hive的使用 + hive的常用语法
本博文的主要内容有:
.hive的常用语法
.内部表
.外部表
.内部表,被drop掉,会发生什么?
.外部表,被drop掉,会发生什么?
.内部表和外部表的,保存的路径在哪?
.用于创建一些临时表存储中间结果
.用于向临时表中追加中间结果数据
.分区表(分为,分区内部表和分区外部表)
.hive的结构和原理
.hive的原理和架构设计
hive的使用
对于hive的使用,在hadoop集群里,先启动hadoop集群,再启动mysql服务,然后,再hive即可。
1、在hadoop安装目录下,sbin/start-all.sh。
2、在任何路径下,执行service mysql start (CentOS版本)、sudo /etc/init.d/mysql start (Ubuntu版本)
3、在hive安装目录下的bin下,./hive
对于hive的使用,在spark集群里,先启动hadoop集群,再启动spark集群,再启动mysql服务,然后,再hive即可。
1、在hadoop安装目录下,sbin/start-all.sh。
2、在spark安装目录下,sbin/start-all.sh
3、在任何路径下,执行service mysql start (CentOS版本)、sudo /etc/init.d/mysql start (Ubuntu版本)
3、在hive安装目录下的bin下,./hive

[hadoop@weekend110 bin]$ pwd
/home/hadoop/app/hive-0.12.0/bin
[hadoop@weekend110 bin]$ mysql -uhive -hweekend110 -phive
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 110
Server version: 5.1.73 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hive |
| mysql |
| test |
+--------------------+
4 rows in set (0.00 sec)
mysql> quit;
Bye
[hadoop@weekend110 bin]$

[hadoop@weekend110 bin]$ pwd
/home/hadoop/app/hive-0.12.0/bin
[hadoop@weekend110 bin]$ ./hive
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/10/10 22:36:25 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
Logging initialized using configuration in jar:file:/home/hadoop/app/hive-0.12.0/lib/hive-common-0.12.0.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/app/hive-0.12.0/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive> SHOW DATABASES;
OK
default
hive
Time taken: 12.226 seconds, Fetched: 2 row(s)
hive> quit;
[hadoop@weekend110 bin]$

总结,mysql比hive,多出了自己本身mysql而已。
如
CREATE TABLE page_view(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User'
)
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
STORED AS SEQUENCEFILE; TEXTFILE

原因解释如下:


0000101 iphone6pluse 64G 6888
0000102 xiaominote 64G 2388
CREATE TABLE t_order(id int,name string,rongliang string,price double)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
;

现在,我们来开始玩玩

[hadoop@weekend110 bin]$ pwd
/home/hadoop/app/hive-0.12.0/bin
[hadoop@weekend110 bin]$ ./hive
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/10/10 10:16:38 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
Logging initialized using configuration in jar:file:/home/hadoop/app/hive-0.12.0/lib/hive-common-0.12.0.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/app/hive-0.12.0/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
遇到,如下问题

FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
参考,http://blog.163.com/songyalong1117@126/blog/static/1713918972014124481752/
hive常见问题解决干货大全
先Esc,再Shift,再 . + /


<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
改为
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>


很多人这样写
CREATE TABLE t_order(
id int,
name string,
rongliang string,
price double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
hive> CREATE TABLE t_order(id int,name string,rongliang string,price double)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> ;
OK
Time taken: 28.755 seconds
hive>

测试连接下,


正式连接



成功!
这里呢,我推荐一款新的软件,作为入门。
Navicat for MySQL的下载、安装和使用
之类呢,再可以玩更高级的,见
个人推荐,比较好的MySQL客户端工具
MySQL Workbench类型之MySQL客户端工具的下载、安装和使用
MySQL Server类型之MySQL客户端工具的下载、安装和使用



前提得要开启hive


注意:第一步里,输入后,不要点击“确定”。直接切换到“常规。”
关于,第二步。看下你的hive安装目录下的hive-site.xml,你的user和password。若你配置的是root,则第二步里用root用户。


配置完第二步,之后,再最后点击“确定。”
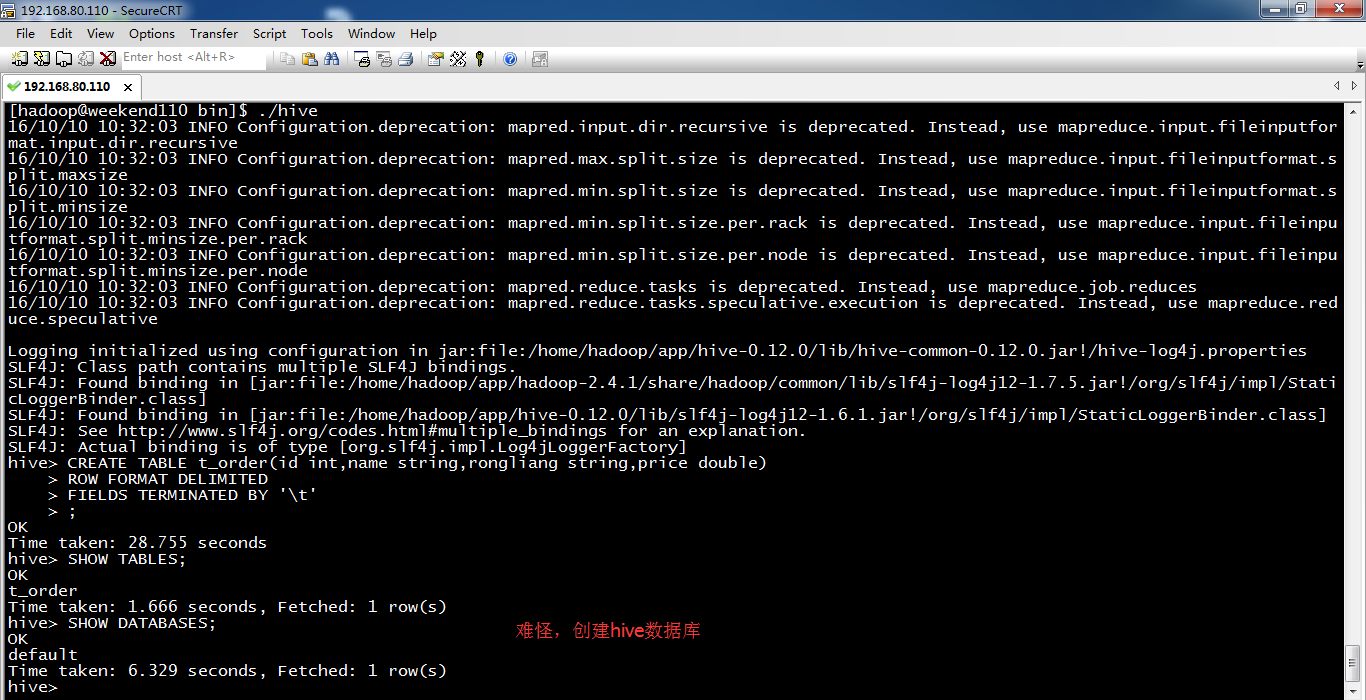
通过show databases;可以查看数据库。默认database只有default。

hive> CREATE DATABASE hive; //创建hive数据库,只是这个数据库的名称,命名为hive而已。
OK
Time taken: 1.856 seconds
hive> SHOW DATABASES;
OK
default
hive
Time taken: 0.16 seconds, Fetched: 2 row(s)
hive> use hive; //使用hive数据库
OK
Time taken: 0.276 seconds
很多人这样写法
CREATE TABLE t_order(
id int,
name string,
rongliang string,
price double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
hive> CREATE TABLE t_order(id int,name string,rongliang string,price double)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> ;
OK
Time taken: 0.713 seconds
hive> SHOW TABLES;
OK
t_order
Time taken: 0.099 seconds, Fetched: 1 row(s)
hive>
对应着,
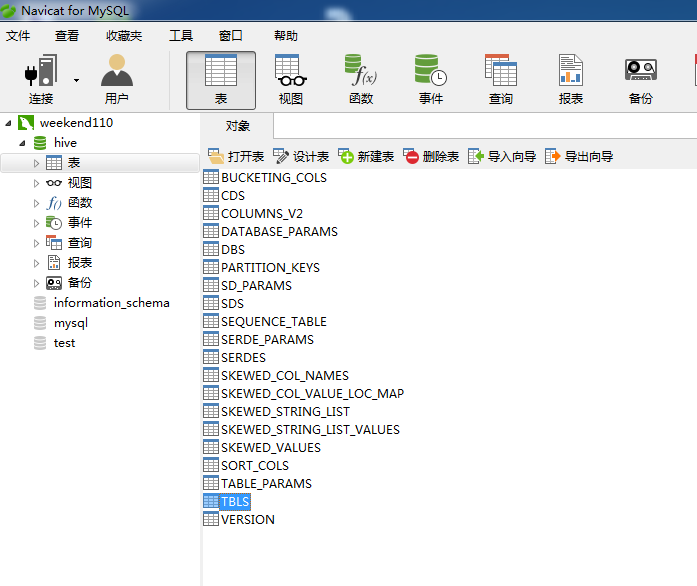
TBLS,其实就是TABLES,记录的是表名等。








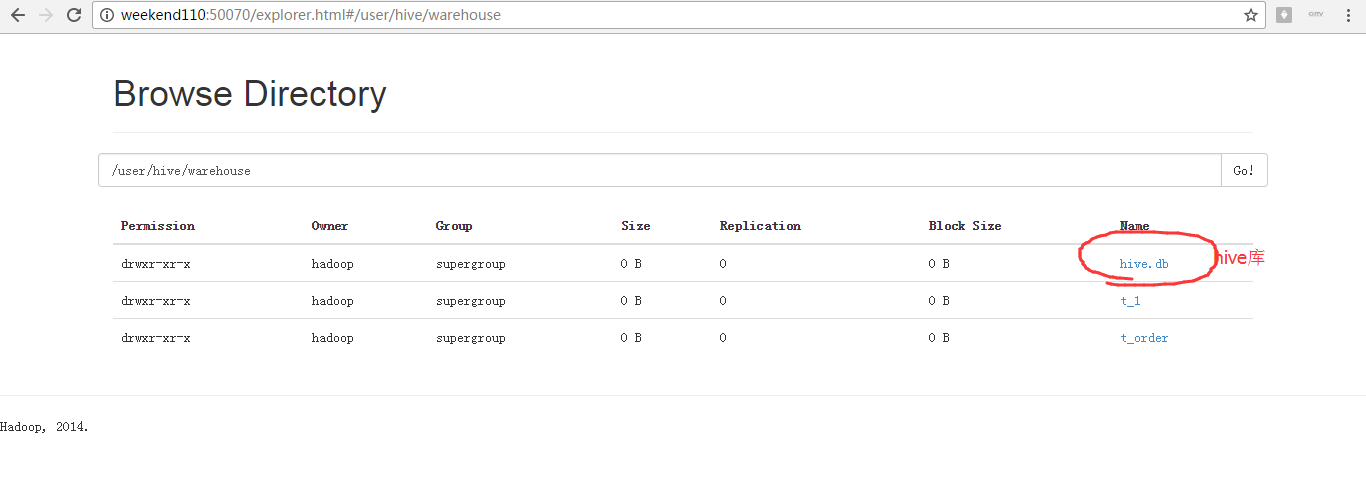


好的,现在,来导入数据。
新建

[hadoop@weekend110 ~]$ ls
app c.txt flowArea.jar jdk1.7.0_65 wc.jar
a.txt data flow.jar jdk-7u65-linux-i586.tar.gz words.log
blk_1073741856 download flowSort.jar Link to eclipse workspace
blk_1073741857 eclipse HTTP_20130313143750.dat qingshu.txt
b.txt eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz ii.jar report.evt
[hadoop@weekend110 ~]$ mkdir hiveTestData
[hadoop@weekend110 ~]$ cd hiveTestData/
[hadoop@weekend110 hiveTestData]$ ls
[hadoop@weekend110 hiveTestData]$ vim XXX.data

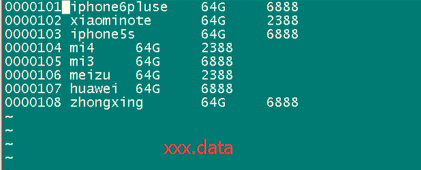
0000101 iphone6pluse 64G 6888
0000102 xiaominote 64G 2388
0000103 iphone5s 64G 6888
0000104 mi4 64G 2388
0000105 mi3 64G 6388
0000106 meizu 64G 2388
0000107 huawei 64G 6888
0000108 zhongxing 64G 6888

本地文件的路径是在,
[hadoop@weekend110 hiveTestData]$ pwd
/home/hadoop/hiveTestData
[hadoop@weekend110 hiveTestData]$ ls
XXX.data
[hadoop@weekend110 hiveTestData]$

[hadoop@weekend110 bin]$ ./hive
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
16/10/10 17:23:09 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
Logging initialized using configuration in jar:file:/home/hadoop/app/hive-0.12.0/lib/hive-common-0.12.0.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/app/hadoop-2.4.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/app/hive-0.12.0/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive> SHOW DATABASES;
OK
default
hive
Time taken: 15.031 seconds, Fetched: 2 row(s)
hive> use hive;
OK
Time taken: 0.109 seconds
hive> LOAD DATA LOCAL INPATH '/home/hadoop/hiveTestData/XXX.data' INTO TABLE t_order;
Copying data from file:/home/hadoop/hiveTestData/XXX.data
Copying file: file:/home/hadoop/hiveTestData/XXX.data
Failed with exception File /tmp/hive-hadoop/hive_2016-10-10_17-24-21_574_6921522331212372447-1/-ext-10000/XXX.data could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget(BlockManager.java:1441)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2702)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:584)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:440)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1556)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007)
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.CopyTask
hive>
http://blog.itpub.net/29050044/viewspace-2098563/

http://blog.sina.com.cn/s/blog_75353ff40102v0d3.html
http://jingyan.baidu.com/article/7082dc1c65a76be40a89bd09.html (最后在这里,找到了)
错误是:
Failed with exception File /tmp/hive-hadoop/hive_2016-10-10_17-54-30_887_2531771020597467111-1/-ext-10000/XXX.data could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and no node(s) are excluded in this operation.
解决方法:
出现此类报错主要原因是datanode存在问题,要么硬盘容量不够,要么datanode服务器down了。检查datanode,重启Hadoop即可解决。
我的这里,有错误,还没解决!
这里,t_order_wk,对应,我的t_order而已。只是表名不一样


哇,多么的明了啊!

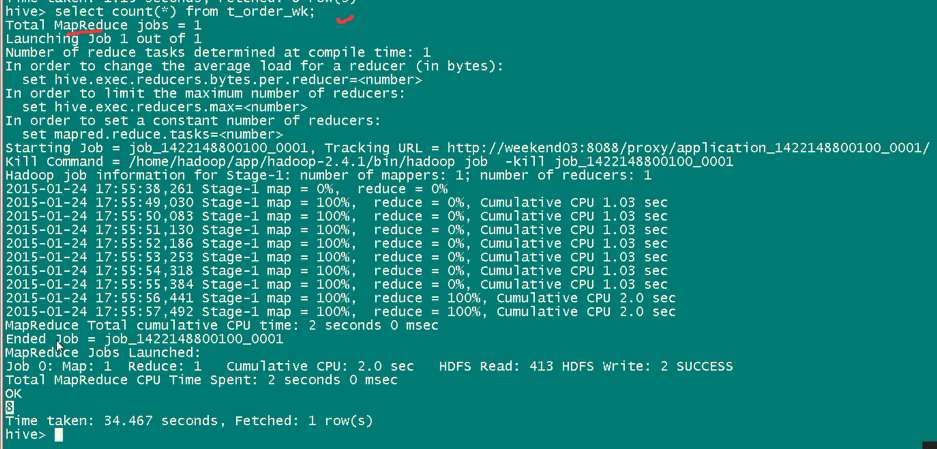
这一句命令,比起MapReduce语句来,多么的牛! 其实,hive本来就是用mapreduce写的,只是作为数据仓库,为了方便。
hive的常用语法
已经看到了hive的使用,很方便,把SQL语句,翻译成mapreduce语句。



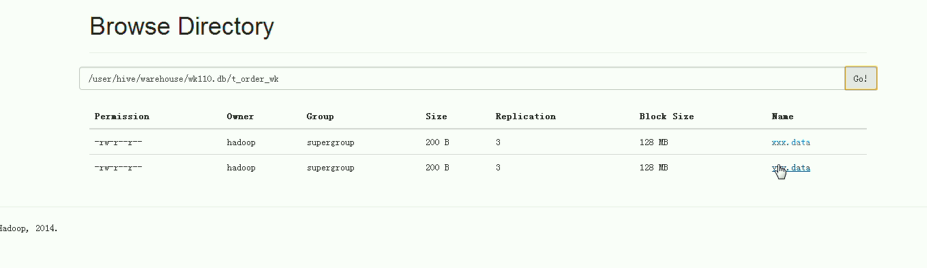

由此可见,xxx.data是向hive中表,加载进文件,也即,这文件是用LOAD进入。(从linux本地 -> hive中数据库)
yyy.data是向hive中表,加载进文件,也即,这文件是用hadoop fs –put进入。(从hdfs里 -> hive中数据库)
无论,是哪种途径,只要文件放进了/user/hive/warehouse/t_order_wk里,则,都可以读取到。











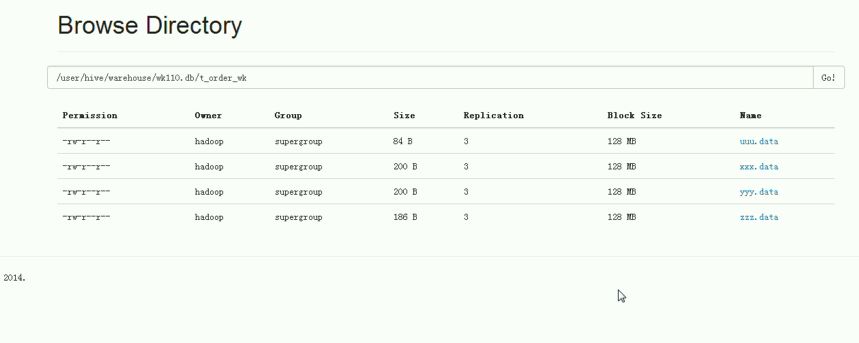
则,LOAD DATA LOCAL INPATH ,这文件是在,本地,即Linux里。从本地里导入
LOAD DATA INPATH,这文件是在,hdfs里。从hdfs里导入
那么,由此可见,若这DATA,即这文件,是在hdfs里,如uuu.data,则如“剪切”。
会有一个问题。如是业务系统产生的,我们业务或经常要读,路径是写好的,把文件移动了,
会干扰业务系统的进行。为此,解决这个问题,则,表为EXTERNAL。这是它的好处。
//external
CREATE EXTERNAL TABLE tab_ip_ext(id int, name string,
ip STRING,
country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/external/hive';



为此,我们现在,去建立一个ETTERNAL表,与它jjj.data,关联起来。Soga,终于懂了。



内部表,被drop掉,会发生什么?


以及,内部表t_order_wk里的那些文件(xxx.data、yyy.data、zzz.data、jjj.data)都被drop掉了。

外部表,被drop掉,会发生什么?

是自定义的,hive_ext,在/下


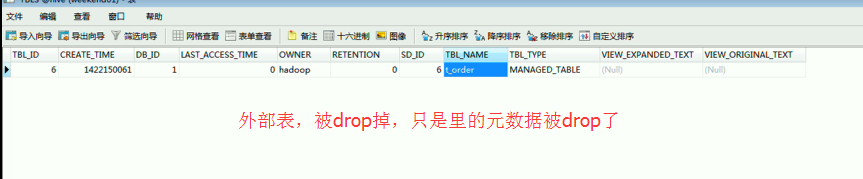
内部表和外部表的,保存的路径在哪?

用于创建一些临时表存储中间结果
CTAS,即CREATE AS的意思
// CTAS 用于创建一些临时表存储中间结果
CREATE TABLE tab_ip_ctas
AS
SELECT id new_id, name new_name, ip new_ip,country new_country
FROM tab_ip_ext
SORT BY new_id;




用于向临时表中追加中间结果数据
//insert from select 用于向临时表中追加中间结果数据
create table tab_ip_like like tab_ip;
insert overwrite table tab_ip_like
select * from tab_ip;
这里,没演示
分区表
//PARTITION
create table tab_ip_part(
id int,
name string,
ip string,
country string
)
partitioned by (part_flag string)
row format delimited fields terminated by ',';
LOAD DATA LOCAL INPATH '/home/hadoop/ip.txt' OVERWRITE INTO TABLE tab_ip_part PARTITION(part_flag='part1');
LOAD DATA LOCAL INPATH '/home/hadoop/ip_part2.txt' OVERWRITE INTO TABLE tab_ip_part PARTITION(part_flag='part2');
select * from tab_ip_part;
select * from tab_ip_part where part_flag='part2';
select count(*) from tab_ip_part where part_flag='part2';
alter table tab_ip change id id_alter string;
ALTER TABLE tab_cts ADD PARTITION (partCol = 'dt') location '/external/hive/dt';
show partitions tab_ip_part;
每个月生成的订单记录,对订单进行统计,哪些商品的最热门,哪些商品的销售最大,哪些商品点击率最大,哪些商品的关联最高。
如果,对订单整个分析很大,为提高效率,在建立表时,就分区。
则,多了一个选择,你也可以对全部来,也可以对某个分区来。则按分区来。













//PARTITION
create table tab_ip_part(id int,name string,ip string,country string)
partitioned by (part_flag string)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/ip.txt' overwrite into table tab_ip_part
partition(part_flag='part1');
load data local inpath '/home/hadoop/ip_part2.txt' overwrite into table tab_ip_part
partition(part_flag='part2');
select * from tab_ip_part;
select * from tab_ip_part where part_flag='part2';
select count(*) from tab_ip_part where part_flag='part2';
alter table tab_ip change id id_alter string;
ALTER TABLE tab_cts ADD PARTITION (partCol = 'dt') location '/external/hive/dt';
show partitions tab_ip_part;
这里,不多演示赘述了。
hive的结构和原理

hive的原理和架构设计

hive的使用 + hive的常用语法的更多相关文章
- 2 hive的使用 + hive的常用语法
本博文的主要内容有: .hive的常用语法 .内部表 .外部表 .内部表,被drop掉,会发生什么? .外部表,被drop掉,会发生什么? .内部表和外部表的,保存的路径在哪? .用于创建一些临时表存 ...
- 一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual Hive的数据存储 1.Hiv ...
- hive集成sentry的sql使用语法
Sentry权限控制通过Beeline(Hiveserver2 SQL 命令行接口)输入Grant 和 Revoke语句来配置.语法跟现在的一些主流的关系数据库很相似.需要注意的是:当sentry服务 ...
- HBASE与hive对比使用以及HBASE常用shell操作。与sqoop的集成
2.6.与 Hive 的集成2.6.1.HBase 与 Hive 的对比1) Hive(1) 数据仓库Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以方 ...
- Hive 12、Hive优化
要点:优化时,把hive sql当做map reduce程序来读,会有意想不到的惊喜. 理解hadoop的核心能力,是hive优化的根本. 长期观察hadoop处理数据的过程,有几个显著的特征: 1. ...
- Hive 实战(1)--hive数据导入/导出基础
前沿: Hive也采用类SQL的语法, 但其作为数据仓库, 与面向OLTP的传统关系型数据库(Mysql/Oracle)有着天然的差别. 它用于离线的数据计算分析, 而不追求高并发/低延时的应用场景. ...
- Hive 7、Hive 的内表、外表、分区(22)
Hive 7.Hive 的内表.外表.分区 1.Hive的内表 Hive 的内表,就是正常创建的表,在 http://www.cnblogs.com/raphael5200/p/5208437.h ...
- Hive 5、Hive 的数据类型 和 DDL Data Definition Language)
官方帮助文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL Hive的数据类型 -- 扩展数据类型data_t ...
- 别只用hive写sql -- hive的更多技能
hive是Apache的一个顶级项目,由facebook团队开发,基于java开发出面向分析师或BI等人员的数据工具(常用作出具仓库),它将文件系统映射为表,使用SQL实现mapreduce任务完成分 ...
随机推荐
- 【HDU 5384】Danganronpa(AC自己主动机)
看官方题解貌似就是个自己主动机裸题 比赛的时候用kuangbin的AC自己主动机模板瞎搞的,居然A了,并且跑的还不慢.. 存下模板吧 #include<cstdio> #include&l ...
- java的gradle项目的基本配置
plugins { id 'org.springframework.boot' version '2.1.4.RELEASE' id 'java' } apply plugin: 'io.spring ...
- ERROR 1366 (HY000): Incorrect string value: '\xD6\xD0\xCE\xC4' for column XXX at row 1
本错误为:该列的插入格式有误 修改该表中该列的字符集为utf-8 网上办法: )不能插入中文解决办法: 向表中插入中文然后有错误. mysql> insert into users values ...
- hihoCoder 1584 Bounce 【数学规律】 (ACM-ICPC国际大学生程序设计竞赛北京赛区(2017)网络赛)
#1584 : Bounce 时间限制:1000ms 单点时限:1000ms 内存限制:256MB 描述 For Argo, it is very interesting watching a cir ...
- swing _JFileChooser文件选择窗口
import javax.swing.JFileChooser; import org.eclipse.swt.internal.win32.TCHITTESTINFO; public class t ...
- 解决Javascript md5 和 Java md5 中文加密后不同问题
Javascript md5 和 Java md5 带中文字符加密结果不一致,可以通过编码进行转化. javascript可以使用encodeURLComponent将中文先转化一次再进行MD5加密. ...
- redis02---对于key的操作命令
Redis对于key的操作命令 del key1 key2 ... Keyn 作用: 删除1个或多个键 返回值: 不存在的key忽略掉,返回真正删除的key的数量 rename key newkey ...
- HDU1964 Pipes —— 插头DP
题目链接:https://vjudge.net/problem/HDU-1964 Pipes Time Limit: 5000/1000 MS (Java/Others) Memory Limi ...
- HDU3567 Eight II —— IDA*算法
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3567 Eight II Time Limit: 4000/2000 MS (Java/Others) ...
- YTU 2427: C语言习题 整数排序
2427: C语言习题 整数排序 时间限制: 1 Sec 内存限制: 128 MB 提交: 391 解决: 282 题目描述 用指向指针的指针的方法对n个整数排序并输出.要求将排序单独写成一个函数 ...