tensorflow (七) k-means
tensorflow基础暂不介绍
Python 相关库的安装
pip install seaborn
安装 matplotlib:
pip install matplotlib
安装 python3-tk:
sudo apt-get install python3-tk -y
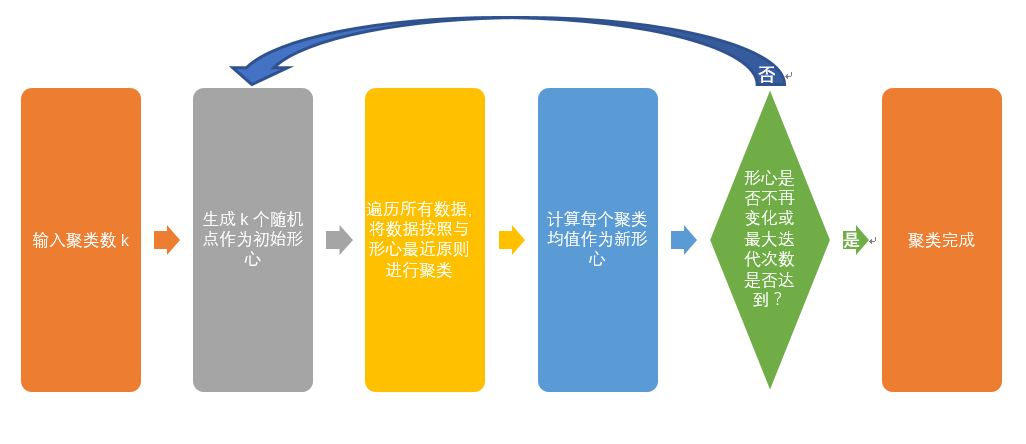
K-Means 聚类算法步简介
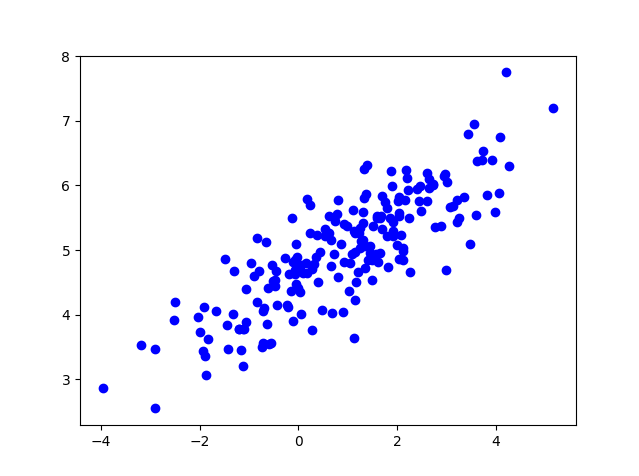
测试数据准备
200个数据进行 K-Means 聚类,首先我们先来了解一些生成的测试数据的形式#-*- coding:utf-8 -*-
# -*- coding: utf-8 -*-
import matplotlib
matplotlib.use('Agg')
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
############生成随机测试数据###############
sampleNo = 200;#生成数据数量
mu =3
# 二维正态分布
mu = np.array([[1, 5]])
Sigma = np.array([[1, 0.5], [1.5, 3]])
R = cholesky(Sigma)
srcdata= np.dot(np.random.randn(sampleNo, 2), R) + mu
plt.plot(srcdata[:,0],srcdata[:,1],'bo')
plt.savefig('data0.png')
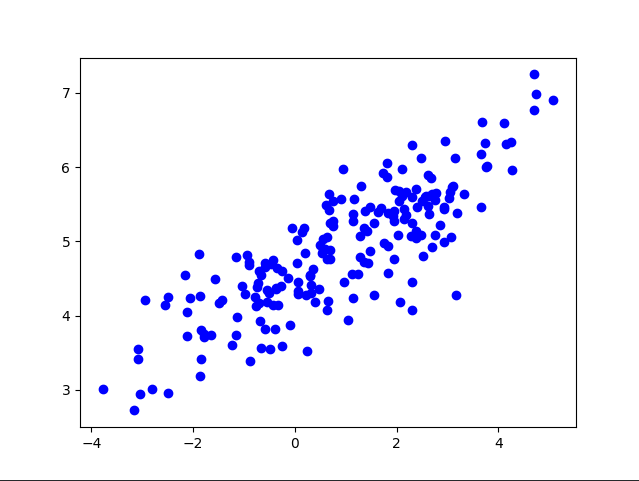
K-Means 聚类算法的实现
代码:
# -*- coding: utf-8 -*-
import matplotlib
matplotlib.use('Agg')
import numpy as np
from numpy.linalg import cholesky
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import tensorflow as tf
from random import choice, shuffle
from numpy import array
def KMeansCluster(vectors, noofclusters):
noofclusters = int(noofclusters)
assert noofclusters < len(vectors)
#找出每个向量的维度
dim = len(vectors[0])
#辅助随机地从可得的向量中选取形心
vector_indices = list(range(len(vectors)))
shuffle(vector_indices)
#计算图
graph = tf.Graph()
with graph.as_default():
#计算的会话
sess = tf.Session()
########从现有的点集合中抽取出一部分作为默认的中心点########
centroids = [tf.Variable((vectors[vector_indices[i]]))
for i in range(noofclusters)]
centroid_value = tf.placeholder("float64", [dim])
cent_assigns = []
for centroid in centroids:
cent_assigns.append(tf.assign(centroid, centroid_value))
assignments = [tf.Variable(0) for i in range(len(vectors))]
assignment_value = tf.placeholder("int32")
cluster_assigns = []
for assignment in assignments:
cluster_assigns.append(tf.assign(assignment,
assignment_value))
#############下面创建用于计算平均值的操作节点#############
mean_input = tf.placeholder("float", [None, dim])
mean_op = tf.reduce_mean(mean_input, 0)
#################用于计算欧氏距离的节点#################
v1 = tf.placeholder("float", [dim])
v2 = tf.placeholder("float", [dim])
euclid_dist = tf.sqrt(tf.reduce_sum(tf.pow(tf.subtract(
v1, v2), 2)))
centroid_distances = tf.placeholder("float", [noofclusters])
cluster_assignment = tf.argmin(centroid_distances, 0)
###################初始化所有的状态值###################
init_op = tf.global_variables_initializer()
sess.run(init_op)
#######################集群遍历#######################
#接下来在 K-Means 聚类迭代中使用最大期望算法,简单起见最大迭代次数直接设置为30次
noofiterations = 30
for iteration_n in range(noofiterations): #####################期望步骤#####################
#首先遍历所有的向量
for vector_n in range(len(vectors)):
vect = vectors[vector_n]
#计算给定向量与分配的形心之间的欧氏距离
distances = [sess.run(euclid_dist, feed_dict={
v1: vect, v2: sess.run(centroid)})
for centroid in centroids]
#下面可以使用集群分配操作,将算出的距离当做输入
assignment = sess.run(cluster_assignment, feed_dict = {
centroid_distances: distances})
#接下来为每个向量分配合适的值
sess.run(cluster_assigns[vector_n], feed_dict={
assignment_value: assignment}) ####################最大化的步骤####################
#基于上述的期望步骤,计算每个新的形心的距离从而使集群内的平方和最小
for cluster_n in range(noofclusters):
#收集所有分配给该集群的向量
assigned_vects = [vectors[i] for i in range(len(vectors))
if sess.run(assignments[i]) == cluster_n]
#计算新的集群形心
new_location = sess.run(mean_op, feed_dict={
mean_input: array(assigned_vects)})
#为每个向量分配合适的形心
sess.run(cent_assigns[cluster_n], feed_dict={
centroid_value: new_location}) #返回形心和分组
centroids = sess.run(centroids)
assignments = sess.run(assignments)
return centroids, assignments
############生成随机测试数据###############
sampleNo = 200;#生成数据数量
mu =3
# 数据遵从二维正态分布
mu = np.array([[1, 5]])
Sigma = np.array([[1, 0.5], [1.5, 3]])
R = cholesky(Sigma)
srcdata= np.dot(np.random.randn(sampleNo, 2), R) + mu
plt.plot(srcdata[:,0],srcdata[:,1],'bo')
plt.savefig('data.png')
############ kmeans 算法计算###############
k=4
center,result=KMeansCluster(srcdata,k)
print (center)
############利用 seaborn 画图############### res={"x":[],"y":[],"kmeans_res":[]}
for i in range(len(result)):
res["x"].append(srcdata[i][0])
res["y"].append(srcdata[i][1])
res["kmeans_res"].append(result[i])
pd_res=pd.DataFrame(res)
sns.lmplot("x","y",data=pd_res,fit_reg=False,size=5,hue="kmeans_res")
plt.show()
plt.savefig('kmeans.png')


参考:https://codesachin.wordpress.com/2015/11/14/k-means-clustering-with-tensorflow/
tensorflow (七) k-means的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- TensorFlow(七):tensorboard网络执行
# MNIST数据集 手写数字 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # ...
- tensorflow(七)
一.模型托管工具 TensorFlow Serving TensorFlow Serving支持生产级的服务部署,允许用户快速搭建从模型训练到服务发布的工作流水线. 工作流水线主要由三部分构成 (1) ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- TensorFlow 初级教程(三)
TensorFlow基本操作 import os import tensorflow as tf os.environ[' # 使用TensorFlow输出Hello # 创建一个常量操作( Cons ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- TensorFlow(二):基本概念以及练习
一:基本概念 1.使用图(graphs)来表示计算任务 2.在被称之为会话(Session)的上下文(context)中执行图 3.使用tensor表示数据 4.通过变量(Variable)维护状态 ...
随机推荐
- 算法(第四版)C# 习题题解——1.3.49 用 6 个栈实现一个 O(1) 队列
因为这个解法有点复杂,因此单独开一贴介绍. 那么这里就使用六个栈来解决这个问题. 这个算法来自于这篇论文. 原文里用的是 Pure Lisp,不过语法很简单,还是很容易看懂的. 先导知识——用两个栈模 ...
- Windows环境下利用anaconda3安装python版本的Xgboost
网上有各种不同安装Xgboost的教程,但是有些教程对于一个新手来说,照着做安装成功是很困难的.本人也是新手,第一次安装Xgboost的时候,照着某个教程做,结果总是安装不上,甚至想到要放弃.后来经一 ...
- 用Xshell在centos7下安装lnmp服务
虚拟机已创建好,本机已安装Xshell 一.准备工作:安装常用工具 1.1 yum install -y vim 备注:-y是同意安装过程中的询问,不被询问打断安装 vim:vim是一个类似于Vi的 ...
- DP一下,马上出发
简单DP i.May I ask you for a dance(体舞课软广植入) 这题的状态转移方程为:dp[i][j]=max(dp[i-1][j-1]+a[i][j],dp[i][j-1]);( ...
- 【转载】RESTful 架构风格概述
本文转载自https://blog.igevin.info/posts/restful-architecture-in-general/ 在移动互联网的大潮下,随着docker等技术的兴起,『微服务』 ...
- DRF认证组件流程分析
视图函数中加上认证功能,流程见下图 import hashlib import time def get_random(name): md = hashlib.md5() md.update(byte ...
- Win10下JDK下载与环境变量配置
一.JDK下载 1.JDK下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.ht ...
- 剑指offer 15:反转链表
题目描述 输入一个链表,反转链表后,输出新链表的表头. 法一:迭代法 /* public class ListNode { int val; ListNode next = null; ListNod ...
- 微信小程序外包 就找北京动软 专业承接微信小程序定制
很多人问为什么要开发微信小程序,微信小程序的“入口”在哪儿? 1.只有访问过的小程序,才会出现所谓的「入口」. 所有访问过得小程序都可以从微信首屏下面的「发现」点过去.(必须是最新版微信) 这个所谓的 ...
- 使用sphinx制作接口文档并托管到readthedocs
此sphinx可不是彼sphinx,此篇是指生成文档的工具,是python下最流行的文档生成工具,python官方文档即是它生成,官方网站是http://www.sphinx-doc.org,这里是一 ...