第二节 pandas 基础知识
pandas 两种数据结构 Series和DataFrame
一 Series 一种类似与一维数组的对象
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
1.1 series的创建
Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False) data:列表/numpy一维数据/dic.
index:显示索引,格式为:[]
dtype:数据的类型
name:Series的唯一标识
copy:是否产生副本
两种创建方式:
()由列表或numpy数组创建
()由字典创建:不能在使用index.但是依然存在默认索引
方式一:由列表或numpy数组创建
#使用列表创建Series
Series(data=[1,2,3,4,5])
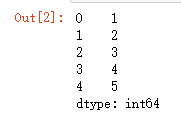
其中0,1,2,3,4是默认索引.
#使用numpy创建数组
arr=np.random.randint(50,100,size=(10,))
s2=Series(data=arr,index=['a','b','c','d','e','f','g','h','i','j'],name='s2') #index指定显示索引
s2

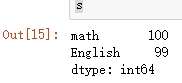
方式二:由字典创建
dic = {
'math':100,
'English':99
}
s = Series(data=dic)
s

注意:
使用字典创建Series,key作为显示索引,value作为数据
1.2 Series的索引和切片
1.2.1 索引
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型)。
(1) 显式索引:
- 使用index中的元素作为索引值
- 使用s.loc[](推荐):注意,loc中括号中放置的一定是显示索引
注意,此时是闭区间
(2) 隐式索引:
- 使用整数作为索引值
- 使用.iloc[](推荐):iloc中的中括号中必须放置隐式索引注意,此时是半开区间
s.math #属性索引,不推荐使用 s[0] #直接索引 s['math'] #直接的显式索引 s.loc['math'] #显式索引 s.iloc[0:2] #隐式索引
1.2.1 切片:隐式索引切片和显示索引切片
显示索引切片:index和loc
隐式索引切片:整数索引值和iloc
1.3 Series的基本概念
可以把Series看成一个定长的有序字典,向Series增加一行:相当于给字典增加一组键值对。
s.shape ---> (2,) s.values ---> array([100, 99], dtype=int64) s.index ----> Index(['math', 'English'], dtype='object') s.head(1) ----> 取第一条数据 s.tail(1) ----> 取最后一条数据
***去重
s = Series([1,1,2,2,3,3,4,5,6,6,6,7,8,8,0]) s.unique() #去重函数
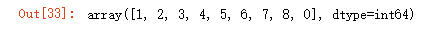
1.3 Series的运算
(1) + - * / (2) add() sub() mul() div() : s1.add(s2,fill_value=0)
s1.add(s2) #s1+s2
注意:
Series之间的运算在运算中自动对齐不同索引的数据,如果索引不对应,则补NaN.
1.4 索引不能完全对齐的加法运算详解
s1 = Series([1,2,3,4,5],index=['a','b','c','d','e'])
s2 = Series([1,2,3,4,5],index=['a','b','c','f','e'])

s3 = s1+s2 #数据清洗
s3
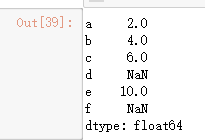
其中未对齐的数据,用NaN填充,这些数据属于无效数据.此时我们可以使用pd.isnull(),pd.notnull(),或s.isnull(),notnull()函数检测缺失数据.
s3.isnull() #检查数据是否为空值.

#要求去除错误数据 #第一步:获取数据的bool值一维数组 s3.notnull() #如果数据为空,返回false,不为空为True #第二步:使用获取的bool数组过滤数据,留下true的数据 s3[s3.notnull()]
二 DataFrame
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
2.1 DataFrame的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引。
使用字典创建的DataFrame后,则columns参数将不可被使用。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
2.1.1 使用ndarray创建DataFrame
DataFrame(data=np.random.randint(0,100,size=(3,3)),index=['a','b','c'],columns=['A','B','C'])

2.1.2 使用字典创建
dic = {
'name':['tom','jay','bobo'],
'salary':[10000,5000,6000]
}
DataFrame(data=dic,index=['one','two','three'])

2.1.3 属性
DataFrame属性:values、columns、index、shape
2.2 DataFrame的索引
(1) 对列进行索引 - 通过类似字典的方式 df['q']
- 通过属性的方式 df.q
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,
就是相应的列名。
(2) 对行进行索引
- 使用.loc[]加index来进行行索引
- 使用.iloc[]加整数来进行行索引
同样返回一个Series,index为原来的columns。
(3) 对元素索引的方法
- 使用列索引
- 使用行索引(iloc[3,1] or loc['C','q']) 行索引在前,列索引在后#创建数据
dic = {
'张三':[150,150,150,300],
'李四':[0,0,0,0]
}
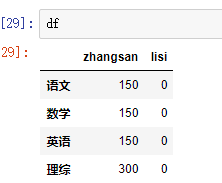
df = DataFrame(data=dic,index=['语文','数学','英语','理综'])
df
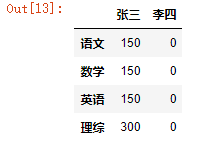
(1)对行索引
df['张三'] df.李四 #修改列索引
df.columns = ['zhangsan','lisi'] #获取前两列
df[['lisi','zhangsan']]
(2)对行索引
df.loc['数学'] df.iloc[1] df.loc[['语文','英语']]
(3)对元素索引
df.loc['理综','zhangsan'] #使用','隔开,格式:[行,列]
2.3 DataFrame的切片
【注意】 直接用中括号时: 索引表示的是列索引
切片表示的是行切片

df[0:2] #切行 df.iloc[:,0:2] #切列
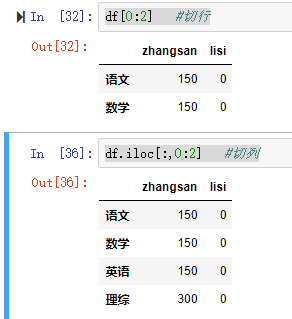
2.4 DataFrame的运算
(1) DataFrame之间的运算
同Series一样:
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
#假设张三期中考试数学被发现作弊,要记为0分,如何实现?
df.iloc[1,0] = 0

#李四因为举报张三作弊立功,期中考试所有科目加100分,如何实现?
df['lisi'] = df['lisi'] + 100
df

df = df + 10 #所有元素+10
df

三 处理丢失数据
有两种丢失数据:
- None
- np.nan(NaN)
#导包
import pandas as pd
from pandas import Series
from pandas import DataFrame
import numpy as np
3.1 None,np.nan
None是Python自带的,其类型为python object。因此,None不能参与到任何计算中。
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN。
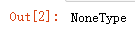
#查看None的数据类型
type(None)
查看np.nan(NaN)类型
type(np.nan)

3.2 pandas中的None与NaN
1) pandas中None与np.nan都视作np.nan
np.random.seed(2)
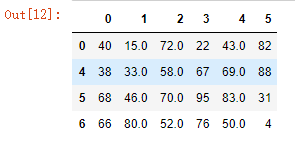
df = DataFrame(data=np.random.randint(0,100,size=(7,6)))
df

#将某些数组元素赋值为nan
df.iloc[1,2] = None
df.iloc[2,1] = np.nan
df.iloc[3,4] = None
df

2) pandas处理空值操作
isnull()
notnull()
dropna(): 过滤丢失数据
fillna(): 填充丢失数据
df.isnull()
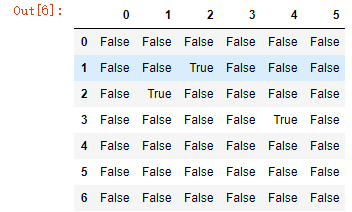
#自己书写bool一维数组
b = [True,False,False,False,True,True,True]
df.loc[b] #去除有NaN的行数据
使用方法获取bool数组
df.isnull().any(axis=0) #每一行只要有True ,则为True df.isnull().all(axis=0) #每一行全部为True ,则为True 固定搭配:# notnull() ===> all() isnull() ==> any()
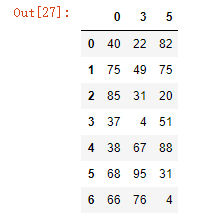
condition = df.notnull().all(axis=1)
condition

df.loc[condition]

3) 数据清洗函数
(1)df.dropna() 可以选择过滤的是行还是列(默认为行):axis中0表示行,1表示的列
(2)df.drop(labels=3,axis=1) #去除第3行数据 df.dropna(axis=0) #在drop系列的函数中 axis=0 行 1列
(3)df.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None) value:填充的数据,可以是某一个值,也可以是字典;
method:填充的方法,{'backfill', 'bfill', 'pad', 'ffill', None};
axis : {0 or 'index', 1 or 'columns'};
limit:填充的次数,int, default None
第二节 pandas 基础知识的更多相关文章
- RxJava2实战--第二章 RxJava基础知识
第二章 RxJava基础知识 1. Observable 1.1 RxJava的使用三步骤 创建Observable 创建Observer 使用subscribe()进行订阅 Observable.j ...
- Pandas基础知识图谱
所有内容整理自<利用Python进行数据分析>,使用MindMaster Pro 7.3制作,emmx格式,源文件已经上传Github,需要的同学转左上角自行下载或者右击保存图片.该图谱只 ...
- android内部培训视频_第二节 布局基础
第二节:布局入门 一.线性布局 需要掌握的属性: 1.orientation:排列方式 vertical:垂直 Horizontal:水平 2.weight:水平布局的权重 3.gravity:子控件 ...
- (转)JAVA AJAX教程第二章-JAVASCRIPT基础知识
开篇:JAVASCRIPT是AJAX技术中不可或缺的一部分,所以想学好AJAX以及现在流行的AJAX框架,学好JAVASCRIPT是最重要的.这章我给大家整理了一些JAVASCRIPT的基础知识.常用 ...
- 第二节 Python基础之变量,运算符,if语句,while和for循环语句
我们在上一节中,我们发现当我们用字符串进行一些功能处理的时候,我们都是把整个字符串写下来的,比如"jasonhy".startwith("j"),如果我们在程序 ...
- Pandas基础知识(二)
Pandas的索引对象 index的对象是不可以修改的如执行index[1] = 'f',会报错"Index does not support mutable operations" ...
- Pandas基础知识(一)
Pandas的主要结构有DataFrame和Series. 生成一个Series对象. 关于部分Series的索引操作. Series也可以通过字典生成. DataFrame是一个表格型的数据,它既有 ...
- 第二章 Java基础知识(下)
2.1.分支结构(if.switch) 2.1.1.if语句 格式一: if (关系表达式) { 语句体; } 流程一: ①首先计算关系表达式的值 ②如果关系表达式的值为true就执行语句体 ③如果关 ...
- 第二章 Java基础知识(上)
2.1.注释 单行注释 // 注释内容 多行注释 /* 注释内容 */ 文档注释 /**注释内容 */ 2.2.关键字 定义:在Java语言中被赋予特殊含义的小写单词 分类: 2.3.标识符 定义:标 ...
随机推荐
- Dubbo(二) —— dubbo配置
一.配置原则 JVM 启动 -D 参数优先,这样可以使用户在部署和启动时进行参数重写,比如在启动时需改变协议的端口. XML 次之,如果在 XML 中有配置,则 dubbo.properties ...
- asp.net core 系列 6 MVC框架路由(下)
一.URL 生成 接着上篇讲MVC的路由,MVC 应用程序可以使用路由的 URL 生成功能,生成指向操作的 URL 链接. 生成 URL 可消除硬编码 URL,使代码更稳定.更易维护. 此部分重点介绍 ...
- nginx部署~dotnetCore+mvc网站502
这个不是nginx的问题,也不是dotnet core的问题,也不是mvc的问题,更不是防火墙的问题! 原因在于这个SeLinux 把它关了就可以了 setsebool -P httpd_can_ne ...
- 【Python3爬虫】第一个Scrapy项目
Python版本:3.5 IDE:Pycharm 今天跟着网上的教程做了第一个Scrapy项目,遇到了很多问题,花了很多时间终于解决了== 一.Scrapy终端(scrapy shell) Sc ...
- LeetCode专题-Python实现之第7题:Reverse Integer
导航页-LeetCode专题-Python实现 相关代码已经上传到github:https://github.com/exploitht/leetcode-python 文中代码为了不动官网提供的初始 ...
- Understanding ROS Services and Parameters
service是nodes之间通信的一种方式,允许nodes send a request and recieve a response. rosservice rosparam roservice ...
- [Go] golang连接redis测试
go-redis的使用1.下载代码到GOPATH环境变量指定的目录比如我的是进入目录D:\golang\code\src\github.com\go-redis , 执行git clone https ...
- Java开发笔记(四十一)日历工具Calendar
前面的文章提到,Date是Java最早的日期工具,估计当时的设计师是个技术宅男,未经过充分调研就拍脑袋写下了Date的源码,造成该工具存在先天不足,比如getYear方法返回的不是纯正的公元纪年.ge ...
- Acer宏碁笔记本触摸板失效解决方法
打开windows设置,找到鼠标设置 之后,选择触摸板设置,将其开启 PS: 由于我是安装完驱动之后,才发现有这个触摸板设置的 如果找不到这个触摸板设置的哈,应该就是驱动安装完之后就有了 驱动的话去官 ...
- JS截取数字
Math是javascript的一个内部对象,该对象的方法主要是一些数学计算方法floor:下退 Math.floor(12.9999) = 12ceil:上进 Math.ceil(12.1) = 1 ...