大数据学习——hdfs集群启动
第一种方式:
1 格式化namecode(是对namecode进行格式化)
hdfs namenode -format(或者是hadoop namenode -format)
进入 cd /root/apps/hadoop/tmp/dfs/name/current
启动namecode hadoop-daemon.sh start namenode

启动datanode hadoop-daemon.sh start datanode
其他两台机器也执行下 hadoop-daemon.sh start datanode
mini1启动sn:
hadoop-daemon.sh start secondarynamenode
第二种方式:
先启动hdfs
sbin/start-dfs.sh
再启动yarn
sbin/start-yarn.sh
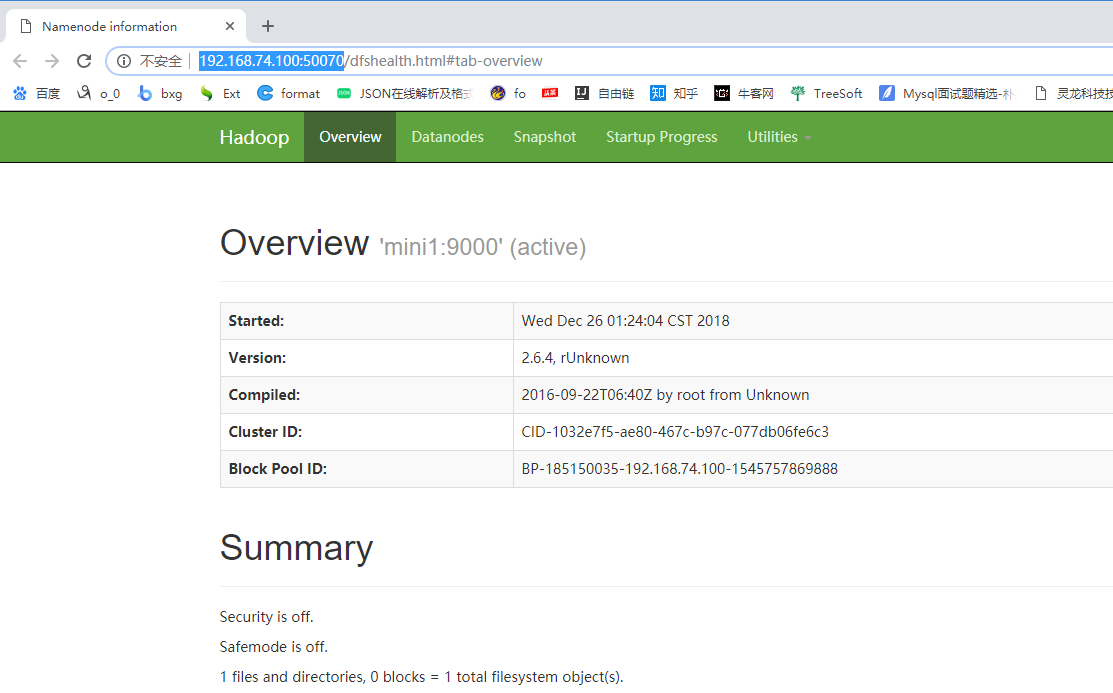
验证是否启动成功
1 jps查看进程
2 http://192.168.74.100:50070 查看
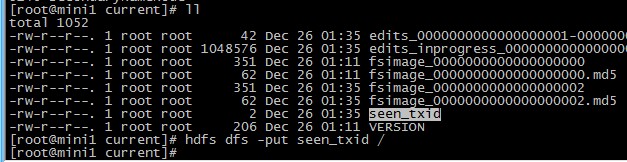
3 上传一个文件测试一下
hdfs dfs -put seen_txid /
打开 http://192.168.74.100:50070 utilities——Brows the file system 可以查看到上传的文件
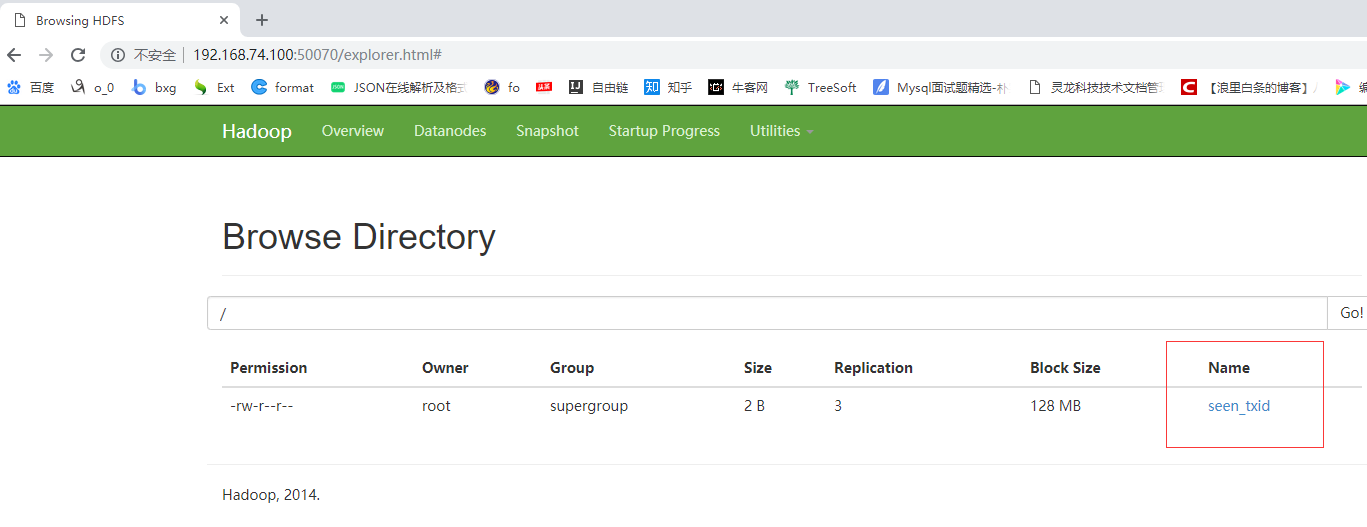
Browse Directory
集群关闭
1 手动关闭
2 一键关闭
cd /root/apps/hadoop/sbin/
stop-dfs.sh
配置 slaves
vi salves
写入
mini1
mini2
mini3
保存退出
mv ./slaves /root/apps/hadoop/etc/hadoop/
拷贝到另外两台机器
scp -r /root/apps/hadoop/etc/hadoop/slaves root@mini2:/root/apps/hadoop/etc/hadoop/
scp -r /root/apps/hadoop/etc/hadoop/slaves root@mini3:/root/apps/hadoop/etc/hadoop/
一键启动集群
start-dfs.sh
一键关闭集群
stop-dfs.sh
大数据学习——hdfs集群启动的更多相关文章
- 大数据学习——yarn集群启动
启动yarn命令: start-yarn.sh 验证是否启动成功 jps查看进程 http://192.168.74.100:8088页面 关闭 stop-yarn.sh
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——Kafka集群部署
1下载安装包 2解压安装包 -0.9.0.1.tgz -0.9.0.1 kafka 3修改配置文件 cp server.properties server.properties.bak # Lice ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习——下载集群根目录下的文件到E盘
代码如下: package cn.itcast.hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuratio ...
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- CDH构建大数据平台-配置集群的Kerberos认证安全
CDH构建大数据平台-配置集群的Kerberos认证安全 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 当平台用户使用量少的时候我们可能不会在一集群安全功能的缺失,因为用户少,团 ...
随机推荐
- Analyzing Polyline CodeForces - 195D
Analyzing Polyline CodeForces - 195D 题意:有n个函数,第i个函数yi(x)=max(ki*x+bi,0).定义函数s(x)=y1(x)+y2(x)+...+yn( ...
- Elipse 无法启动问题(转)
来源: <http://www.cnblogs.com/coding-way/archive/2012/10/17/2727481.html> 当选择完workspace之后,eclips ...
- fgetcsv()函数
fgetcsv()函数.fgetcsv()函数可以读取指定文件的当前行,使用CSV格式解析出字段,并返回一个包含这些字段的数组.语法格式如下:array fgetcsv(resource $handl ...
- Finally语句
- AO-XXXX
一 AO4419:应用于开关应用或PWM应用的场效应管.
- Oracle 十大SQL语句
oracle数据库十大SQL语句 操作对象(object) /*创建对象 table,view,procedure,trigger*/ create object object ...
- B树、B+树、红黑树、AVL树
定义及概念 B树 二叉树的深度较大,在查找时会造成I/O读写频繁,查询效率低下,所以引入了多叉树的结构,也就是B树.阶为M的B树具有以下性质: 1.根节点在不为叶子节点的情况下儿子数为 2 ~ M2. ...
- 如何查看安装的java是32位的,还是64位的
命令 java -d32 -version 或者 java -d64 -version
- 获取页面URL两种方式
以请求http://localhost:8080/doctor/demo?code=1为例 一:用java代码获取 //获取URL中的请求参数.即?后的条件 code=1 String querySt ...
- vue-cli下面的config/index.js注解 webpack.base.conf.js注解
config/indexjs详解上代码: 'use strict' // Template version: 1.3.1 // see http://vuejs-templates.github.io ...