Lucene的中文分词器
1 什么是中文分词器
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。
而中文的语义比较特殊,很难像英文那样,一个汉字一个汉字来划分。
所以需要一个能自动识别中文语义的分词器。
2. Lucene自带的中文分词器
StandardAnalyzer
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足对中文的需求。
3. 使用中文分词器IKAnalyzer
IKAnalyzer继承Lucene的Analyzer抽象类,使用IKAnalyzer和Lucene自带的分析器方法一样,将Analyzer测试代码改为IKAnalyzer测试中文分词效果。
如果使用中文分词器ik-analyzer,就在索引和搜索程序中使用一致的分词器ik-analyzer。
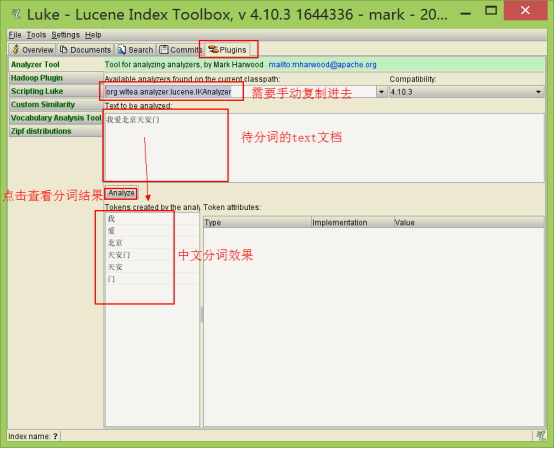
1. 使用luke测试IK中文分词
(1)打开Luke,不要指定Lucene目录。否则看不到效果
(2)在分词器栏,手动输入IkAnalyzer的全路径org.wltea.analyzer.lucene.IKAnalyzer
2. 改造代码,使用IkAnalyzer做分词器
添加jar包
修改分词器代码
|
// 创建中文分词器 Analyzer analyzer = new IKAnalyzer(); |
扩展中文词库
拓展词库的作用:在分词的过程中,保留定义的这些词
①在src或其他source目录下建立自己的拓展词库,mydict.dic文件,里面写入自定义的词
②在src或其他source目录下建立自己的停用词库,ext_stopword.dic文件停用词的作用:在分词的过程中,分词器会忽略这些词。
③在src或其他source目录下建立IKAnalyzer.cfg.xml,内容如下(注意路径对应):
|
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">mydict.dic</entry> <!-- 用户可以在这里配置自己的扩展停用词字典 --> <entry key="ext_stopwords">ext_stopword.dic</entry> </properties> |
如果想配置扩展词和停用词,就创建扩展词的文件和停用词的文件,文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件,那样的话,格式中是含有bom的。
Lucene的中文分词器的更多相关文章
- Lucene的中文分词器IKAnalyzer
分词器对英文的支持是非常好的. 一般分词经过的流程: 1)切分关键词 2)去除停用词 3)把英文单词转为小写 但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好. 国人林良益写的IK Ana ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- Lucene 03 - 什么是分词器 + 使用IK中文分词器
目录 1 分词器概述 1.1 分词器简介 1.2 分词器的使用 1.3 中文分词器 1.3.1 中文分词器简介 1.3.2 Lucene提供的中文分词器 1.3.3 第三方中文分词器 2 IK分词器的 ...
- (五)Lucene——中文分词器
1. 什么是中文分词器 对于英文,是安装空格.标点符号进行分词 对于中文,应该安装具体的词来分,中文分词就是将词,切分成一个个有意义的词. 比如:“我的中国人”,分词:我.的.中国.中国人.国人. 2 ...
- Lucene全文检索_分词_复杂搜索_中文分词器
1 Lucene简介 Lucene是apache下的一个开源的全文检索引擎工具包. 1.1 全文检索(Full-text Search) 1.1.1 定义 全文检索就是先分词创建索引,再执行搜索的过 ...
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- Lucene索引库维护、搜索、中文分词器
删除索引(文档) 需求 某些图书不再出版销售了,我们需要从索引库中移除该图书. 1 @Test 2 public void deleteIndex() throws Exception { 3 // ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
随机推荐
- 如莲开发平台(MIS基础框架、Java技术、B/S结构)
关于 「如莲」是一套MIS类系统基础框架,主要用于各类“管理信息系统”的开发,也适合做网站后台开发.可省去开发时的框架搭建.规范约定.权限管理等基础工作,直接专注于业务功能实现. 「如 ...
- flask 项目基本框架的搭建
综合案例:学生成绩管理项目搭建 一 新建项目目录students,并创建虚拟环境 mkvirtualenv students 二 安装开发中使用的依赖模块 pip install flask==0.1 ...
- python学习笔记2_条件循环和其他语句
一.条件循环和其他语句 1.print和import的更多信息. 1.1.使用逗号输出 //print() 打印多个表达式是可行的,用逗号隔开. 在脚本中,两个print语句想在一行输出 ...
- 百度地图引用时 报出A Parser-blocking, cross site (i.e. different eTLD+1) script
页面引入百度地图api时 chrome控制台报出警示问题 A Parser-blocking, cross site (i.e. different eTLD+1) script, http://ap ...
- 使用jsp,tag提取字符串中的单词
JSP中调用Tag在表单中输入字符串,提取其中的单词 参考代码:giveString.jsp <%@ page contentType="text/html; charset=GB23 ...
- selenium webdriver 如何实现将浏览器滚动条移动到某个位置
说明: 在做selenium webdriver 在做UI 自动化时,有些页面时使用懒加载的形式显示页面图片,如果在不向下移动滚动条时,获取到的图片会是网站的默认图片和真实的图片不相符. 所以研究了 ...
- SSM项目使用GoEasy 获取客户端上下线实时状态变化及在线客户列表
一.背景 上篇SSM项目使用GoEasy 实现web消息推送服务是GoEasy的一个用途,今天我们来看GoEasy的第二个用途:订阅客户端上下线实时状态变化.获取当前在线客户数量和在线客户列表.截止我 ...
- python工程师成长之路精品课程(全套)
python工程师成长之路精品课程(全套) 有需要联系我:QQ:1844912514 什么是Python? Python是一门面向对象的编程语言,它相对于其他语言,更加易学.易读,非常适合快速开发. ...
- ABP拦截器之UnitOfWorkRegistrar(二)
在上面一篇中我们主要是了解了在ABP系统中是如何使用UnitOfWork以及整个ABP系统中如何执行这些过程的,那么这一篇就让我们来看看UnitOfWorkManager中在执行Begin和Compl ...
- Git学习指北
learnGitBranching:一个可视化学习 git 的网站 learngitbranching.js.org,虽然项目有些悠久,如果学习 git 的话可以来玩下