时间复杂度O()与KMP算法
要得到某个结果,可以有很多种方式,算法就是为了寻找一条最快的方式。
而评判其好坏的标准就是时间复杂度。
O(1):
我们把执行一次的时间复杂度定义为O(1)
sum = a +b;
cout << sum <<endl;
O(n):
for(int i = 0; i < n ;++n)
{
//do something.
}
O(n2):
for(int i = 0; i < n ;++n)
{
for(int j = 0; j < n ;++n)
{
//do something.
}
}
我们会碰到这样的需求,从一个主字符串中找到一个子串,首先我们想到的是这种方法:
#include "stdafx.h"
#include<iostream>
#include<string>
using namespace std;
int findString(string S,string T)
{
int i = 0;
int j = 0;
while(i<S.length() && j < T.length())
{
if(T[j] == S[i])
{
i++;
j++;
}
else
{
j=0;
i = i-j+1;
}
}
if(j = T.length())
{
return i-j;
}
else
{
return -1;
}
}
void main()
{
int a = findString("adsfdjfxdf","xdf");
cout << a <<endl;
cin.get();
cin.get();
}
时间复杂度为O(n*m)这个好理解,每比较m次,主字符串位置加1,最坏的情况就是比较n*m次
而实际上,我们不需要这样做,例如如果要在主字符串中找abcd,那每次i可以加4,下次直接从第5个开始比较。这样的时间复杂度是O(n/m*m) = O(n),而实际上我们要找的子串有可能会重复,于是一种更通用的算法就产生了, 克努特一莫里斯一普拉特算法, 简称 KMP 算法。
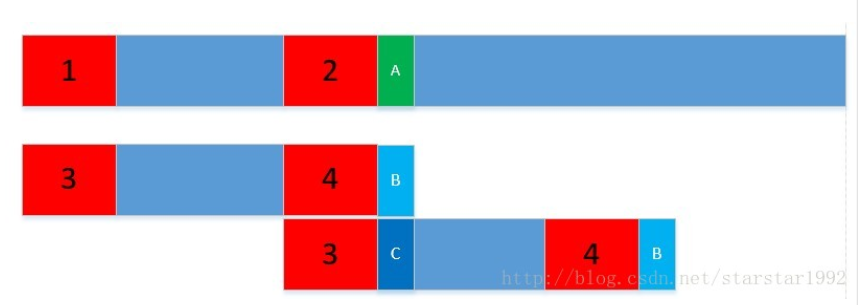
主要思想基于上图,找到的比较便于理解的图,上图中1,2,3,4为相同内容,中间蓝色为相同内容,当我们第一次比较时,发现A和B不同,那么下一次比较时,我们主串仍从A开
始,而子串则从C处开始,3和2相同的内容便不再需要比较。具体解释百度,其实一看就能感觉应该是这样,而i从上次比较失败的地方继续开始在代码上逻辑也不混乱。
因此KMP算法比较关键的便是如何得到子串失败后开始的这个点C,为了得到这个C的位置i,KMP这3个人设计了一个中间数组,来保存子串的若比较失败应该开始的下一个比较点。
next数组, 含义就是一个固定字符串的最长前缀和最长后缀相同的长度。
比如:abcjkdabc,那么这个数组的最长前缀和最长后缀相同必然是abc。
cbcbc,最长前缀和最长后缀相同是cbc。 这个子串的next数组是[0,0,1,2,0]
#include "stdafx.h"
#include<iostream>
#include<string>
using namespace std;
void get_next(string T,int* next)
{
next[0] = -1;
int i = 0;
int j = -1;
while(i<T.length())
{
if((j == (-1)) || (T[i] == T[j]))
{
next[++i] = ++j;
}
else
{
j = next[j]; //可以想象两个子串如上图一样的比较
}
}
}
int KMP(string S , string T)
{
int * next = new int[T.length()+1];
int i = 0;
int j = 0;
get_next(T, next);
while(i < int(S.length()) && j < int(T.length()))
{
if((-1 == j) || S[i] == T[j])
{
i++;
j++;
}
else
{
j=next[j]; //如上图4区域刚好是next[j]不需要比较,从c处开始比较
}
}
delete []next;
if(j == T.length())
{
return i-j;
}
else
{
return -1;
}
}
void main()
{
string S;
string T;
cout<<"please input the Mstring:"<<endl;
cin>>S;
cout<<endl<<"please input the Cstring:"<<endl;
cin >>T;
cout<<S.length()<<endl;
cout<<T.length()<<endl;
cout<<"the child String in the M number is: "<< KMP(S,T);
system("pause");
}
这个时间复杂度是O(m+n),因为是两个单循环相加。
写这个的时候 while(i < int(S.length()) && j < int(T.length())) 这句没有强转化int,导致j = -1时while循环只执行了一次未继续下去,后来看了一下length返回的并不是int,而是一个抽象的size,被这个错误搞得有点心态崩了。
O(1)
时间复杂度O()与KMP算法的更多相关文章
- KMP算法具体解释(转)
作者:July. 出处:http://blog.csdn.net/v_JULY_v/. 引记 此前一天,一位MS的朋友邀我一起去与他讨论高速排序,红黑树,字典树,B树.后缀树,包含KMP算法,只有在解 ...
- 字符串匹配算法之 kmp算法 (python版)
字符串匹配算法之 kmp算法 (python版) 1.什么是KMP算法 KMP是三位大牛:D.E.Knuth.J.H.MorriT和V.R.Pratt同时发现的.其中第一位就是<计算机程序设计艺 ...
- KMP 算法学习
KMP算法是用来做字符串匹配的.关于字符串匹配,最简单最容易想到的方法是暴利查找,使用双重for循环处理. 该方法的时间复杂度为O((n-m+1)*m) (n为目标串T长度,m为模式串P长度, 从T中 ...
- KMP算法的时间复杂度与next数组分析
一.什么是 KMP 算法 KMP 算法是一种改进的字符串匹配算法,用于判断一个字符串是否是另一个字符串的子串 二.KMP 算法的时间复杂度 O(m+n) 三.Next 数组 - KMP 算法的核心 K ...
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
- 经典KMP算法C++与Java实现代码
前言: KMP算法是一种字符串匹配算法,由Knuth,Morris和Pratt同时发现(简称KMP算法).KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的.比 ...
- [Algorithm] 字符串匹配算法——KMP算法
1 字符串匹配 字符串匹配是计算机的基本任务之一. 字符串匹配是什么?举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串& ...
随机推荐
- mssqlserver超级班助类 带详细用法
using System; using System.Collections; using System.Collections.Generic; using System.Configuration ...
- 【Linux】【Kernel】一个简单的内核模块例子
1.本地主机的参数 zhangjun@zhangjun-virtual-machine:~$ uname -a Linux zhangjun-virtual-machine 4.4.0-31-gene ...
- python实际练习1——简单购物车
要求实现 启动程序后,让用户输入工资,然后打印商品列表 允许用户根据商品编号购买商品 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒 可随时退出,退出时,打印已购买商品和余额 自己写的代码是 ...
- 大数据处理N!(21<N<2000)
输入: 每行输入1个正整数n,(0<n<1000 000) 输出: 对于每个n,输出n!的(十进制)位数 digit, 和最高位数firstNum.(n!约等于 firstNum * 10 ...
- Anagram字符串处理(STL真方便啊。。)
题意:给出一些字符串,认为各个字符个数相同的字符串就是相同的,不区分大小写,找出这些字符串中不与其他字符串相同的字符串并挨个输出 用char orgin[][]把每个字符串保存起来,然后对每个字符串都 ...
- 2018-软工机试-E-热河路(TLE只拿了90分,待思考)
单点时限: 2.0 sec 内存限制: 256 MB 没有人在热河路谈恋爱, 总有人在天亮时伤感 如果年轻时你没来过热河路, 那你现在的生活是不是很幸福 ——李志<热河> 奔跑.跌倒.奔跑 ...
- 虚拟机centos7服务器下,启动oracle11g数据库和关闭数据库
转载:https://blog.csdn.net/ShelleyWhile/article/details/74898033 一.前提条件:虚拟机centos7服务器下,已经安装好oracle11g数 ...
- 牛客网PAT乙级(Basic Level)真题-组个最小数 (20)
组个最小数 (20) 时间限制 1000 ms 内存限制 32768 KB 代码长度限制 100 KB 判断程序 Standard (来自 小小) 题目描述 给定数字0-9各若干个.你可以以任意顺序排 ...
- 如何删除node_modules
1.$ npm install -g rimraf 执行此命令 2.$ rimraf node_modules
- 【Coucurrency-CountDownLatch】-20161203-0002
简介 java异步任务相关的工具.主要用在某些线程需要等到其他线程完成某些操作后才能执行的场景. 等待线程需要显示的调用wait方法,表示线程当前挂起,需要等到countdownLatch到0才执行. ...