JVM基础系列第4讲:从源代码到机器码,发生了什么?
在上篇文章我们聊到,无论什么语言写的代码,其到最后都是通过机器码运行的,无一例外。那么对于 Java 语言来说,其从源代码到机器码,这中间到底发生了什么呢?这就是今天我们要聊的。
如下图所示,编译器可以分为:前端编译器、JIT 编译器和AOT编译器。下面我们逐个讲解。

前端编译器:源代码到字节码
之前我们说到:对于 Java 虚拟机来说,其实际输入的是字节码文件,而不是 Java 文件。那么对于 Java 语言而言,其实怎么将 Java 代码转化成字节码文件的呢?我们知道在 JDK 的安装目录里有一个 javac 工具,就是它将 Java 代码翻译成字节码,这个工具我们叫做编译器。相对于后面要讲的其他编译器,其因为处于编译的前期,因此又被成为前端编译器。
通过 javac 编译器,我们可以很方便地将 java 源文件翻译成字节码文件。就拿我们最熟悉的 Hello World 作为例子:
public class Demo{
public static void main(String args[]){
System.out.println("Hello World!");
}
}
我们使用 javac 命令编译上面这个类,便会生成一个 Demo.class 文件:
> javac Demo.java
> ls
Demo.java Demo.class
我们使用纯文本编辑器打开 Demo.class 文件,我们会发现是一连串的 16 进制二进制流。

我们运行 javac 命令的过程,其实就是 javac 编译器解析 Java 源代码,并生成字节码文件的过程。说白了,其实就是使用 javac 编译器把 Java 语言规范转化为字节码语言规范。javac 编译器的处理过程可以分为下面四个阶段:
第一个阶段:词法、语法分析。在这个阶段,JVM 会对源代码的字符进行一次扫描,最终生成一个抽象的语法树。简单地说,在这个阶段 JVM 会搞懂我们的代码到底想要干嘛。就像我们分析一个句子一样,我们会对句子划分主谓宾,弄清楚这个句子要表达的意思一样。
第二个阶段:填充符号表。我们知道类之间是会互相引用的,但在编译阶段,我们无法确定其具体的地址,所以我们会使用一个符号来替代。在这个阶段做的就是类似的事情,即对抽象的类或接口进行符号填充。等到类加载阶段,JVM 会将符号替换成具体的内存地址。
第三个阶段:注解处理。我们知道 Java 是支持注解的,因此在这个阶段会对注解进行分析,根据注解的作用将其还原成具体的指令集。
第四个阶段:分析与字节码生成。到了这个阶段,JVM 便会根据上面几个阶段分析出来的结果,进行字节码的生成,最终输出为 class 文件。
我们一般称 javac 编译器为前端编译器,因为其发生在整个编译的前期。常见的前端编译器有 Sun 的 javac,Eclipse JDT 的增量式编译器(ECJ)。
JIT 编译器:从字节码到机器码
当源代码转化为字节码之后,其实要运行程序,有两种选择。一种是使用 Java 解释器解释执行字节码,另一种则是使用 JIT 编译器将字节码转化为本地机器代码。
这两种方式的区别在于,前者启动速度快但运行速度慢,而后者启动速度慢但运行速度快。至于为什么会这样,其原因很简单。因为解释器不需要像 JIT 编译器一样,将所有字节码都转化为机器码,自然就少去了优化的时间。而当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。所以在实际情况中,为了运行速度以及效率,我们通常采用两者相结合的方式进行 Java 代码的编译执行。
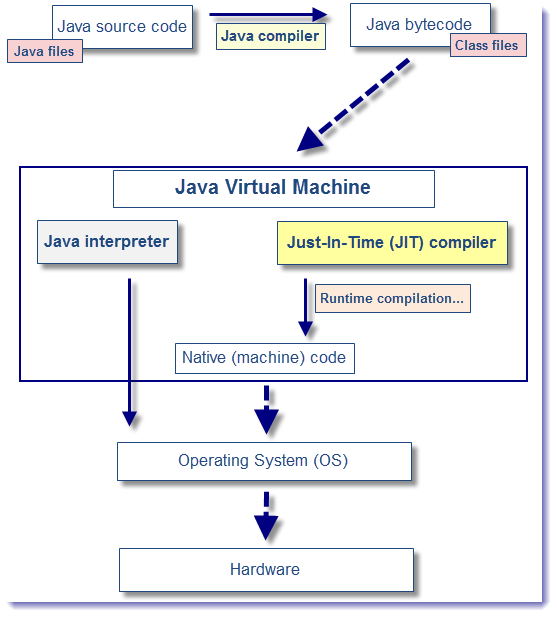
在 HotSpot 虚拟机内置了两个即时编译器,分别称为 Client Compiler 和Server Compiler。这两种不同的编译器衍生出两种不同的编译模式,我们分别称之为:C1 编译模式,C2 编译模式。
注意:现在许多人习惯上将 Client Compiler 称为 C1 编译器,将 Server Compiler 称为 C2 编译器,但在 Oracle 官方文档中将其描述为 compiler mode(编译模式)。所以说 C1 编译器、C2 编译器只是我们自己的习惯性称呼,并不是官方的说法。这点需要特别注意。

那么 C1 编译模式和 C2 编译模式有什么区别呢?
C1 编译模式会将字节码编译为本地代码,进行简单、可靠的优化,如有必要将加入性能监控的逻辑。而 C2 编译模式,也是将字节码编译为本地代码,但是会启用一些编译耗时较长的优化,甚至会根据性能监控信息进行一些不可靠的激进优化。
简单地说 C1 编译模式做的优化相对比较保守,其编译速度相比 C2 较快。而 C2 编译模式会做一些激进的优化,并且会根据性能监控做针对性优化,所以其编译质量相对较好,但是耗时更长。
那么到底应该选择 C1 编译模式还是 C2 编译模式呢?
实际上对于 HotSpot 虚拟机来说,其一共有三种运行模式可选,分别是:
- 混合模式(Mixed Mode) 。即 C1 和 C2 两种模式混合起来使用,这是默认的运行模式。如果你想单独使用 C1 模式或 C2 模式,使用
-client或-server打开即可。 - 解释模式(Interpreted Mode)。即所有代码都解释执行,使用
-Xint参数可以打开这个模式。 - 编译模式(Compiled Mode)。 此模式优先采用编译,但是无法编译时也会解释执行,使用
-Xcomp打开这种模式。
在命令行中输入 java -version 可以看到,我机器上的虚拟机使用 Mixed Mode 运行模式。

写到这里,我们了解了从 Java 源代码到字节码,再从字节码到机器码的全过程。本来到这里就应该结束了,但在我们 Java 中还有一个 AOT 编译器,它能直接将源代码转化为机器码。
AOT 编译器:源代码到机器码
AOT 编译器的基本思想是:在程序执行前生成 Java 方法的本地代码,以便在程序运行时直接使用本地代码。
但是 Java 语言本身的动态特性带来了额外的复杂性,影响了 Java 程序静态编译代码的质量。例如 Java 语言中的动态类加载,因为 AOT 是在程序运行前编译的,所以无法获知这一信息,所以会导致一些问题的产生。类似的问题还有很多,这里就不一一举例了。
总的来说,AOT 编译器从编译质量上来看,肯定比不上 JIT 编译器。其存在的目的在于避免 JIT 编译器的运行时性能消耗或内存消耗,或者避免解释程序的早期性能开销。
在运行速度上来说,AOT 编译器编译出来的代码比 JIT 编译出来的慢,但是比解释执行的快。而编译时间上,AOT 也是一个始终的速度。所以说,AOT 编译器的存在是 JVM 牺牲质量换取性能的一种策略。就如 JVM 其运行模式中选择 Mixed 混合模式一样,使用 C1 编译模式只进行简单的优化,而 C2 编译模式则进行较为激进的优化。充分利用两种模式的优点,从而达到最优的运行效率。
总结
在 JVM 中有三个非常重要的编译器,它们分别是:前端编译器、JIT 编译器、AOT 编译器。
前端编译器,最常见的就是我们的 javac 编译器,其将 Java 源代码编译为 Java 字节码文件。JIT 即时编译器,最常见的是 HotSpot 虚拟机中的 Client Compiler 和 Server Compiler,其将 Java 字节码编译为本地机器代码。而 AOT 编译器则能将源代码直接编译为本地机器码。这三种编译器的编译速度和编译质量如下:
- 编译速度上,解释执行 > AOT 编译器 > JIT 编译器。
- 编译质量上,JIT 编译器 > AOT 编译器 > 解释执行。
而在 JVM 中,通过这几种不同方式的配合,使得 JVM 的编译质量和运行速度达到最优的状态。
参考资料
- 深入理解JVM之前端编译器(一) | Gs Chen’s blog
- 深入浅出 JIT 编译器
- 如何通俗易懂地介绍「即时编译」(JIT),它的优点和缺点是什么? - 知乎
- 做一个 Hello World 级别的 JIT 编译器
- JIT中的C1和C2编译器 - 简书
- Understanding Java JIT Compilation with JITWatch, Part 1 Oracle 官方文档
- HotSpot VM 想研究HotSpot C2编译器编译过程,请教如何入手? - 讨论 - 高级语言虚拟机 - ITeye群组 深入研究 HotSpot C2 的编译过程
如果只是看,其实无法真正学会知识的。为了帮助大家更好地学习,我建了一个虚拟机群,专门讨论学习 Java 虚拟机方面的内容,每周针对我所发文章进行讨论答疑。如果你有兴趣,关注「陈树义」公众号,通过右下角菜单「入群交流」加我好友,小助手会拉你入群。
JVM基础系列文章目录
- JVM基础系列开篇:为什么要学虚拟机?
- JVM基础系列第1讲:Java 语言的前世今生
- JVM基础系列第2讲:Java 虚拟机的历史
- JVM基础系列第3讲:到底什么是虚拟机?
- JVM基础系列第4讲:从源代码到机器码,发生了什么?
- JVM基础系列第5讲:字节码文件结构
- JVM基础系列第6讲:Java虚拟机内存结构
- JVM基础系列第7讲:JVM类加载机制
- JVM基础系列第8讲:JVM 垃圾回收机制
- JVM基础系列第9讲:JVM垃圾回收器
- JVM基础系列第10讲:垃圾回收的几种类型
- JVM基础系列第11讲:JVM参数之堆栈空间配置
- JVM基础系列第12讲:JVM参数之查看JVM参数
- JVM基础系列第13讲:JVM参数之追踪类信息
- JVM基础系列第14讲:JVM参数之GC日志配置
- JVM基础系列第15讲:JDK性能监控命令
JVM基础系列第4讲:从源代码到机器码,发生了什么?的更多相关文章
- JVM基础系列第15讲:JDK性能监控命令
查看虚拟机进程:jps 命令 jps 命令可以列出所有的 Java 进程.如果 jps 不加任何参数,可以列出 Java 程序的进程 ID 以及 Main 函数短名称,如下所示. $ jps 6540 ...
- JVM基础系列第14讲:JVM参数之GC日志配置
说到 Java 虚拟机,不得不提的就是 Java 虚拟机的 GC(Garbage Collection)日志.而对于 GC 日志,我们不仅要学会看懂,而且要学会如何设置对应的 GC 日志参数.今天就让 ...
- JVM基础系列第13讲:JVM参数之追踪类信息
我们都知道 JVM 在启动的时候会去加载类信息,那么我们怎么得知他加载了哪些类,又卸载了哪些类呢?我们这一节就来介绍四个 JVM 参数,使用它们我们就可以清晰地知道 JVM 的类加载信息. 为了方便演 ...
- JVM基础系列第11讲:JVM参数之堆栈空间配置
JVM 中最重要的一部分就是堆空间了,基本上大多数的线上 JVM 问题都是因为堆空间造成的 OutOfMemoryError.因此掌握 JVM 关于堆空间的参数配置对于排查线上问题非常重要. tips ...
- JVM基础系列第10讲:垃圾回收的几种类型
我们经常会听到许多垃圾回收的术语,例如:Minor GC.Major GC.Young GC.Old GC.Full GC.Stop-The-World 等.但这些 GC 术语到底指的是什么,它们之间 ...
- JVM基础系列第9讲:JVM垃圾回收器
前面文章中,我们介绍了 Java 虚拟机的内存结构,Java 虚拟机的垃圾回收机制,那么这篇文章我们说说具体执行垃圾回收的垃圾回收器. 总的来说,Java 虚拟机的垃圾回收器可以分为四大类别:串行回收 ...
- JVM基础系列第8讲:JVM 垃圾回收机制
在第 6 讲中我们说到 Java 虚拟机的内存结构,提到了这部分的规范其实是由<Java 虚拟机规范>指定的,每个 Java 虚拟机可能都有不同的实现.其实涉及到 Java 虚拟机的内存, ...
- JVM基础系列第7讲:JVM 类加载机制
当 Java 虚拟机将 Java 源码编译为字节码之后,虚拟机便可以将字节码读取进内存,从而进行解析.运行等整个过程,这个过程我们叫:Java 虚拟机的类加载机制.JVM 虚拟机执行 class 字节 ...
- JVM基础系列第6讲:Java 虚拟机内存结构
看到这里,我相信大家对于一个 Java 源文件是如何变成字节码文件,以及字节码文件的含义已经非常清楚了.那么接下来就是让 Java 虚拟机运行字节码文件,从而得出我们最终想要的结果了.在这个过程中,J ...
随机推荐
- Python 列表切片陷阱:引用、复制与深复制
Python 列表的切片和赋值操作很基础,之前也遇到过一些坑,以为自己很懂了.但今天刷 Codewars 时发现了一个更大的坑,故在此记录. Python 列表赋值:复制"值"还是 ...
- eclipse 开发环境问题
1.jdk安装,环境变量设置.主要有两个: JAVA_HOME C:\Program Files\Java\jre7 JRE_HOME C:\Program Files\Java\jre7 2 ...
- mac抓包工具anyproxy
本文以 mac为代理,ios手机为客户端举例. 文档地址:http://anyproxy.io/ 1.环境配置: 安装 node :参考 https://www.jianshu.com/p/3 ...
- Django----列表分页(使用Django的分页组件)
目的:是为了实现列表分页 1.定制URL http://127.0.0.1:8000/blog/get_article?page=3之前定制URL是在url后增加了/id,这次使用参数的方式 def ...
- JVM调优入门之初探
JVM:程序计数器,jvm栈,本地方法栈,堆,方法区 JVM:虚拟机内存又分有:年轻代(eden,servivor s0,servivor s1),年老代(tenured),永久代() 问题1:如何查 ...
- python 判断连个 Path 是否是相同的文件夹
python 判断连个 Path 是否是相同的文件夹 import os os.path.normcase(p1) == os.path.normcase(p2) normcase() 在 windo ...
- Linux学习之基本操作命令
目录基本操作命令 列目录内容ls ls [options] [files] #options是可选参数 常用可选参数:-a 所有文件及目录 -A 等同于-a,但是不列出.以及.. -l 长格 ...
- 关于eclipse使用thymeleaf时,提示标签不显示及后续问题的解方法
因为thymeleaf 使用快捷键提示,不提示标签信息. 在使用网上说的的install new software安装插件的时候 报错: Unable to read repository at ht ...
- ABAQUS/CAE——Context
Part(部分) 用户在Part单元内生成单个部件,可以直接在ABAQUS/CAE环境下用图形工具生成部件的几何形状,也可以从其他的图形软件输入部件.详细可参考ABAQUS/CAE用户手册第15章. ...
- Winform消息与并行的形象比喻
有一次我给同事讲述跨线程调用时使用了高速行驶的并行列车来比喻,感觉比较形象. 线程列车 多线程就像多个并行的列车,每个线程在各自的轨道上不断向前行驶.主界面所在的线程称为UI线程,也叫主线程,主线程依 ...