重温spark基本原理
(一)spark特点:
1、高效,采用内存存储中间计算结果,并通过并行计算DAG图的优化,减少了不同任务之间的依赖,降低了延迟等待时间。
2、易用,采用函数式编程风格,提供了超过80种不同的Transformation和Action算子,如map,reduce,filter,groupByKey,sortByKey,foreach等。
3、通用,提供批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。
4、兼容,能够与很多开源组件兼容使用。
(二)基本概念:
- RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系。
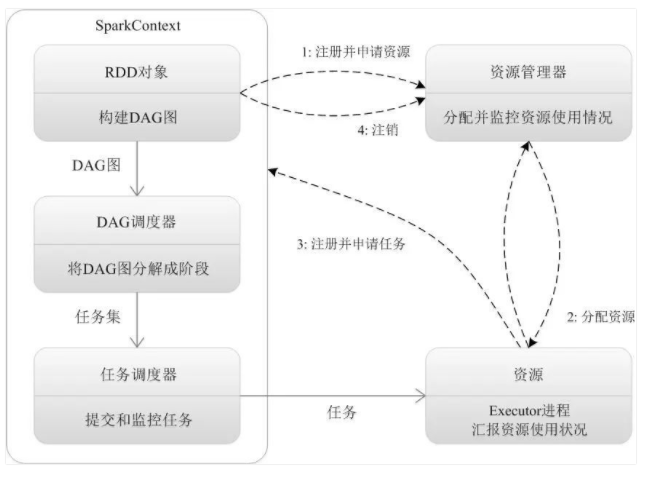
- Driver Program:控制程序,负责为Application构建DAG图。
- Cluster Manager:集群资源管理中心,负责分配计算资源。
- Worker Node:工作节点,负责完成具体计算。
- Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行Task,并为应用程序存储数据。
- Application:用户编写的Spark应用程序,一个Application包含多个Job。
- Job:作业,一个Job包含多个RDD及作用于相应RDD上的各种操作。
- Stage:阶段,是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”。
- Task:任务,运行在Executor上的工作单元,是Executor中的一个线程。
- 总结:Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成。Stage是作业调度的基本单位。
(三)部署模式:
- Local:本地运行模式,非分布式。
- Standalone:使用Spark自带集群管理器,部署后只能运行Spark任务。
- Yarn:Haoop集群管理器,部署后可以同时运行MapReduce,Spark,Storm,Hbase等各种任务。
- Mesos:与Yarn最大的不同是Mesos 的资源分配是二次的,Mesos负责分配一次,计算框架可以选择接受或者拒绝。
(四)RDD数据结构:
RDD全称Resilient Distributed Dataset,弹性分布式数据集,它是记录的只读分区集合,是Spark的基本数据结构。
RDD代表一个不可变、可分区、里面的元素可并行计算的集合。
一般有两种方式可以创建RDD,第一种是读取文件中的数据生成RDD,第二种则是通过将内存中的对象并行化得到RDD。
RDD的操作有两种类型:即Transformation操作和Action操作。
转换操作是从已经存在的RDD创建一个新的RDD,而行动操作是在RDD上进行计算后返回结果到 Driver。
Transformation操作都具有 Lazy 特性,即 Spark 不会立刻进行实际的计算,只会记录执行的轨迹,只有触发Action操作的时候,它才会根据 DAG 图真正执行。
操作确定了RDD之间的依赖关系。
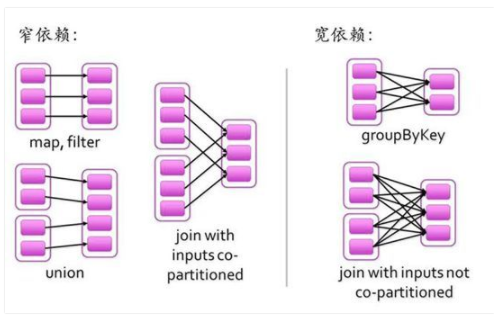
RDD之间的依赖关系有两种类型,即窄依赖和宽依赖。窄依赖时,父RDD的分区和子RDD的分区的关系是一对一或者多对一的关系。而宽依赖时,父RDD的分区和子RDD的分区是一对多或者多对多的关系。
宽依赖关系相关的操作一般具有shuffle过程,即通过一个Patitioner函数将父RDD中每个分区上key不同的记录分发到不同的子RDD分区。
重温spark基本原理的更多相关文章
- Spark基本原理
仅作<Spark快速大数据分析>学习笔记 定义:Spark是一个用来实现 快速 而 通用 的集群计算平台:(通用的大数据处理引擎:) 改进了原Hadoop MapReduce处理模型,体现 ...
- spark第一篇--简介,应用场景和基本原理
摘要: spark的优势:(1)图计算,迭代计算(2)交互式查询计算 spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存 为了满足挖掘分析与交互式实时查询的 ...
- 大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
http://www.csdn.net/article/2014-06-05/2820089 摘要:MapReduce在实时查询和迭代计算上仍有较大的不足,目前,Spark由于其可伸缩.基于内存计算等 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- FusionInsight大数据开发---Spark应用开发
Spark应用开发 要求: 了解Spark基本原理 搭建Spark开发环境 开发Spark应用程序 调试运行Spark应用程序 YARN资源调度,可以和Hadoop集群无缝对接 Spark适用场景大多 ...
- Google云平台使用方法 | Hail | GWAS | 分布式回归 | LASSO
参考: Hail Hail - Tutorial windows也可以安装:Spark在Windows下的环境搭建 spark-2.2.0-bin-hadoop2.7 - Hail依赖的平台,并行处 ...
- Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理 1.Spark SQL模块划分 2.Spark SQL架构--catalyst设计图 3.Spark SQL运行架构 4.Hive兼容性 1.Spark SQL模块划分 S ...
- spark第二篇--基本原理
==是什么 == 目标Scope(解决什么问题) 在大规模的特定数据集上的迭代运算或重复查询检索 官方定义 aMapReduce-like cluster computing framework de ...
- Spark 准备篇-基本原理
本章内容: 待整理 参考文献: <深入理解SPARK:核心思想与源码分析>(第2章) Spark的作业提交及运行流程的异同
随机推荐
- 一、JQJson数组
叙述:常用的数据格式无非三种(组装数据,传参传值) 一.数组 : 1.定义 var select = []; //或 var select = new Array(); 2.JS给一个数组赋值 sel ...
- thinkphp数据库连接
https://www.kancloud.cn/manual/thinkphp5/118059 一.配置文件定义 常用的配置方式是在应用目录或者模块目录下面的database.php中添加下面的配置参 ...
- 在父组件中,直接获取子组件数据-vue
1.通过 $ref 获取 主父组件中: <x-test ref="ch"></x-test> import XTest from '@/components ...
- 解决安装mysql-connector-odbc-5.3.2 错误1918……不能加载安装或转换器库……的BUG
还是在虚拟机Windows Server 2003上安装mysql-connector-odbc-5.3.2,装着装着就报错了,大致是“错误1918……不能加载安装或转换器库……”,问我Retry,I ...
- 关于memset
memset填充的是一个字节,比方下面的一段程序: #include <cstdio> #include <cstring> using namespace std; ]; i ...
- springboot整合 thymeleaf 案例
1.运行环境 开发工具:intellij idea JDK版本:1.8 项目管理工具:Maven 4.0.0 2.GITHUB地址 https://github.com/nbfujx/springBo ...
- Angular:自定义表单控件
分享一个最近写的支持表单验证的时间选择组件. import {AfterViewInit, Component, forwardRef, Input, OnInit, Renderer} from & ...
- [CSP-S模拟测试96]题解
以后不能再借没改完题的理由不写题解了…… A.求和 求$\sum \sum i+j-1$ 柿子就不化了吧……这年头pj都不考这么弱智的公式化简了…… 坑点1:模数不定,可能没有2的逆元,那么只要先把乘 ...
- js 和jquery
1. js 全称 javascript 是 web客户端 运行的 解释性语言.. 2. jquery 只不过是 js 封装 简化了 ajax 和 dhtml 的 一款js 框架而已. 简单来说 Jqu ...
- HTML与CSS中的文本个人分享
文本 标题元素 注意: 在一个HTML页面中最好只使用一个<h1>标题 因为浏览器只会抓取一个多了没用 示例代码: <body> <!-- 标题元素 - <h1&g ...