Java ——JDBC数据库编程
数据库分类
- 关系型数据库:以表来存放数据的,数据与数据之间的关系通过表之间的连接体现
- 面向对象的数据库:保存的是对象本身
- 其它
数据库:数据库管理系统中创建一个个的保存数据的单位
数据是保存在数据库的表中的
存储引擎
MyISAM
存储引擎:不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
支持3种不同的存储格式,分别是:静态表;动态表;压缩表
静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)ps:在取数据的时候,默认会把字段后面的空格去掉,如果不注意会把数据本身带的空格也会忽略。
动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能
压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
InnoDB
该存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
InnoDB存储引擎的特点:支持自动增长列,支持外键约束
MEMORY
Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围
Hash索引优点:
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
Hash索引缺点: 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
Memory类型的存储引擎主要用于哪些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果,。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
MERGE
Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
事务
做一件事情的最小单元,要么同时成功,要么同时失败。
InoDB才支持事务
数据类型
数字型
|
类型 |
大小 |
范围(有符号) |
范围(无符号) |
用途 |
|
TINYINT |
1 字节 |
(-128,127) |
(0,255) |
小整数值 |
|
SMALLINT |
2 字节 |
(-32 768,32 767) |
(0,65 535) |
大整数值 |
|
MEDIUMINT |
3 字节 |
(-8 388 608,8 388 607) |
(0,16 777 215) |
大整数值 |
|
INT或INTEGER |
4 字节 |
(-2 147 483 648,2 147 483 647) |
(0,4 294 967 295) |
大整数值 |
|
BIGINT |
8 字节 |
(-9 233 372 036 854 775 808,9 223 372 036 854 775 807) |
(0,18 446 744 073 709 551 615) |
极大整数值 |
|
FLOAT |
4 字节 |
(-3.402 823 466 E+38,1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) |
0,(1.175 494 351 E-38,3.402 823 466 E+38) |
单精度 |
|
DOUBLE |
8 字节 |
(1.797 693 134 862 315 7 E+308,2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
双精度 |
|
DECIMAL |
对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 |
依赖于M和D的值 |
依赖于M和D的值 |
小数值 |
字符类型
|
CHAR |
0-255字节 |
定长字符串 |
|
VARCHAR |
0-255字节 |
变长字符串 |
|
TINYBLOB |
0-255字节 |
不超过 255 个字符的二进制字符串 |
|
TINYTEXT |
0-255字节 |
短文本字符串 |
|
BLOB |
0-65 535字节 |
二进制形式的长文本数据 |
|
TEXT |
0-65 535字节 |
长文本数据 |
|
MEDIUMBLOB |
0-16 777 215字节 |
二进制形式的中等长度文本数据 |
|
MEDIUMTEXT |
0-16 777 215字节 |
中等长度文本数据 |
|
LOGNGBLOB |
0-4 294 967 295字节 |
二进制形式的极大文本数据 |
|
LONGTEXT |
0-4 294 967 295字节 |
极大文本数据 |
时间类型
|
类型 |
大小 |
范围 |
格式 |
用途 |
|
DATE |
3 |
1000-01-01/9999-12-31 |
YYYY-MM-DD |
日期值 |
|
TIME |
3 |
'-838:59:59'/'838:59:59' |
HH:MM:SS |
时间值或持续时间 |
|
YEAR |
1 |
1901/2155 |
YYYY |
年份值 |
|
DATETIME |
8 |
1000-01-01 00:00:00/9999-12-31 23:59:59 |
YYYY-MM-DD HH:MM:SS |
混合日期和时间值 |
|
TIMESTAMP |
8 |
1970-01-01 00:00:00/2037 年某时 |
YYYYMMDD HHMMSS |
混合日期和时间值,时间戳 |
JDBC主要完成的几个任务
1.与数据库建立连接
2.发送SQL语句
3.处理数据库返回的结果
基础SQL操作
查看数据库管理系统中有哪些数据库:show databases;
使用某一个数据库:use mysql;
查看数据库有多少表:show tables;
查看表中的数据:select * from user;
查看表的结构:desc user;
创建表:
create table <表名>(
字段名 字段类型 ,
字段名 字段类型 ,
……
字段名 字段类型
);
创建数据库:
Create databases 数据库名;
主键——记录的唯一标识
只有数据类型(int)的主键列才能自动增加
示例:
CREATE TABLE `tb_dept` (
`deptno` int(2) NOT NULL AUTO_INCREMENT,
`dname` varchar(8) NOT NULL,
`loc` varchar(40) DEFAULT NULL,
PRIMARY KEY (`deptno`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
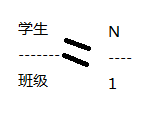
外键
表与表之间的关链
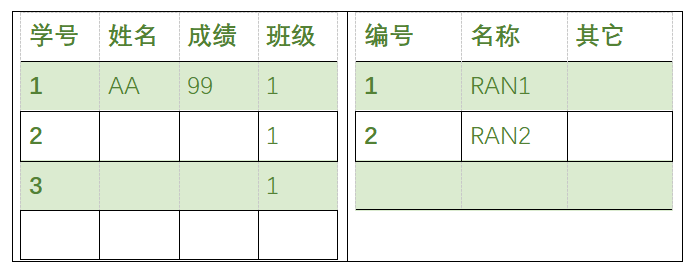
外键字段所引用的字段必须是另一个表的主键
 示例:
示例:
CREATE TABLE `tb_emp` (
`EMPNO` int(4) NOT NULL AUTO_INCREMENT,
`ENAME` varchar(10) DEFAULT NULL,
`JOB` varchar(9) DEFAULT NULL,
`MGR` int(4) DEFAULT NULL,
`HIREDATE` date DEFAULT NULL,
`SAL` int(7) DEFAULT NULL,
`COMM` int(7) DEFAULT NULL,
`DEPTNO` int(2) DEFAULT NULL,
PRIMARY KEY (`EMPNO`),
KEY `DEPTNO` (`DEPTNO`),
CONSTRAINT `tb_emp_ibfk_1` FOREIGN KEY (`DEPTNO`) REFERENCES `tb_dept` (`deptno`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
create/insert
|
Insert into 表名 (字段列表) values(值列表); |
示例:
insert into tb_dept (deptno,dname,loc) values(123,"123","123");
insert into tb_dept (deptno,dname,loc) values(null,"123","123");
insert into tb_dept (dname,loc) values("123","123");
update
|
Update 表名 set 字段1= 值1,字段1= 值1, where 条件 |
示例:
update tb_dept set dname= "abcd" ;
update tb_dept set dname= "abcd" where deptno = 125;
update tb_dept set dname= "abcd",loc="abcd" where deptno = 125;
update tb_dept set dname= "***"where deptno >40;
-- and && or ||
update tb_dept set dname= "1234" where deptno >40 and loc = "123";
update tb_dept set dname= "1111" where deptno >124 or loc = "123";
delete
|
Delete from 表名 where 条件; |
示例:
delete from tb_dept where deptno = 125;
select
|
SELECT 字段列表 from 表名 where 条件; |
示例:
简单查询
select deptno ,dname,loc from tb_dept;
select * from tb_dept;
select dname,loc from tb_dept;
select * from tb_dept where loc != "123";
模糊查询
查询部门中包含a的所有的记录
select * from tb_dept where loc like '%a%';
查询倒数第2个字母是a的部门的名称
select * from tb_dept where loc like '%a_';
关联查询
查询SCOTT所在的部门的名称
select dname from tb_dept where deptno =(select deptno from tb_emp where ename='SCOTT');
或
select tb_dept.dname
from tb_emp ,tb_dept
where tb_emp.ename='SCOTT' and tb_emp.deptno = tb_dept.deptno;
或
select tb_dept.dname
from tb_emp inner join tb_dept
on tb_emp.deptno= tb_dept.deptno
where tb_emp.ename= 'scott';
1.查找
SELECT [ALL | DISTINCT] [INTO 新数据表名]
FROM [表名|视图名]
〔WHERE 条件〕
GROUP BY 把查到的按什么标准分组
〔HAVING 指定分组搜索条件〕
〔ORDER BY 按什么顺序排序〕 〔升序|降序〕
解释:
all指明查询结果中可以显示值相同的列【默认】
distinct指如有值相同的列,只显示一个【NULL被认为是相同的值】
注意:SELECT...INTO...不能与COMPUTE子句一起使用
2.数据插入
INSERT INTO 表名 列名 VALUE 〔对应列的值〕
3.数据修改
UPDATE 表名 SET 列名=表达式 〔WHERE 条件〕
4.数据删除
DELETE FROM 表名|视图名 〔WHERE 条件〕
完整示例:
package com.runoob.test;
import java.sql.*;
public class MySQLDemo {
// JDBC 驱动名及数据库 URL
static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
static final String DB_URL = "jdbc:mysql://localhost:3306/RUNOOB";
// 数据库的用户名与密码,需要根据自己的设置
static final String USER = "root";
static final String PASS = "123456";
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
try{
// 注册 JDBC 驱动
Class.forName("com.mysql.jdbc.Driver");
// 打开链接
System.out.println("连接数据库...");
conn = DriverManager.getConnection(DB_URL,USER,PASS);
// 执行查询
System.out.println(" 实例化Statement对象...");
stmt = conn.createStatement();
String sql;
sql = "SELECT id, name, url FROM websites";
ResultSet rs = stmt.executeQuery(sql);
// 展开结果集数据库
while(rs.next()){
// 通过字段检索
int id = rs.getInt("id");
String name = rs.getString("name");
String url = rs.getString("url");
// 输出数据
System.out.print("ID: " + id);
System.out.print(", 站点名称: " + name);
System.out.print(", 站点 URL: " + url);
System.out.print("\n");
}
// 完成后关闭
rs.close();
stmt.close();
conn.close();
}catch(SQLException se){
// 处理 JDBC 错误
se.printStackTrace();
}catch(Exception e){
// 处理 Class.forName 错误
e.printStackTrace();
}finally{
// 关闭资源
try{
if(stmt!=null) stmt.close();
}catch(SQLException se2){
}// 什么都不做
try{
if(conn!=null) conn.close();
}catch(SQLException se){
se.printStackTrace();
}
}
System.out.println("Goodbye!");
}
}
Java ——JDBC数据库编程的更多相关文章
- Java JDBC数据库编程
课程 Java面向对象程序设计 一.实验目的 掌握数据库编程技术 二.实验环境 1.微型计算机一台 2.WINDOWS操作系统,Java SDK,Eclipse开发环境,Microsoft SQL ...
- Java JDBC 数据库链接小结随笔
Java JDBC 数据库链接小结随笔 一.链接数据库的步骤 二.关于Statement 和 PrepareStatement 两者区别 用法 三.关于 ResultSet 的一些小结 四.自定义 ...
- JDBC数据库编程(java实训报告)
文章目录 一.实验要求: 二.实验环境: 三.实验内容: 1.建立数据库连接 2.查询数据 2.1 测试结果 3.添加数据 3.1.测试结果 4.删除数据 4.1.测试结果 5.修改数据 5.1 测试 ...
- Java JDBC数据库链接
好久没有编写有关数据库应用程序啦,这里回顾一下java JDBC. 1.使用Java JDBC操作数据库一般需要6步: (1)建立JDBC桥接器,加载数据库驱动: (2)连接数据库,获得Connect ...
- Java 之 数据库编程(JDBC)
1.JDBC a.定义:是一种用于执行SQL语句的Java API,它由一组用Java 语言编写的类和接口组成 b.操作步骤: ①加载驱动--告诉驱动管理器我们将使用哪一个数据库的驱动包 Class. ...
- Java高级篇(三)——JDBC数据库编程
JDBC是连接数据库和Java程序的桥梁,通过JDBC API可以方便地实现对各种主流数据库的操作.本篇将介绍一下如何使用JDBC操作数据库(以MySQL为例). 一.JDBC JDBC制定了统一访问 ...
- JDBC数据库编程
常识名词:ODBC ,JDBC,JDBC API ,JDBC Driver API 数据准备,续上节: JDBC编程流程 最基本的JDBC操作 本段内容主要完成JDBC的增删查改操作 packa ...
- JDBC数据库编程:PreparedStatement接口
使用PreparedStatement进行数据库的更新及查询操作. PreparedStatement PreparedStatement是statement子接口.属于预处理. 使用statemen ...
- java jdbc数据库操作
package shb.java.demo3; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQ ...
随机推荐
- [IIS]修改MaxFieldLength与MaxRequestBytes彻底解决Request Too Long的问题
当 IIS7/7.5 收到的请求头的长度超过16K(默认值),就会引发"Bad Request - Request Too Long. HTTP Error 400. The size of ...
- linux Nginx 的安装
确保安装了 gcc,openssl-devel,pcre-devel,zilb-devel 下载官网:http://nginx.org/ [root@localhost tools]# wget ht ...
- egon消失的一天,空虚寂寞冷,苑模块的时间
一.时间模块time python有三种表达时间的形式:时间戳.格式化字符串输出和元组. 时间戳:从1970年1月1日00:00:00开始按秒计算的偏移量,返回值是一个float型. 格式化字符串输出 ...
- CentOS7编译安装MySQL8.0
1.下载mysql8.0.16源码包和cmake源码包 cd /usr/local/srcwget https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-b ...
- java代码实现H5页面
public void getH5(HttpServletResponse response){ StringBuffer res=new StringBuffer(); res.append(&qu ...
- VS插件CodeRush for Visual Studio发布v18.2.9|附下载
CodeRush能帮助你以极高的效率创建和维护源代码.Consume-first 申明,强大的模板,智能的选择工具,智能代码分析和创新的导航以及一个无与伦比的重构集,在它们的帮助下能够大大的提高你效率 ...
- Day01_课后练习题
1.(将摄氏温度转化华氏温度)编写一个从控制台读取摄氏温度并将他转变为华氏温度并予以显示的程序.转换公式如下. Fahrenheit = (9 / 5) * celsius + 32 这里是这个程序 ...
- 弹性盒子FlexBox简介(一)
一.理解弹性盒子 弹性盒子是CSS3的一种新的布局模式. CSS3弹性盒子(Flexible Box或flexbox),是一种当页面需要适应不同的屏幕大小以及设备类型时,确保元素拥有恰当的行为的布局方 ...
- Wannafly挑战赛16 #E 弹球弹弹弹 splay+基环树+各种思维
链接:https://ac.nowcoder.com/acm/problem/16033来源:牛客网 有n个位置,标号为1到n的整数,m次操作,第i次操作放置一个弹球在b[i] xor c[i-1]处 ...
- 【CF1251E】Voting(贪心)
题意:有n个人,需要搞到全部n个人的票,搞到第i个人的票有两种方式:之前已经搞到mi个人的票,或者直接花费pi 问最小的搞到所有票的总代价 n<=2e5,1<=p[i]<=1e9,0 ...