Ehcache 3.7文档—基础篇—Tiering Options
Ehcache支持分层缓存的概念,这节主要介绍不同的配置选项,同时也解释了规则和最佳实践。
一. 数据缓存到堆外
当在cache中除了有heap层之外,有一些需要注意的:
- 添加一个key-value到cache时,意味着key和value要被序列化。
- 从cache中读取key-value时,意味着key和value能被反序列化。
基于上述两点,你需要认识到数据应该使用二进制表示,并且考虑何如进行序列化和反序列化,因为他在cache性能中是重要的指标。你可以参考Seializers章节来了解序列化和反序列化。
这也说明了某些配置在纸面上说有意义,但是在实际使用中可能不能提供最佳性能。
二. 单层设置
所有的层级配置都可以是单独使用的,例如你可以单独使用offheap或者clustered的cache。
下面列出一些单层配置:
- heap
- offheap
- disk
- clustered
简单的定义一个单层配置:
CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class, (1)
ResourcePoolsBuilder.newResourcePoolsBuilder().offheap(2, MemoryUnit.GB)).build();(2)
(1). 在configuration builder中首先配置key和value的类型。
(2). 指定想使用哪个存储层,这里我们只使用offheap层。
1. Heap层
The starting point of every cache and also the faster since no serialization is necessary. You can optionally use copiers (see the section Serializers and Copiers) to pass keys and values by-value, the default being by-reference.
Heap层的大小可以按照entries或者字节来分配。
ResourcePoolsBuilder.newResourcePoolsBuilder().heap(10, EntryUnit.ENTRIES); (1)
//or
ResourcePoolsBuilder.heap(10); (2)
//or
ResourcePoolsBuilder.newResourcePoolsBuilder().heap(10, MemoryUnit.MB); (3)
(1). heap中只允许存储10个entries,当超出时会删除某些entry。
(2). 一个简版的指定10个entries。
(3). 指定heap大小为10MB,超出时会删除某些entry。
按照字节来分配heap大小存在的问题:
除了heap层外,其他层计算cache的大小是很容易的。你可以通过计算序列化后entries的大小来增加或减少缓存的大小。
但是当heap层使用字节大小来代替entries个数来设置heap size时,就有点复杂了。
缓存数据的大小和数据结构影响了运行时性能。
CacheConfiguration<Long, String> usesConfiguredInCacheConfig = CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.KB) (1)
.offheap(10, MemoryUnit.MB)) (2)
.withSizeOfMaxObjectGraph(1000)
.withSizeOfMaxObjectSize(1000, MemoryUnit.B) (3)
.build(); CacheConfiguration<Long, String> usesDefaultSizeOfEngineConfig = CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.KB))
.build(); CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.withDefaultSizeOfMaxObjectSize(500, MemoryUnit.B)
.withDefaultSizeOfMaxObjectGraph(2000) (4)
.withCache("usesConfiguredInCache", usesConfiguredInCacheConfig)
.withCache("usesDefaultSizeOfEngine", usesDefaultSizeOfEngineConfig)
.build(true);
(1). 这将会限制heap层使用的内存的大小,并且又会有一个计算对象大小的成本。
(2). 设置offheap大小为10MB。
(3). 可以通过额外两个参数更进一步的设置大小,第一个参数是指定了当遍历对象图时最大的对象数量(默认是1000),第二个参数定义了单个对象大小的最大值(默认是Long.MAX_VALUE),如果超过任何一个配置的大小,那么entry将不能被存进cache。
(4). 提供了默认的配置给CacheManager,如果有显示定义的,那么将覆盖这两个值。
2. Off-heap层
如果你想使用off-heap,你需要定义Resuource Pool并且指定你想要分配的空间大小。
ResourcePoolsBuilder.newResourcePoolsBuilder().offheap(10, MemoryUnit.MB);(1)
(1). 只分配了10MB给off-heap,当超出时会删除某些entry。
上面的例子只分配很小的off-heap空间,你可以分配更多的空间来使用。
记住数据存储在off-heap,需要进行序列化和反序列化,所以他的速度会比heap层慢。
你可以把在heap中影响GC性能的数据,存储在off-heap。
不要忘了设置java 运行时参数 -XX:MaxDirectMemorySize选项,他的大小根据off-heap的大小来设置。
3. Disk层
对于Disk层,数据存储在磁盘上,这个磁盘越快那么访问的数据也就越快
PersistentCacheManager persistentCacheManager = CacheManagerBuilder.newCacheManagerBuilder() (1)
.with(CacheManagerBuilder.persistence(new File(getStoragePath(), "myData"))) (2)
.withCache("persistent-cache", CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder().disk(10, MemoryUnit.MB, true)) (3)
)
.build(true); persistentCacheManager.close();
(1). 获得一个PersistentCacheManager,它比普通的CacheManager多了destory caches。
(2). 提供数据存储的位置
(3). 给cache中使用的Disk,定义一个resource pool,第三个参数是一个boolean类型的,它用来决定是否将Disk pool持久化。如果设置成true,那么就持久化存储。当使用两个参数的版本时disk(long,MemoryUnit)这个pool不会被持久化。
上面的例子分配了很小的内存空间,你可以分配更多的空间来使用。
持久化意味着,当JVM重启时,cache中所有的东西都会保存下来,并且启动后会在相同的位置创建持久化的CacheManager。
注意:Disk层不能在CahceManager之间共享,在同一时间一个CacheManager只能有一个持久化目录。
记住数据存储在磁盘,必须要序列化/反序列化并且要读/写到磁盘中,所以他的速度要比heap和off-heap慢很多。所以在以下情况使用磁盘存储:
- 有大量的数据,不适合在off-heap中储存。
- 磁盘的速度大于正在缓存的速度。
- 数据需要持久化
注意:Ehcache 3只提供了在正常调用关闭时(close())才会持久化数据,如果jvm崩溃那么数据就不能完整性,在重启后,Ehcache会检测到CacheManager没有正常的关闭并且会在使用前清除磁盘存储的数据。
磁盘存储被分成多段,提供并发访问的能力,所以持有以打开文件的指针,默认是16。有时你可能需要减小并发量,节省资源你就需要减小段的数量。
String storagePath = getStoragePath();
PersistentCacheManager persistentCacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.with(CacheManagerBuilder.persistence(new File(storagePath, "myData")))
.withCache("less-segments",
CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder().disk(10, MemoryUnit.MB))
.add(new OffHeapDiskStoreConfiguration(2)) (1)
)
.build(true); persistentCacheManager.close();
(1). 定义一个OffHeapDiskStoreConfiguration实例指定段的数量。
4. 集群存储
集群层意味着客户端连接到Terracotta服务组,那里存储着cahe,这也可以作为jvms之间的共享cache。
二. 多层配置
如果你想使用多层存储,那么你必须遵守一些约定:
- 必须要有heap层,这是当前实现的限制
- Disk层和Clustered层不能共存,这个限制是必须的,因为包含两层的jvm生命周期比包含单个的jvm生命周期长,在重启时会导致兼容性问题。
- 各个层级之间应该按照大小排成金字塔形状,这是因为层之间相互依赖,最快的层在最顶上,最慢的层在最底下。通常来说heap比机器中所有内存(off-heap)受到的限制更多,而off-heap比disk或cluster受到的限制多。所以就有了金字塔型的设置。
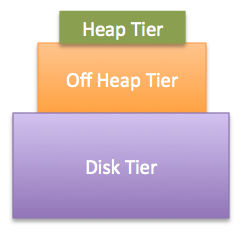
Ehcache要求,heap大小 < off-heap大小 < disk大小,虽然Ehcache无法验证 基于count-entry配置的heap 和 基于字节配置的off-heap和cluster大小关系,但是在测试时用户要保证这点。
根据上面的说明,如下配置是有效的:
- heap + offheap
- heap + offheap + disk
- heap + offheap + clustered
- heap + disk
- heap + clustered
如下是使用heap,offheap和clustered的例子
PersistentCacheManager persistentCacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.with(cluster(CLUSTER_URI).autoCreate()) (1)
.withCache("threeTierCache",
CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, EntryUnit.ENTRIES) (2)
.offheap(1, MemoryUnit.MB) (3)
.with(ClusteredResourcePoolBuilder.clusteredDedicated("primary-server-resource", 2, MemoryUnit.MB)) (4)
)
).build(true);
(1). 指定集群信息,告诉怎么去连接Terracotta服务集群。
(2). 定义一个heap层,这是最小最快的存储层。
(3). Define the offheap tier. Next in line as cacheing tier.
(4). Define the Clustered tier. The authoritative tier for this cache.
三. Resource pools
层的设置是通过使用resource pools,大多数使用ResourcePoolsBuilder。来看一下之前的一个例子
PersistentCacheManager persistentCacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.with(CacheManagerBuilder.persistence(new File(getStoragePath(), "myData")))
.withCache("threeTieredCache",
CacheConfigurationBuilder.newCacheConfigurationBuilder(Long.class, String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, EntryUnit.ENTRIES)
.offheap(1, MemoryUnit.MB)
.disk(20, MemoryUnit.MB, true)
)
).build(true);
这个cache使用了3层(heap,offheap,disk)。这些层被创建并连接起来都是通过使用ResourcePoolsBuilder。层的声明顺序是没有关系的,因为每个层都有一个height,层的高度越高,客户就会越会先使用该层。
resource pool只是一个配置信息,它不是一个真正的pool,不可以在多个cache之间共享,对于理解这点非常重要。考虑下面的这段代码:
ResourcePools pool = ResourcePoolsBuilder.heap(10).build(); CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.withCache("test-cache1", CacheConfigurationBuilder.newCacheConfigurationBuilder(Integer.class, String.class, pool))
.withCache("test-cache2", CacheConfigurationBuilder.newCacheConfigurationBuilder(Integer.class, String.class, pool))
.build(true);
最终你会得到两个cache,每个都包含了10个entries。而不是这两个cache共享10个entries。pool从来都不会在cache之间共享,除了clustered cache,它是可以被共享或独立使用的。
更新ResourcePools
可以给正在运行中的cache,调整大小。
注意:updateResourcePools()只允许你调整heap的大小,而不许调整pool的类型。所以你不能改变off-heap和disk层的大小。
ResourcePools pools = ResourcePoolsBuilder.newResourcePoolsBuilder().heap(20L, EntryUnit.ENTRIES).build(); (1)
cache.getRuntimeConfiguration().updateResourcePools(pools); (2)
assertThat(cache.getRuntimeConfiguration().getResourcePools()
.getPoolForResource(ResourceType.Core.HEAP).getSize(), is(20L));
(1). 你需要创建一个新的ResourcePools对象,并使用ResourcePoolsBuilder设置heap的大小,然后将该对象传给上述方法来触发更新机制。
(2). 为了更新ResourcePools的容量,可以使用RuntimeConfiguration中的updateResourcePools(ResourcePools)方法,然后将ResourcePools对象传进去触发更新操作。
四. Destory Persistent Tiers
Disk层和Clustered层是两个持久层,那就意味着当JVM停止时所有的数据仍然会保存在磁盘或集群中。
但是你可能想将他们全都删除掉,你可以使用PersistentCacheManager类,他有如下方法:
destory()
这个方法销毁所有与cache manager相关的数据(包括cache)。一定关闭这个CacheManager或者这个CacheManager没有初始化才可以调用该方法。同样,对于clustered层,不能有其他的CacheManager连接到当前要被关闭的CacheManager上。
destoryCache(String cacheName)
这个方法销毁了给定的cache,同样这个被销毁的cache不能正在被其他的CacheManager使用。
五. Sequence Flow for Cache Operations with Multiple Tiers(多层cache的操作顺序流)
为了理解在使用多层存储时,不同的缓存层发生了什么。下面有个Put和Get操作的例子。下面的序列图虽然简单但是仍然显示最重要的部分。
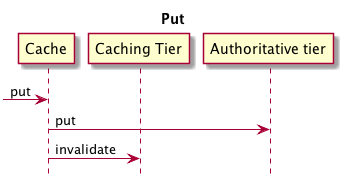
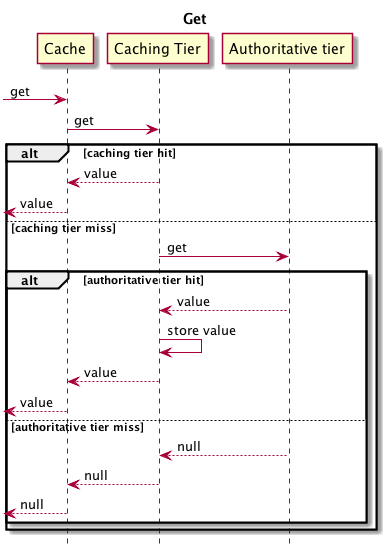
你需要注意一下几点:
- 当你添加一条数据时,它直接进入到authoritative层,它是最低的层。
- 下面的get操作会将该数据向上层推。
- 当然,只要一有数据添加到authoritative层,更高的层会使相应的数据无效。
- 如果高缓冲层中没有命中数据,那么就会一直查找到authoritative层。
注意:如果你的authoritative层越慢,那么你的put操作就会越慢。对于正常cache的要使用,这是没问题的。因为get操作的频率要大于put操作的频率。但是如果相反put频率大于get频率那可能意味着一开始你就不应该考虑使用cache。
Ehcache 3.7文档—基础篇—Tiering Options的更多相关文章
- Ehcache 3.7文档—基础篇—XML Configuration
你可以使用xml配置创建CacheManager,根据这个schema definition ( http://www.ehcache.org/documentation/3.7/xsds.html# ...
- Ehcache 3.7文档—基础篇—JCache aka JSR-107
一. 概述JCache Java临时缓存API(JSR-107),也被称为JCache,它是一个规范在javax.cache.API中定义的.该规范是在Java Community Process下开 ...
- Ehcache 3.7文档—基础篇—GettingStarted
为了使用Ehcache,你需要配置CacheManager和Cache,有两种方式可以配置java编程配置或者XML文件配置 一. 通过java编程配置 CacheManager cacheManag ...
- Mongoose学习参考文档——基础篇
Mongoose学习参考文档 前言:本学习参考文档仅供参考,如有问题,师请雅正 一.快速通道 1.1 名词解释 Schema : 一种以文件形式存储的数据库模型骨架,不具备数据库的操作能力 Model ...
- XWPFDocument创建和读取Office Word文档基础篇(一)
注:有不正确的地方还望大神能够指出,抱拳了 老铁! 参考API:http://poi.apache.org/apidocs/org/apache/poi/xwpf/usermodel/XWPFDo ...
- java 使用 POI 操作 XWPFDocumen 创建和读取 Office Word 文档基础篇
注:有不正确的地方还望大神能够指出,抱拳了 老铁! 参考 API:http://poi.apache.org/apidocs/org/apache/poi/xwpf/usermodel/XWPFDoc ...
- TypeScript学习文档-基础篇(完结)
目录 TypeScript学习第一章:TypeScript初识 1.1 TypeScript学习初见 1.2 TypeScript介绍 1.3 JS .TS 和 ES之间的关系 1.4 TS的竞争者有 ...
- HTML文档基础
一.HTML(Hyper Text Markup Language超文本标记语言)是一种用来制作超文本文档的简单标记语言,HTML在正文的文本中编写各种标记,通过Web浏览器进行编译和运行才干正确显示 ...
- Excelize 发布 2.6.0 版本,功能强大的 Excel 文档基础库
Excelize 是 Go 语言编写的用于操作 Office Excel 文档基础库,基于 ECMA-376,ISO/IEC 29500 国际标准.可以使用它来读取.写入由 Microsoft Exc ...
随机推荐
- SQLserver 数据库高版本无法还原到低版本的数据解决方法
sql server 数据库的版本只支持从上往下兼容.即高版本可以兼容低版本 .低版本不能兼容低版本.通常我们在开发时会用比较高的版本.但是部署到客户那边可能他们的数据库版本会比较低. 我们可以通过导 ...
- django中的反向解析
1,定义: 随着功能的增加会出现更多的视图,可能之前配置的正则表达式不够准确,于是就要修改正则表达式,但是正则表达式一旦修改了,之前所有对应的超链接都要修改,真是一件麻烦的事情,而且可能还会漏掉一些超 ...
- 更改 Ubuntu默认Python版本的问题
一般Ubuntu默认版本为2.x,之前运行一些程序,将默认版本修改为3.5,现在想修改为2.7. 之前的方法有些忘记,现在重新记录一下: 1.查看你系统中有哪些Python的二进制文件可供使用, ls ...
- centos禁止与开启ping设置
禁止ping: echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all 允许ping: echo 0 > /proc/sys/net/ipv4/i ...
- windows下实现定时重启Apache与MySQL方法
采用at命令添加计划任务.有关使用语法可以到window->“开始”->运行“cmd”->执行命令“at /”,这样界面中就会显示at命令的语法.下面我们讲解下如何让服务器定时启动a ...
- 今天聊一聊Java引用类型的强制类型转换
实际上基本类型也是存在强制类型转换的,这里简单提一下.概括来讲分为两种: 1.自动类型转换,也叫隐式类型转换,即数据范围小的转换为数据范围大的,此时编译器自动完成类型转换,无需我们写代码 2.强制类型 ...
- 二维前缀和好题hdu6514
#include<bits/stdc++.h> #define rep(i,a,b) for(int i=a;i<=b;i++) using namespace std; ]; )* ...
- SQL Update
转载至:https://www.liyongzhen.com/ UPDATE 语句 UPDATE语句用于修改表中的现有记录. UPDATE语法 1 2 3 UPDATE 表名 SET 字段1 = 值1 ...
- apache负载调优
Apache负载调优 watch -n 1 -d "pgrep httpd|wc -l" #apache动态查看连接数 ps aux | grep httpd | wc ...
- Java 模板模式
定义:定义了一个算法的骨架,并允许子类为一个或多个步骤提供实现 模板方法使得子类可以在不改变算法的结构的情况下,重新定义算法的某些步骤 类型:行为型 一次性实现一个算法的不变的部分,并将可变的行为留给 ...