pymongofrom lxml import etreeimport reimport requestsimport timeclient =pymongo.MongoClient('localhost',27017) #创建并连接数据库mydb = client['mydb']musictop = mydb['musictop']headers = {'User=Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'} #请求头def get_url_music(url): #获得详细url的函数html = requests.get(url, headers = headers)selector = etree.HTML(html.text)music_hrefs = selector.xpath('//a[@class="nbg"]/@href')for music_href in music_hrefs:get_music_info(music_href)def get_music_info(url): #获取详细信息的函数html = requests.get(url, headers=headers)selector = etree.HTML(html.text)name = selector.xpath('//*[@id="wrapper"]/h1/span/text()')[0] #xpathauthor = re.findall('表演者:.*?>(.*?)</a>',html.text,re.S)[0] #正则表达式styles = re.findall('<span class="pl">流派:</span> (.*?)<br/>',html.text,re.S)if len(styles)==0:style = '未知'else:style = styles[0].strip()time = re.findall('发行时间:</span> (.*?)<br/>',html.text,re.S)[0].strip()publishers = re.findall('出版者:.*?>(.*?)</a>',html.text,re.S)if len(publishers)==0:publisher = "未知"else:publisher = publishers[0].strip()score =selector.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')[0]print(name,author,style,time,publisher,score)info = {'name':name,'author':author,'style':style,'time':time,'publisher':publisher,'score':score,}musictop.insert_one(info)if __name__=='__main__': #主程序入口urls = ['https://music.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)]for url in urls:get_url_music(url)time.sleep(2)
成果展示:
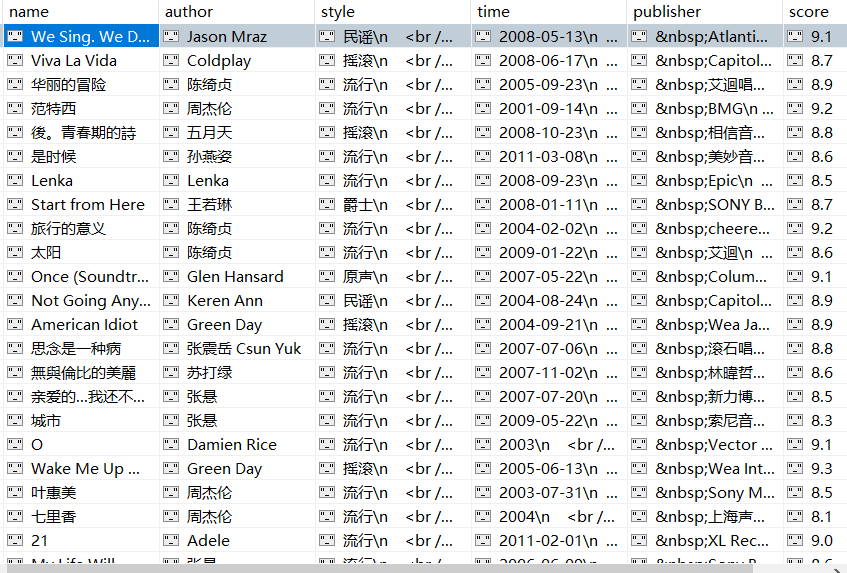
获取author字段信息时,采用正则是因为各详细页中标签位置略有不同,若通过定位标签获取信息,一些详细页信息匹配可能出错。
“表演者”字段在网页源代码中的相对位置是一样,可考虑正则表达式获取信息。
流派、发行时间、出版者信息若用Xpath方式爬取,会数据杂乱,多个标签嵌套,甚至存在乱码符号。
实例学习——爬取豆瓣音乐TOP250数据的更多相关文章
- 实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev 网址:https://book.douban.com/top250?start=0 from lxml import etree #解析提取数据 ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- 爬取豆瓣音乐TOP250的数据
参考网址:https://music.douban.com/top250 因为详细页的信息更丰富,本次爬虫在详细页中进行,因此先爬取进入详细页的网址链接,进而爬取数据. 需要爬取的信息有:歌曲名.表演 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
随机推荐
- 手动升级 Confluence - 开始升级之前
在本指南中,我们将会帮助你使用 zip / tar.gz 文件将你的 Confluence 安装实例在 Windows 或者 Linux 版本中升级到最新的版本. 升级到任何最新的版本都是免费的,如果 ...
- python 学习之路(1)
1变量的使用以及原理 先定义一个变量 变量的类型 变量的命名 01变量的命名 变量名 = 值 左边是变量名 右边是值 又叫做赋值 上面是ipython的交互模式的 那我们看看在pycharm里面如何输 ...
- 前端开发——让算法"动"起来
正文 当然在我们不清楚具体操作细节前我们可以先假设一下,我们能够用什么来实现.按照以前看过的排序动画我将其分为 1.Js操作Dom,再搭配简单的css 2.Canvas动画 之后在查资料的时候发现还有 ...
- JAVA_OPT理解及调优理论
以RocketMQ的namesrv和broker启动为例,理解CMS和G1垃圾收集器下的jdk参数 CMS垃圾收集器 以RocketMQ中runserver.cmd为例,这是启动NameSrv的命令行 ...
- 利用Zookeeper实现分布式锁
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- 191121CSS
一.CSS 1.css选择器 css选择器的使用方法 <!DOCTYPE html> <html lang="en"> <head> <m ...
- php面向对象 练习
实例一:求一个圆环的面积,大圆半径:10 小圆半径:5 造一个圆的类: class Yuan { public $r; function __construct($r) //半径初始化 { $t ...
- spring cloud microservice provider and consumer
MicroService Provider:https://files.cnblogs.com/files/xiandedanteng/empCloud190824.rarMicroService C ...
- 全面解读php-网络协议
一.OSI七层模型 1.物理层 作用:建立,维护,断开物理连接 2.数据链路层 作用:建立逻辑连接,进行硬件地址寻址,差错校验等功能. 3.网络层 作用:进行逻辑地址寻址,实现不同网络之间的路径选择. ...
- Eureka入门一(了解概念)
Eureka注册中心(8761端口) IDEA(开发工具) 1,创建项目勾选Eureka Server 2, 创建yml文件,拷贝配置,下面配置必须为false,意为,该项目不要作为客户端注册,因为本 ...