[数据结构] 2.2 Huffman树
注:本文原创,转载请注明出处,本人保留对未注明出处行为的责任追究。
1.Huffman树是什么
Huffman树也称为哈夫曼编码,是一种编码方式,常用于协议的制定,以节省传输空间。

A - F字母,出现的频率分别为:
A:5,B: 24, C:7,D:17,E:34,F:5,G:13
对比:
1)使用常规协议
如果我们将这些字母无论大小进行编码,一共是7个字母,因此协议规定用三位二进制数表示,传输完这105个字符,共需要105*3 = 315位。
2)使用Huffman树
如果我们按照Huffman树的规则(如上图),共需要 5*4 + 24 * 2 + 7*4 + 17*2 + 34*1+5*5+13*3 = 228位,共节省87位,大约节省27%的带宽占用。
2.Huffman树的原理
Huffman树是依据字符的出现频次,对字符进行二进制的编码,出现频次高的节点编码字符少,出现频次低的字节编码字符多。
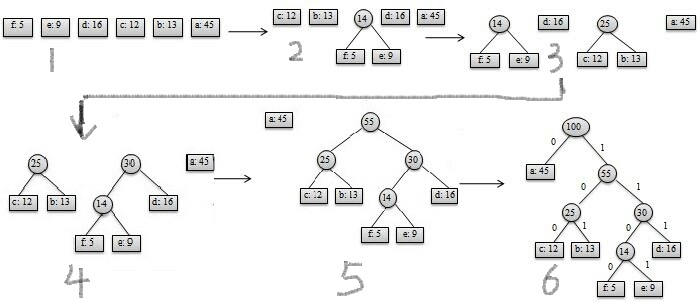
感谢: https://www.cnblogs.com/journal-of-xjx/p/6670464.html 博主:Jiaxin Tse
如图是huffman树的构建过程,字符的权重为出现频次。
构建过程:
STEP1:将权重最小的两个字符节点构建一个父节点,权重为两者权重之和
STEP1 进行 size - 1次 ,即可完成huffman树的构建。
编码过程: 给定字符串,以及"单词-频次Map" ,构建huffman树,将给定字符串转成二进制字符串
以字符d为例子,从根节点开始,右枝为1,左枝为0,因此d的编码就是111
给定 abdc => 0101111100
因为每一个被编码的字符节点是叶子节点,因此每一串二进制编码都有唯一对应的译码
解码过程: 给定二进制编码,以及"单词-频次Map",构建huffman树,将给定的二进制字符串转成字符串
0101111100 => abdc
3.Huffman树的三大操作
Huffman树常见的三大操作有 构建、编码、解码。上面给出了一些基本原理和使用,接下来是代码设计的思路。
Node 以及Tree :
/**
* 哈夫曼树
*/
public class HuffmanTree {
static class Node{
Character ch; // 保存被编码的字符
long frequency ; // 被编码的字符出现频次
Node left; // 左子节点
Node right; // 右子节点
Node parent; // 父节点
} static class Tree{
Node root;
List<Node> leafNodes;
}
1)构建huffman树
STEP1: 将每个字符抽象成一个节点,使用PriprotiesQueue这种排序的结构,按照Node的权值,也就是单词的出现频次为优先级排序
STEP2: 取出其中权值最小的两个节点,进行构建父节点,父节点权值为子节点权值之和。
假设初始的节点数(初始的队列大小)为size,那么需要size - 1次STEP2才能完成整颗huffman树的构建。
记得存储叶子节点的列表,以便编码的时候能从叶子节点向根节点进行拼接字符串。
/**
* 构建huffman树
* @return
*/
public static Tree buildHuffmanTree(
Map<Character,Long> charAndCounts){ Tree huffmanTree = new Tree();
huffmanTree.leafNodes = new ArrayList<Node>();
// 依据Node有序的队列
PriorityQueue<Node> priorityQueue = new PriorityQueue<Node>(); // 对每个字符进行遍历
for(Character ch : charAndCounts.keySet()){
long frequency = charAndCounts.get(ch);
Node node = new Node(ch,frequency);
// 存入叶子节点列表,以便于遍历
huffmanTree.leafNodes.add(node);
// 入堆
priorityQueue.add(node);
} // 进行建树操作,进行size-1次操作,每次取出两个最小的权值的节点,构建父节点并合并权值。
for(int i = 0 ; i < charAndCounts.size() - 1 ; i++ ){
Node node1 = priorityQueue.poll(); // 第一小 ,默认放右边
Node node2 = priorityQueue.poll(); // 第二小,默认放左边
Node top = new Node();
top.right = node1;
top.left = node2;
top.frequency = node1.frequency + node2.frequency; node1.parent = top;
node2.parent = top; priorityQueue.add(top);
} // 经过size-1次合并操作后,队列中只剩下一个节点
huffmanTree.root = priorityQueue.poll();
return huffmanTree;
}
2)编码 : 给定字符串,以及"单词-频次Map" ,构建huffman树,将给定字符串转成二进制字符串
首先使用 "单词-频次"Map 构建huffman树。
依次遍历每个huffman树的叶子节点,每个节点由叶子节点向根节点遍历,并进行 0 、1的拼接。
这样就生成了 Map<字符,二进制编码>表。
然后依次遍历给定字符串的每个字符,分别转成二进制编码拼接即可。
/**
* 进行编码
* @param str
* @param charAndCounts
* @return
*/
public static String encode(
String str,
Map<Character,Long> charAndCounts){
Map<Character,String> chAndEncoding = new HashMap<Character, String>();
// 1. 构建huffman树
Tree tree = buildHuffmanTree(charAndCounts);
// 2.依次遍历每个huffman树的叶子节点,每个节点由叶子节点向根节点遍历,并进行 0 、1的拼接。
List<Node> leafNodes = tree.leafNodes;
for(Node leafNode : leafNodes){ Node current = leafNode;
String binaryCode = "";
while(current != tree.root && current != null){ if(current.parent != null && current == current.parent.left){
binaryCode = "0" + binaryCode;
}else if(current.parent != null && current == current.parent.right){
binaryCode = "1" + binaryCode;
}
current = current.parent;
}
chAndEncoding.put(leafNode.ch,binaryCode);
}
System.out.println(chAndEncoding);
// 3.遍历每个字符进行编码
StringBuffer strEncoded = new StringBuffer();
for(char ch : str.toCharArray()){
strEncoded.append(chAndEncoding.get(ch));
}
return strEncoded.toString();
}
测试:
public static void main(String[] args) {
Map<Character,Long> map = new HashMap<Character, Long>();
map.put('a',5l);
map.put('b',24l);
map.put('c',7l);
map.put('d',17l);
map.put('e',34l);
map.put('f',5l);
map.put('g',13l);
System.out.println(encode("abcd",map));
}
结果:
{a=01001, b=10, c=0101, d=11, e=00, f=01000, g=011}
0100110010111
3)解码:给定二进制字符串,以及"单词-频次Map“,构建huffman树,将给定二进制字符串转成原未经编码的字符串。
首先使用"单词-频次"Map 构建huffman树。
然后按照给定的二进制字符串,挨个进行从根的查找,找到叶子节点后就转成原字符,从下一个字符串索引开始继续解码。
/**
* 解码过程
* @param binStr
* @param charsAndCounts
* @return
*/
public static String decode(
String binStr,
Map<Character,Long> charsAndCounts){
// 1.获得Huffman树
Tree tree = buildHuffmanTree(charsAndCounts); // 2.按照给定的二进制字符串,挨个进行从根的查找,找到叶子节点后就转成原字符,从下一个字符串索引开始继续解码。
StringBuffer originalStr = new StringBuffer();
int i = 0; while(i < binStr.length()){
char ch = '\0';
Node current = tree.root;
while(current.ch ==null && i < binStr.length()){
ch = binStr.charAt(i);
if(ch == '1'){
current = current.right;
}else if(ch == '0'){
current = current.left;
}
i++;
}
originalStr.append(current.ch);
}
return originalStr.toString();
}
测试:
public static void main(String[] args) {
Map<Character,Long> map = new HashMap<Character, Long>();
map.put('a',5l);
map.put('b',24l);
map.put('c',7l);
map.put('d',17l);
map.put('e',34l);
map.put('f',5l);
map.put('g',13l);
System.out.println(encode("abcd",map));
System.out.println(decode("0100110010111",map));
}
结果:
{a=01001, b=10, c=0101, d=11, e=00, f=01000, g=011}
0100110010111
abcd
abcd
[数据结构] 2.2 Huffman树的更多相关文章
- 数据结构之Huffman树与最优二叉树
最近在翻炒一些关于树的知识,发现一个比较有意思的二叉树,huffman树,对应到离散数学中的一种名为最优二叉树的路径结构,而Huffman的主要作用,最终可以归结到一种名为huffman编码的编码方式 ...
- 数据结构(三) 树和二叉树,以及Huffman树
三.树和二叉树 1.树 2.二叉树 3.遍历二叉树和线索二叉树 4.赫夫曼树及应用 树和二叉树 树状结构是一种常用的非线性结构,元素之间有分支和层次关系,除了树根元素无前驱外,其它元素都有唯一前驱. ...
- 【数据结构】Huffman树
参照书上写的Huffman树的代码 结构用的是线性存储的结构 不是二叉链表 里面要用到查找最小和第二小 理论上锦标赛法比较好 但是实现好麻烦啊 考虑到数据量不是很大 就直接用比较笨的先找最小 去掉最小 ...
- [数据结构与算法]哈夫曼(Huffman)树与哈夫曼编码
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- 数据结构与算法(周鹏-未出版)-第六章 树-6.5 Huffman 树
6.5 Huffman 树 Huffman 树又称最优树,可以用来构造最优编码,用于信息传输.数据压缩等方面,是一类有着广泛应用的二叉树. 6.5.1 二叉编码树 在计算机系统中,符号数据在处理之前首 ...
- 数据结构(二十七)Huffman树和Huffman编码
Huffman树是一种在编码技术方面得到广泛应用的二叉树,它也是一种最优二叉树. 一.霍夫曼树的基本概念 1.结点的路径和结点的路径长度:结点间的路径是指从一个结点到另一个结点所经历的结点和分支序列. ...
- 数据结构-二叉树(6)哈夫曼树(Huffman树)/最优二叉树
树的路径长度是从树根到每一个结点的路径长度(经过的边数)之和. n个结点的一般二叉树,为完全二叉树时取最小路径长度PL=0+1+1+2+2+2+2+… 带权路径长度=根结点到任意结点的路径长度*该结点 ...
- HUFFMAN 树
在一般的数据结构的书中,树的那章后面,著者一般都会介绍一下哈夫曼(HUFFMAN) 树和哈夫曼编码.哈夫曼编码是哈夫曼树的一个应用.哈夫曼编码应用广泛,如 JPEG中就应用了哈夫曼编码. 首先介绍什么 ...
- Huffman编码(Huffman树)
[0]README 0.1) 本文总结于 数据结构与算法分析, 源代码均为原创, 旨在 理解 "Huffman编码(Huffman树)" 的idea 并用源代码加以实现: 0.2) ...
随机推荐
- VUE2 项目 引入 leaflet.draw全过程
leaflet.draw的参考文档:http://leaflet.github.io/Leaflet.draw/docs/leaflet-draw-latest.html 这个网址不稳定,多刷新几 ...
- MySql修改数据表的基本操作(DDL操作)
1.查看数据库的基本语句:show databases; 2.选择相应的数据库进入语法:use 数据库名; 3.查看数据库中的表语法:show tables; 4.查看表的基本结构语句:desc 表名 ...
- web自动化测试python+selenium学习总结----python环境安装
一.python下载地址:https://www.python.org/downloads/ 二.双击python的.exe文件安装: 后面直接点击“next” 步骤二:选择安装在D:\python3 ...
- 切换用户后,/etc/profile的配置不起效
遇到的问题 在配置linux的时候,发现一个问题:su root切换到root用户后,/etc/profile 中配置的PATH不起效果. 问题分析和疑问 是不是~/.profile,~/.bashr ...
- Hadoop Mapreduce中wordcount 过程解析
将文件split 文件1: 分割结果: hello world ...
- 服务器被疑似挖矿程序植入,发现以及解决过程(建议所有使用sonatype/nexus3的用户清查一下)
此次服务器被植入挖矿程序发现起来较为巧合,首先是上周三开始,我通过sonatype/nexus3搭建的仓库间歇性崩溃,但是每次重新start一下也能直接使用所以没有彻底清查,去docker logs里 ...
- .eslintrc文件配置
{ // 环境定义了预定义的全局变量. "env": { //环境定义了预定义的全局变量.更多在官网查看 "browser": true, "node ...
- LeetCode Weekly Contest 121
上周因为感冒没有刷题,两个星期没有刷题,没手感了,思维也没有那么活跃了,只刷了一道,下个星期努力. 984. String Without AAA or BBB Given two integers ...
- Axure无法签出,团队配合时无法导入项目
SVN管理项目,团队多人合作维护 在Axure签出时,报错. 提示:无法创建目录 ... 设备上没有空间 SVN也检出失败 当然,还有其他情况 如:未将对象引用设置到对象的实例.等等 个别提示如下图: ...
- word模板导出的几种方式:第一种:占位符替换模板导出(只适用于word中含有表格形式的)
1.占位符替换模板导出(只适用于word中含有表格形式的): /// <summary> /// 使用替换模板进行到处word文件 /// </summary> public ...