hadoop2 Ubuntu 下安装部署
搭建Hadoop环境( 我以hadoop 2.7.3 为例, 系统为 64bit Ubuntu14.04 ) hadoop 2.7.3 官网下载 , 选择自己要安装的版本。注意每个版本对应两个下载选项source和binary,我们暂时下载binary,我们下载编译好的文件hadoop-2.7.3.tar.gz , 解压后为 hadoop-2.7.3 , 这个可以直接安装部署. ( 如果下载源代码文件 hadoop-2.7.3-src.tar.gz , 需要先编译后才能进行安装部署. )
Hadoop有三种安装部署模式,分别是:第一,单机安装部署;第二,伪分布式安装部署;第三,全分布式安装部署. 我们还是以hadoop-2.7.3为例
第一以及第二在单个节点上部署集群,参见官网 Hadoop:设置单个节点集群。 参考 Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
第三是要在多个节点上进行部署集群,参见官网 Hadoop集群安装
安装hadoop前的准备工作
(1) 安装jdk 参见我的博客 安装JDK+Eclipse+Maven(windows系统和linux系统)
(2) 安装openssl-server
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server: ( 或者直接 sudo apt-get install openssh )
$ sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
$ ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 ,这样就登陆到本机了。
(3) 免密码登陆
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
单台机器的无密码登录( 登录 localhost ): ( 单机安装部署以及伪分布式安装部署 )
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
$ exit # 退出刚才的 ssh localhost
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了
还有多台机器间的无密码登录: ( 全分布式安装部署 )
安装Hadoop2
接下来我们安装hadoop到/usr/local/目录下, ( 也可以是其他目录 )
$ cd /usr/local
$ sudo cp ~/Desktop/hadoop-x.x.x.tar.gz . //别忽视最后的点,代表当前目录
$ sudo tar -zxvf hadoop-x.x.x.tar.gz
$ sudo mv hadoop-x.x.x hadoop //简化名字而已,改不改都行
$ sudo chown -R hadoop ./hadoop // 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
$ cd /usr/local/hadoop
$ ./bin/hadoop version
配置全局变量:
$ sudo vim /etc/profile // 设置全局变量, 不配置的话只能命令所在的文件夹下运行
添加如下代码:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$HADOOP_HOME/bin:$PATH
如果出现链接错误请关闭防火墙:
service iptables save
service iptables stop
chkconfig iptables off
1 单机安装部署
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。( 可以运行 bin 下的命令, 但不能用 sbin 下的start-all.sh ) , 比如可以用 bin/hadoop version 查看hadoop版本号.
也可以按如下配置Hadoop.
配置Hadoop
更改/usr/local/hadoop/etc/hadoop下的 hadoop-env.sh 文件。(我的jdk也是安装在/usr/lib/jvm下的), 还可以修改 mapred-env.sh 以及 yarn-env.sh 文件
#The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/java
core-site.xml文件配置
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml文件配置
<--更改hadoop默认的副本个数,由于我们是单节点所以改为只有一个副本就好-->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml文件配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml文件配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2 伪分布式安装部署
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
配置Hadoop
更改/usr/local/hadoop/etc/hadoop下的 hadoop-env.sh 文件。(我的jdk也是安装在/usr/lib/jvm下的), 还可以修改 mapred-env.sh 以及 yarn-env.sh 文件
#The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/java
core-site.xml文件配置 ( 为hdfs的工作目录(可以不设)默认为hadoop的tmp目录下(重启后数据就会消失下次还得重新格式化) )
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml文件配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
mapred-site.xml文件配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml文件配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化:( 只能进行一次格式化, 否则会出错 )
$ ./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。
接着开启所有的守护进程。
$ ./sbin/start-all.sh
若出现如下SSH提示,输入yes即可。
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable。该 WARN 提示可以忽略,并不会影响正常使用(该 WARN 可以通过编译 Hadoop 源码解决)。
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode” , "ResourceManager" 和 "NodeManager"(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-all.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
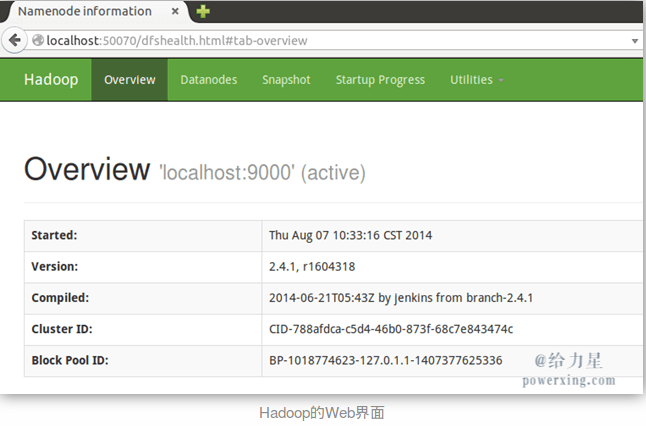
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。 ( 类似下图的效果 )
3 全分布式安装部署
包括单台机器的虚拟机部署以及多个节点(即多台机器)的部署
3.1 单台机器的虚拟机安装部署
hadoop学习通过虚拟机安装hadoop完全分布式集群 , 虚拟机安装 Hadoop , VM虚拟机CentOS下hadoop集群安装过程 , 全分布式的Hadoop虚拟机安装 ,
3.2 多个节点(即多台机器)的安装部署
这个和虚拟机安装部署类似,只不过是虚拟机是一台机器虚拟出多台机器, 而多台机器的安装是实实在在的有多个机器.
3.1 和 3.2 如下所式: ( 3.1 比3.2 多出 安装Vmware WorkStation软件 以及 在虚拟机上安装linux操作系统 )
准备4个(虚拟)机器节点
配置好jdk以及ssh免密码登录之后. 一般HDFS的文件块默认是3个备份, 所有至少有3个节点. 而且用户名最好保持一致, 我的用户名设置为 hadoop ,我这里有4台机器,所以,在准备好这4个结点之后,需要分别将linux系统的主机名重命名,重命名主机名的方法:
$ vim /etc/hostname
通过修改hostname文件即可,这4个点结均要修改,以示区分:
以下是我对4个结点的ubuntu系统主机分别命名为:master, node1, node2, node3
安装过程主要有以下几个步骤:
(1) 配置hosts文件
(2) 建立hadoop运行帐号
(3) 配置ssh免密码连入
(4) 下载并解压hadoop安装包
(5) 配置namenode,修改site文件
(6) 配置hadoop-env.sh文件
(7) 配置masters和slaves文件
(8) 向各节点复制hadoop
(9) 格式化namenode
(10) 启动hadoop
(11) 用jps检验各后台进程是否成功启动
(12) 通过网站查看集群情况
下面我们对以上过程,各个击破吧!~~
(1) 配置hosts文件 ( /etc/hosts )
先简单说明下配置hosts文件的作用,它主要用于确定每个结点的IP地址,方便后续master结点能快速查到并访问各个结点。在上述4个(虚拟机)结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少,可以通过ifconfig命令进行查看,( 假设所有主机都在192.168.1.X 网段内 )如实验中,master结点的IP地址为:192.168.1.100, node1结点的IP地址为:192.168.1.101, node2结点的IP地址为:192.168.1.102, node3结点的IP地址为:192.168.1.103.
如果IP地址不对,可以通过ifconfig命令更改结点的物理IP地址,示例如下:
hadoop@master:~$ sudo ifconfig eth0 192.168.1.100
通过上面命令可以将IP改为192.168.1.100。如果觉得这样做麻烦,可以固定IP. 将每个结点的IP地址设置完成后,就可以配置hosts文件了,hosts文件路径为 /etc/hosts,我的hosts文件配置如下,大家可以参考自己的IP地址以及相应的主机名完成配置, 每台机器都一样,这里以master主机为例:
127.0.0.1 localhost
#127.0.0.1 master 192.168.1.100 master
192.168.1.101 node1
192.168.1.102 node2
192.168.1.103 node3
(2) 建立hadoop运行帐号
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
$ sudo groupadd hadoop //设置hadoop用户组
$ sudo useradd –s /bin/bash –d /home/hadoop –m hadoop –g hadoop –G admin //添加一个hadoop用户,此用户属于hadoop用户组,且具有admin权限。
$ sudo passwd hadoop //设置用户hadoop登录密码
$ su hadoop //切换到hadoop用户中
上述4个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。
(3) 配置ssh免密码连入
这一环节最为重要,而且也最为关键,因为本人在这一步骤裁了不少跟头,走了不少弯路,如果这一步走成功了,后面环节进行的也会比较顺利。 SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,想要破解还是非常有难度的。Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证, hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
OK,废话就不说了,下面看看如何配置SSH免密码登录吧!~~
参见 ssh 免密码登录 , ssh 免密码登录1 , ssh 免密码登录2 ,其中在第一个链接 ssh 免密码登录 中, 缺少 修改SSH配置文件 su root -->登陆root用户修改配置文件 vim /etc/ssh/sshd_config -->去掉下图中三行的注释

下面是我的配置:
(1) 生成公钥和私钥
在每台机器上
$ ssh-keygen // 等同于ssh-keygen -t rsa
运行上面的命令后,系统会出现一系列提示,可以一路回车,例如:
$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/glowd/.ssh/id_rsa): Enter
// 特别说明,要不要对私钥设置口令(passphrase),如果担心私钥的安全,可以设置一个。没有特殊需求直接Enter,为空
运行结束以后, 默认在 ~/.ssh目录生成两个文件:
id_rsa :私钥
id_rsa.pub :公钥
(2) 导入公钥到认证文件,更改权限
导入本机
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
导入本机后就可以无密码登录localhost
$ ssh localhost
导入要免密码登录的服务器, 我们以 master (192.168.1.100 ) 和 node1(192.168.1.101 ) 为例, 这之前已经设置/etc/hosts ,让主机名和IP对应, 这样主机名既是IP, 否则下面的主机名要用IP 代替.
要想 node1 免密码登录 master, 首先将 node1 的公钥复制到远端服务器 master,用户为hadoop . 把node1机下的id_rsa.pub复制到master机下,在master机的.ssh/authorized_keys文件里,我用scp复制。
$ scp ~/.ssh/id_rsa.pub hadoop@master:~
由于还没有免密码登录的,所以要输入密码。
在服务器上master上, master 机把从 node1 机复制的id_rsa.pub添加到.ssh/authorzied_keys文件里。
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
$ rm ~/id_rsa.pub -->保险起见,删除传过来的公钥
在服务器master上更改权限(必须), authorized_keys的权限要是600。
$ chmod 755 ~
$ chmod 700 ~/.ssh
$ chmod 600 ~/.ssh/authorized_keys
以上执行之后,有些机器应该可以直接访问了,可以测试一下. node1 机登录 master 机。 ( 用户名相同的话, 可以直接用IP, 否则要用 ssh hadoop@master )
ssh 192.168.1.100 #ssh master
第一次登录是时要你输入yes。
现在 node1 机可以无密码登录 master 机了。
同理, 要想 master 也免密码登录 node1 , 只需要执行相同的操作,
要想 master 免密码登录 node1, 首先将 master 的公钥复制到远端服务器 node1,用户为hadoop . 把master机下的id_rsa.pub复制到node1 机下,在node1机的.ssh/authorized_keys文件里,我用scp复制。
$ scp ~/.ssh/id_rsa.pub hadoop@node1:~
由于还没有免密码登录的,所以要输入密码。
在服务器上node1上, node1 机把从 master 机复制的id_rsa.pub添加到.ssh/authorzied_keys文件里。
$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
$ rm ~/id_rsa.pub -->保险起见,删除传过来的公钥
在服务器node1上更改权限(必须), authorized_keys的权限要是600。
$ chmod 755 ~
$ chmod 700 ~/.ssh
$ chmod 600 ~/.ssh/authorized_keys
以上执行之后,有些机器应该可以直接访问了,可以测试一下. master 机登录 node1 机。 ( 用户名相同的话, 可以直接用IP, 否则要用 ssh hadoop@node1 )
ssh 192.168.1.101 # ssh node1
第一次登录是时要你输入yes。
现在 master 机可以无密码登录 node1 机了。
这样, 这两台机器就可以相互免密码登录了.
(3) 常见问题及解决方案
生成密钥并上传至远程主机后,任然不可用.
这时打开服务器的 /etc/ssh/sshd_config 这个文件,取消注释。

重启服务器的ssh服务。
#RHEL/CentOS系统
$ service sshd restart
#ubuntu系统
$ service ssh restart
#debian系统
$ /etc/init.d/ssh restart
执行ssh-copy-id 命令
$ ssh-copy-id glowd@{remote ip}
#`如果不是默认端口22,是9001`
$ ssh-copy-id -p 9001 glowd@{remote ip}
.....
还有就是你的host key has just been changed,即主机码变了,比如node1的变了,那么node2链接node1就会出问题,这时候就需要把node2中的node1的码删除再重新添加。删除方法如下:
ssh-keygen -f "/home/hadoop/.ssh/known_hosts" -R node1
(4) 前面搞定了免密码登录,想想也是很激动了。但是,还要写ip,还要写用户名,是不是又有点不爽啦。搞定用户名和端口号
找到 ~/.ssh/config 文件,如果木有的话就自个儿建一个吧,内容如下:
Host {remote ip}
User {username}
Port {port}
现在连接就很简单了
$ ssh {remote ip}
(4) 下载并解压hadoop安装包
前面已经下好了
(5) 配置 namenode,修改site文件
先完成JDK配置, 在设置JDK 以及 Hadoop 的全局环境变量. 到目前为止,准备工作已经完成,下面开始修改hadoop的配置文件了,即各种site文件,文件存放在/hadoop/etc/hadoop下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml 以及 yarn-site.xml 这四个文件。
core-site.xml文件配置
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hdfs-site.xml文件配置
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>Master:50070</value>
</property>
</configuration>
mapred-site.xml文件配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
yarn-site.xml文件配置
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
</configuration>
(6) 配置hadoop-env.sh文件
更改/usr/local/hadoop/etc/hadoop下的 hadoop-env.sh 文件。(我的jdk也是安装在/usr/lib/jvm下的), 还可以修改 mapred-env.sh 以及 yarn-env.sh 文件
#The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/lib/jvm/java
(7) 配置slaves文件 (在 /usr/local/hadoop/etc/hadoop 下)
slaves文件里默认有localhost , 修改成如下:
# localhost
master #可有可无, 有的话 master 既是主节点也作从节点,存储HDFS数据块. 没有的话,master只是主节点, 不进行数据块存储.
node1
node2
node3
(8) 向各节点复制hadoop ( 假设以上的hadoop 配置文件都是在 master 上配置)
这时向 node1, node2 以及 node3 节点复制hadoop: ( 以 node1 为例 )
$ sudo scp -r /usr/local/hadoop node1:~
然后进入 node1 , 把 hadoop 移动到 相应的位置, 在退出
$ ssh node1
$ sudo mv hadoop /usr/local/hadoop
$ exit
然后 node2 以及 node3 同样.
这样,结点 node1 和结点 node2 以及 node3 也安装了配置好的hadoop软件了。
(9) 格式化namenode
一定要在主节点 master 上进行格式化, 而且只能进行一次, 否则会出错. 我们已经配置hadoop为全局变量.
$ hadoop namenode -format #如果没有设置全局变量,在 /usr/local/hadoop 目录下输入 ./bin/hadoop namenode -format
注意:成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,则说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。
(10) 启动hadoop
这一步也在主结点master上进行操作:
$ start-all.sh #如果没有设置全局变量,在 /usr/local/hadoop 目录下输入 ./sbin/start-all.sh
(11) 用jps检验各后台进程是否成功启动
在主结点master上查看namenode,resourcemanager,secondarynamenode进程是否启动。
$ jps
如果出现以上进程则表示正确。
在 node1 和 node2 以及 node3 结点了查看nodemanager和datanode进程是否启动。 ( 以node1 为例 )
$ jps
如果出现以上进程则表示正确。 node2 和 node3 也是 .
进程都启动成功了。恭喜~~~
(12) 通过网站查看集群情况
在浏览器中输入:http://192.168.1.100:50030,网址为master结点所对应的IP: ( http://master:50030 ,这两个等同)
在浏览器中输入:http://192.168.1.100:50070,网址为master结点所对应的IP:
在浏览器中输入:http://192.168.1.100:8088,网址为master结点所对应的IP:
至此,hadoop的完全分布式集群安装已经全部完成,
hadoop2 Ubuntu 下安装部署的更多相关文章
- Ubuntu下安装部署MongoDB以及设置允许远程连接
最近因为项目原因需要在阿里云服务器上部署MongoDB,操作系统为Ubuntu,网上查阅了一些资料,特此记录一下步骤. 1.运行apt-get install mongodb命令安装MongoDB服务 ...
- ubuntu下vnc部署安装
ubuntu下vnc部署安装,参考如下博客:https://www.cnblogs.com/xuliangxing/p/7642650.html https://jingyan.baidu.com/a ...
- zhuan:ubuntu下安装Apache2+php+Mysql
from: http://www.cnblogs.com/lynch_world/archive/2012/01/06/2314717.html ubuntu下安装Apache+PHP+Mysql 转 ...
- Ubuntu下安装open-falcon-v0.2.1
在Ubuntu下安装open-falcon和Centos下安装的方法有点区别,因为Ubuntu使用的包管理器是apt-get,而Centos下使用的是Yum,建议不要再Ubuntu下使用yum 建议自 ...
- 在Ubuntu下安装ovs-dpdk
在Ubuntu下安装ovs-dpdk 参考资料:https://software.intel.com/zh-cn/articles/using-open-vswitch-with-dpdk-on-ub ...
- Ubuntu 下安装QT
Ubuntu 下安装QT 本文使用的环境 QT Library: qt-everywhere-opensource-src-4.7.4.tar.gz QT Creator: qt-creator-li ...
- Ubuntu下安装JDK以及相关配置
1.查看系统位数,输入以下命令即可 getconf LONG_BIT 2.下载对应的JDK文件,我这里下载的是jdk-8u60-linux-64.tar.gz 3.创建目录作为JDK的安装目录,这里选 ...
- Ubuntu下安装mod_python报错(GIT错误)
Ubuntu下安装mod_python3.4.1版本报出如下错误: writing byte-compilation script '/tmp/tmpE91VXZ.py' /usr/bin/pytho ...
- TODO:Ubuntu下安装Node
TODO:Ubuntu下安装Node Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境.Node.js 使用了一个事件驱动.非阻塞式 I/O 的模型,使其轻量又高 ...
随机推荐
- SUPEROBJECT序列数据集为JSON
// SUPEROBJECT 序列数据集 cxg 2017-1-12// {"data":[{"c1":1,"c2":1}]};// DEL ...
- ffmpeg实时编码解码部分代码
程序分为编码端和解码端,两端通过tcp socket通信,编码端一边编码一边将编码后的数据发送给解码端.解码端一边接收数据一边将解码得到的帧显示出来. 代码中的编码端编码的是实时屏幕截图. 代码调用 ...
- 【Todo】一些scala的实验 & 与Java的混合
另外,如果要支持 java 和 scala混合build,可以看看这篇文章: http://www.cnblogs.com/yjmyzz/p/4694219.html Scala和Java实现Word ...
- 五步掌握Git的基本开发使用命令
第一步:设置全局变量: git config --global user.name "gang.li" git config --global user.email "l ...
- 使用FMDB多线程訪问数据库,及database is locked的问题
今天最终攻克了多线程同一时候訪问数据库时,报数据库锁定的问题.错误信息是: Unknown error finalizing or resetting statement (5: database i ...
- vue2.0 常用的 UI 库
1.mint-ui 安装: npm install mint-ui --save 使用: main.js // MintUI组件库 import MintUI from 'mint-ui' impor ...
- Android studio 升级,不用下载完整版,完美更新到2.0
Android studio 2.0 公布已有一旦时间,据说,速度大大提高了.但是一直没有尝试更新,看到大家相继更新,所以迫不及待就准备更新,但是.更新之路确实异常坎坷.询问度娘,千奇百怪的问题接憧而 ...
- C#模拟登录Twitter 发送私信、艾特用户、回复评论
这次做成了MVC程序的接口 private static string UserName = "用户名"; private static string PassWord = &qu ...
- php闭包实例
php闭包函数,一个典型的实例 function getMoney() { $rmb = 1; $dollar = 6; $func = function($dollar) use (&$rm ...
- VirtualBox中使用双网卡实现CentOS既能上网(校园网)也能使用SSHclient
近期在虚拟机中使用linux操作系统,之前使用NAT方式上网,能够畅通无阻.可是使用SSHclient连接linux虚拟机就必须为其指定固定的IP地址.依照网上的配置方法使用桥接方式,这种方式是能够的 ...