团队作业第六次—团队Github实战训练
作业描述
| 课程 | 软件工程1916|W(福州大学) |
|---|---|
| 团队名称 | 修!咻咻! |
| 作业要求 | 团队作业第六次—团队Github实战训练 |
| 团队目标 | 搭建一个相对公平公正的抽奖系统,根据QQ聊天记录,完成从统计参与抽奖人员颁布抽奖结果的基本流程。 |
| git项目 | https://github.com/huangquanhuan/live-project |
| 开发工具 | Vistual Studio |
团队信息
| 队员学号 | 队员姓名 | 个人博客地址 | git地址 |
| 221600126 | 刘忠燏 | http://www.cnblogs.com/Downstream-1998/ | https://github.com/Downstream1998 |
| 221600207 | 黄权焕 | https://www.cnblogs.com/hyry/ | https://github.com/huangquanhuan |
| 221600328 | 苏明辉 | https://www.cnblogs.com/ahuigg/ | https://github.com/398315418 |
| 221600330 | 吴可强 | https://www.cnblogs.com/masgak/ | https://github.com/masgak |
| 221600331 | 向鹏 | https://www.cnblogs.com/xiang-peng/ | https://github.com/Snug-XP |
作业正文
(一)组员分工和工作量比例
| 队员学号 | 队员姓名 | 分工 | 贡献度 |
| 221600126 | 刘忠燏 | 对数据的结构化处理,编写活动类和活动管理类 | 20 |
| 221600207 | 黄权焕 | 图形界面编辑,奖励类的编写,所有类与页面的交互和最终成品的调试改bug | 22 |
| 221600328 | 苏明辉 | 编写博客,抽奖类的编写 | 18 |
| 221600330 | 吴可强 | 附加作业的编写,博客编写 | 19 |
| 221600331 | 向鹏 | 人员类、管理人员类的编写,抽奖类的修正,最终成品的调试改bug | 21 |
(二)github 的提交日志截图
(三)程序运行截图
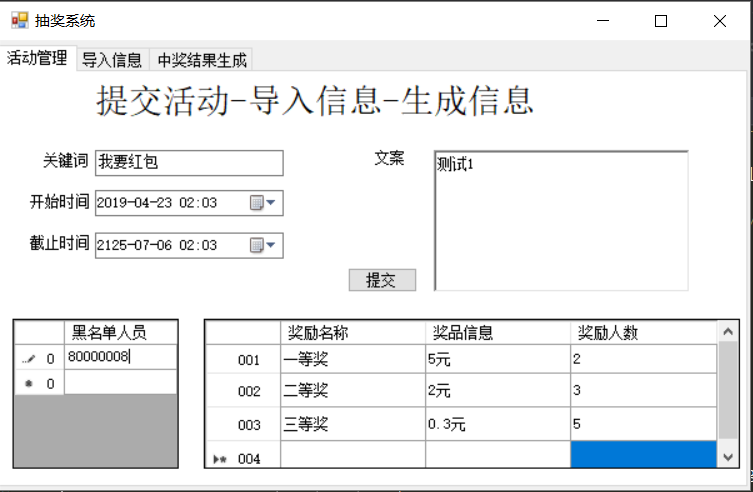
1、设置活动管理
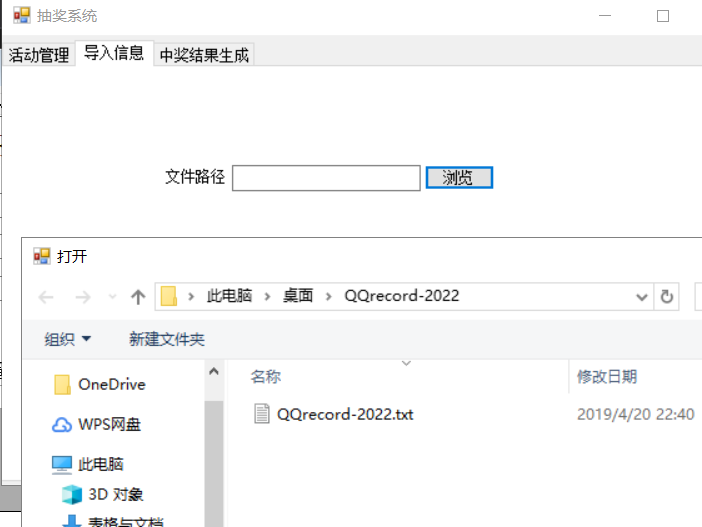
2、导入聊天记录
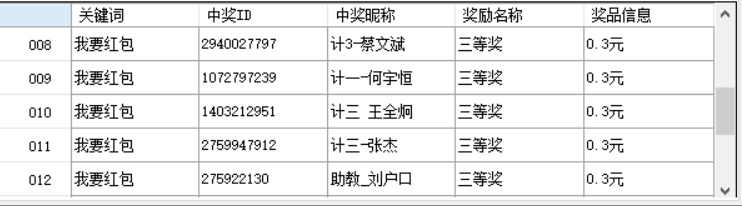
3、运行结果
(四)GUI界面
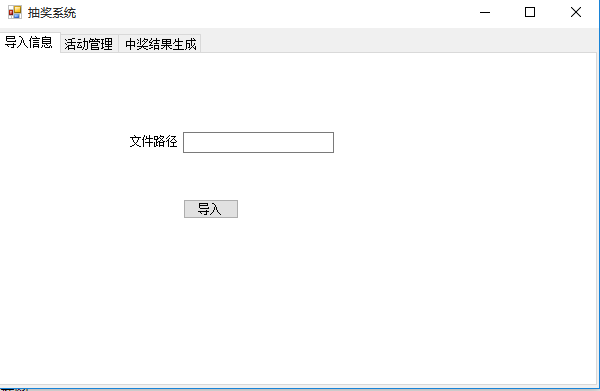
- 1、进入抽奖界面,并导入聊天文件路径
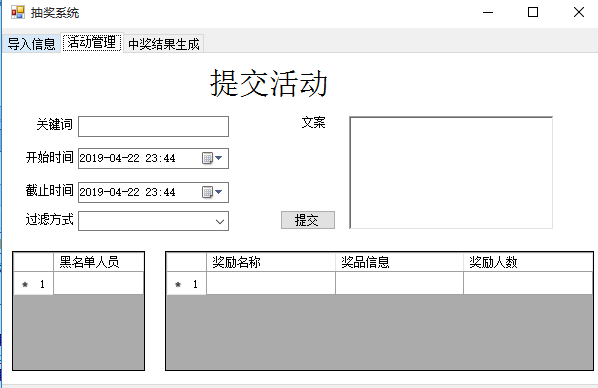
- 2、开始抽奖活动,管理员需要设置抽奖关键词、开始结束时间、文案、奖品相应信息、添加黑名单人员(恶意刷屏或机器号会自动进入)、选择过滤机制(不过滤、普通过滤、深度过滤),最后按下提交键开始抽奖
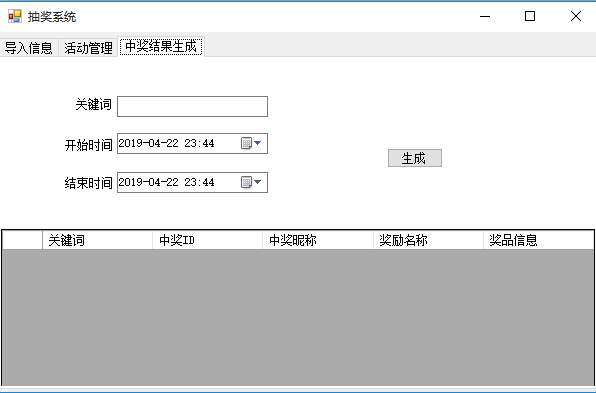
- 3、生成抽奖结果,界面显示抽奖关键词以及开始结束时间,管理员选择生成后列表上出现本次抽奖的关键词、中奖id与昵称,奖励名称与奖品信息
(五)基础功能实现
- 不过滤模式:剔除机器,所有参与抽奖的人,都纳入开奖范围。
- 普通模式:筛除只参与抽奖而无发表任何原创言论的用户(抽奖机器人),鼓励大家积极参与有意义的发言。
- 深度模式:为了使发言更有意义,减少灌水,对以下用户的中奖概率进行降权处理,只参与抽奖而无发表任何原创言论(抽奖机器人),只参与抽奖且只发送表情(水军)
核心算法介绍:
- 1、活跃度计算。抽奖发言+1,平时发言+2,刷屏发言(重复发一句话次数)>20时-50(修改身份=预警者),随后每重复一次-3,>100时-1008611(修改身份=危险者)。学生初始活跃=0;助教老师初始活跃-1008611;活跃度<1500000后不再减少(防止溢出)
- 2、抽奖机制:活动参与人员名单下 所有活跃度>0的人员进行排序。按2:3:5的比例分成三个层次:A B C。每一次决定抽奖人员时,按照5:3:2的概率决定实在A B C三个层中哪个层进行抽取,决定抽取层次后按随机数mod 层人数决定抽奖者下标。抽奖方式有以下好处:
(一):50%的中奖用户为高活跃人士。
(二)各层中奖概率为:
A 0.20.5 = 0.1
B 0.30.3 = 0.09
C 0.5*0.2 = 0.1 - 3、抽奖算法参考了这篇博客提到的Alias Method,将所有事件拼凑成为一个方形,从方形图片中可以得到两个数组:
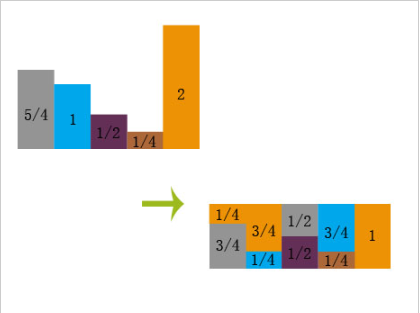
Prob: [3/4, 1/4, 1/2, 1/4, 1]
Alias: [4, 4, 0, 1, null] (记录非原色的下标)
之后就根据Prob和Alias获取其中一个物品
随机产生一列C,再随机产生一个数R,通过与Prob[C]比较,R较大则返回C,反之返回Alias[C]。
此方法决定了奖项归属于那一部分人群(高活跃度或低活跃度),最后在这个人群中选择一位作为获奖者。
(六)附加功能实现
1.由中奖消息形成祝贺海报
- 使用python pil库中的Image等属性,从获奖txt文件中分别读取获奖人员与奖项,最后打印在海报模板的相应位置

- 使用python pil库中的Image等属性,从获奖txt文件中分别读取获奖人员与奖项,最后打印在海报模板的相应位置
2.对提供的聊天记录进行分析
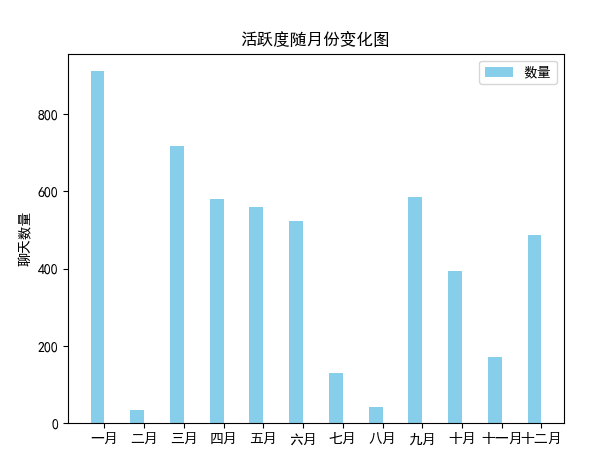
热度随月份变化的条形图,对聊天数据进行正则匹配,将统计完的数据存储到列表中,使用plt绘画出相应图形
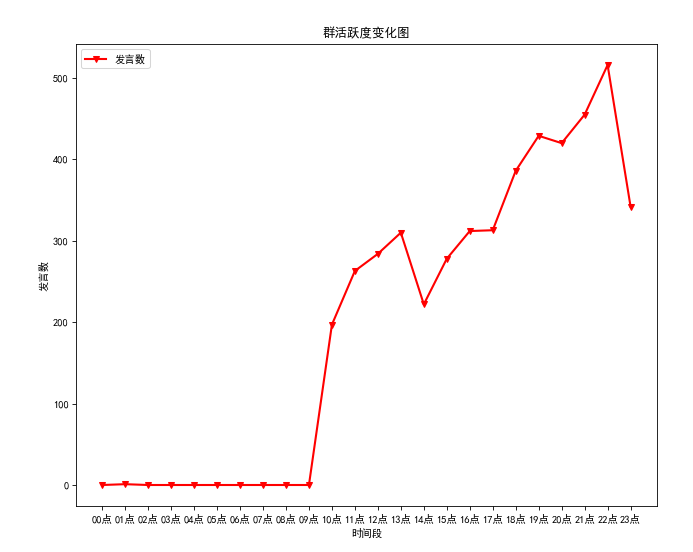
热度在一天的时间段内变化图,分析聊天记录中有关小时的数据存入excel文件中,再由excel文件使用plt绘画出相应图形
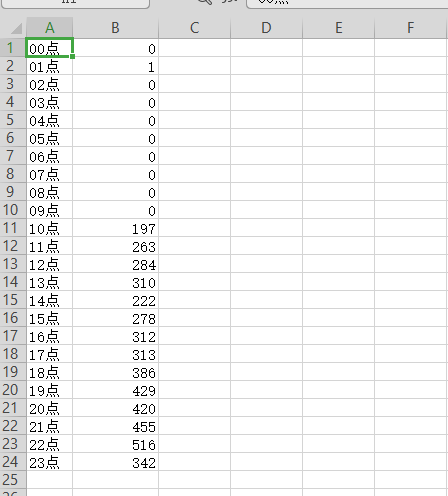
可以导入导出热度随时间断变化的excel文件,对excel文件进行分析
3.生成词云
- 导入python的jieba库进行中文分析,去除掉符号以及空白等无意义信息后将相应频率存入列表中,再根据python自带的wordcloud工具生成相应词云,但缺点是词语过滤的还不明显,还有图片以及“一个”这样无意义的词存在,后续可以继续改进。

- 导入python的jieba库进行中文分析,去除掉符号以及空白等无意义信息后将相应频率存入列表中,再根据python自带的wordcloud工具生成相应词云,但缺点是词语过滤的还不明显,还有图片以及“一个”这样无意义的词存在,后续可以继续改进。
通过对聊天记录的分析,可以看出该群一天中活跃度比较高的时间段是早晨九点多,晚上十一二点达到活跃度达到最高。从月份活跃度上也可以看出,在放假期间(二月与七八月)活跃度达到低点,开学后逐渐回升。从词云上也可以看到有四六级,考研,二手,电动车等与大学生密切相关的词语,由此也可以明显感受到互联网大数据与我们个人息息相关。
(七)特色功能
使用黑名单机制,活动更加随心所欲
自定义奖励数目、名称、奖品、人数,一切尽在掌握
使用活跃度计算抽奖资格。活跃度低于多少就丧失抽奖资格,并对于特殊身份以及恶意刷屏者都做了限制,例如有人以前正常发言,抽奖时恶意刷屏这样只会降低该活跃度而不是直接拉入黑名单。
监测刷屏的淘汰算法。
保留最近五次不重复发言的hashcode值为<键,值>数组a。初始Map a[5] = {-1,-1};新发言的值进行两次数组遍历。第一次遍历:监测hashcode是否重复,若重复将hashcode对应值+1,若否则进入第二次循环:监测是否有空位置,若有则插入,若无则将遍历到的最后一个位置((进入位置-1)mod 5)进行数据替换。使用静态变量保留每次最新访问的下标,且逢5归0。值满足条件时按算法一进行处理。
(八)遇到的困难及解决方法
刘忠燏
- 正则表达式编写
我在团队里的工作有一个内容就是负责解析聊天记录,然而就如一个笑话里说的:“我有一个问题,我决定用正则表达式解决,现在我有两个问题了”。但是聊天记录这种信息,是有很明显的格式的,于是没辙,只能在 MSDN 上翻 .NET 里有关正则表达式的文档,并照着这个示例去学习了大概一两个小时,勉强写出了匹配消息头部分的正则表达式,然而匹配抽奖关键词的正则表达式我还是没有头绪,最后在这篇博客中找到了答案。不过我还是不能理解为什么这样可以匹配,还望有人能解释一下
Regex KeywordRegex = new Regex(
@"#(?<code>[^\\#|.]+)#",
RegexOptions.Compiled,
TimeSpan.FromMilliseconds(200)
);
- 撰写注释
也不知道是什么原因,我在写注释的时候发现自己很容易词穷(我知道我写的这个方法做了什么,但我就是无法表示出来)。可能是我平时注释写得太少吧,目前只能是硬着头皮把注释写完,同时和交接代码的同学交待清楚我所写的一些功能。(有没有什么资料讲怎么写注释的团队作业第六次—团队Github实战训练的更多相关文章
- 团队作业第六次——团队Github实战训练
作业格式 课程名称:软件工程1916|W(福州大学) 作业要求:团队作业第六次-团队Github实战训练 团队名称:葫芦娃队 作业目标:确定和分析选题,绘制评审表 github地址:https://g ...
- 团队作业第六次—团队Github实战训练(追光的人)
所属课程 软件工程1916 作业要求 团队作业第六次-团队Github实战训练 团队名称 追光的人 作业目标 搭建一个相对公平公正的抽奖系统,根据QQ聊天记录,完成从统计参与抽奖人员颁布抽奖结果的基本 ...
- 团队作业第六次-团队Github实战训练
格式描述 课程名称:软件工程1916|W(福州大学) 作业要求:项目系统设计与数据库设计 团队名称:为了交项目干杯 GitHub地址:地址 作业目标:搭建一个相对公平公正的抽奖系统,根据QQ聊天记录, ...
- 团队Github实战训练
班级:软件工程1916|W 作业:团队Github实战训练 团队名称:SkyReach Github地址:Github地址 贡献比例表 队员学号 队员姓名 此次活动任务 贡献比例 221600106 ...
- bug终结者 团队作业第六、七周
bug终结者 团队作业第六.七周 作业要求:团队作业第六.七周 博客编辑:20162322 朱娅霖 一.修改<需求规格说明书> <需求规格说明书>2.0版(即初稿) <需 ...
- 团队作业八——第二次团队冲刺(Beta版本)第7天&项目汇总
项目汇总 第一天:http://www.cnblogs.com/newteam6/p/6879383.html 第二天:http://www.cnblogs.com/newteam6/p/688078 ...
- 团队作业八——第二次团队冲刺(Beta版本)第6天
团队作业八--第二次团队冲刺(Beta版本)第6天 一.每个人的工作 (1) 昨天已完成的工作 简单模式逻辑代码涉及与相关功能的具体实现 (2) 今天计划完成的工作 修改完善注册登录内容界面,编辑错题 ...
- 团队作业八——第二次团队冲刺(Beta版本)第5天
团队作业八--第二次团队冲刺(Beta版本)第5天 一.每个人的工作 (1) 昨天已完成的工作 完成界面跳转界面. (2) 今天计划完成的工作 简单模式逻辑代码涉及与相关功能的具体实现 (3) 工作中 ...
- 团队作业八——第二次团队冲刺(Beta版本)第4天
团队作业八--第二次团队冲刺(Beta版本)第4天 一.每个人的工作 (1) 昨天已完成的工作 做一下用户注册的功能和登录功能. (2) 今天计划完成的工作 完成界面跳转 (3) 工作中遇到的困难 界 ...
随机推荐
- 分布式协调服务Zookeeper集群监控JMX和ZkWeb应用对比
分布式协调服务Zookeeper集群监控JMX和ZkWeb应用对比 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. JMX是用来远程监控Java应用的框架,这个也可以用来监控其他的J ...
- [面试]future模式
Future模式 什么是future模式? 传统单线程环境下,调用函数是同步的,必须等待程序返回结果后,才可进行其他处理. Futrue模式下,调用方式改为异步. Futrue模式的核心在于:充分利用 ...
- shell 生成文件统计信息
#!/bin/bash #file name : filestat.sh if [ $# -ne 1 ]; then echo "Usage is $0 basepath"; ex ...
- Python——Python+Pydev出现SyntaxError: Non-UTF-8 code
搭建好Python+Pydev后发现每次输入中文,包括注释,会出现语法错误提示,如: SyntaxError: Non-UTF-8 code starting with... 可通过下面方法解决. 1 ...
- Codeforces Round #404 (Div. 2) D. Anton and School - 2
题目链接 转自 给你一个字符串问你能构造多少RSBS. #include<bits/stdc++.h> #define LL long long #define fi first #def ...
- laravel-mix的安装
Laravel-mix的安装 Laravel Mix 是一款前端任务自动化管理工具,使用了工作流的模式对制定好的任务依次执行.Mix 提供了简洁流畅的 API,让你能够为你的 Laravel 应用定义 ...
- java下载远程文件到本地
java下载远程文件到本地(转载:http://www.cnblogs.com/qqzy168/archive/2013/02/28/2936698.html) /** * 下载远程文 ...
- Nodejs一键实现微信内打开网页url自动跳转外部浏览器访问的功能
前言 现如今微信对第三方推广链接的审核是越来越严格了,域名在微信中分享转发经常会被拦截,一旦被拦截用户就只能复制链接手动打开浏览器粘贴才能访问,要不然就是换个域名再推,周而复始.无论是哪一种情况都会面 ...
- [经验交流] 影响 kubernetes 稳定性的因素
使用k8s已有近一年的时间,版本从1.2到1.5.1.6.1.7,期间出现并解决了不少问题,下面是我总结的影响k8s集群稳定性的因素: 1. 安装环境 *kubelet版本最好与kube-apiser ...
- 【译】索引进阶(十二):SQL SERVER中的索引碎片【中篇】
原文链接:传送门. 为了讨论碎片产生的原因,以及避免和移除索引碎片的技术,我们必须从本进阶系列后续将介绍的两个章节借用一些知识点:创建/更新索引的知识,以及向一个索引表插入数据行的相关知识. 当我们讲 ...
- 团队作业第六次——团队Github实战训练