49、Spark Streaming基本工作原理
一、大数据实时计算介绍
1、概述
Spark Streaming,其实就是一种Spark提供的,对于大数据,进行实时计算的一种框架。它的底层,其实,也是基于我们之前讲解的Spark Core的。
基本的计算模型,还是基于内存的大数据实时计算模型。而且,它的底层的组件或者叫做概念,其实还是最核心的RDD。 只不过,针对实时计算的特点,在RDD之上,进行了一层封装,叫做DStream。其实,学过了Spark SQL之后,你理解这种封装就容易了。之前学习Spark SQL是不是也是发现,
它针对数据查询这种应用,提供了一种基于RDD之上的全新概念,DataFrame,但是,其底层还是基于RDD的。所以,RDD是整个Spark技术生态中的核心。
要学好Spark在交互式查询、实时计算上的应用技术和框架,首先必须学好Spark核心编程,也就是Spark Core。
2、图解

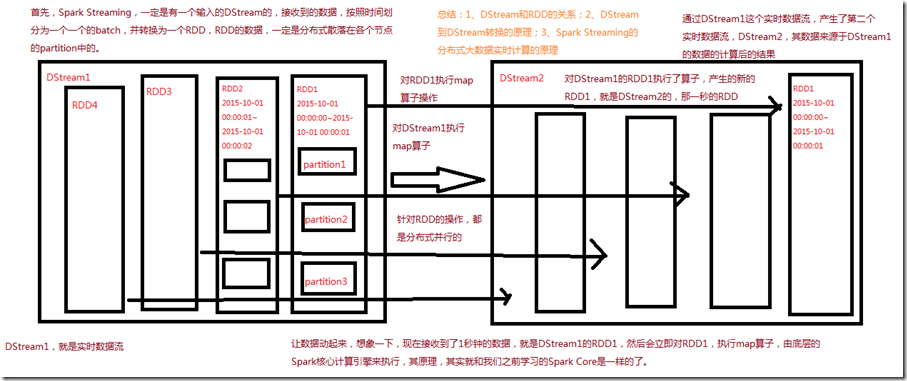
二、Spark Streaming基本工作原理
1、Spark Streaming简介
Spark Streaming是Spark Core API的一种扩展,它可以用于进行大规模、高吞吐量、容错的实时数据流的处理。它支持从很多种数据源中读取数据,
比如Kafka、Flume、Twitter、ZeroMQ、Kinesis或者是TCP Socket。并且能够使用类似高阶函数的复杂算法来进行数据处理,比如map、reduce、join和window。
处理后的数据可以被保存到文件系统、数据库、Dashboard等存储中。

2、Spark Streaming基本工作原理
Spark Streaming内部的基本工作原理如下:接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,
然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),
每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,
将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行缓存或者存储到外部设备。下图显示了Spark Streaming的整个流程。
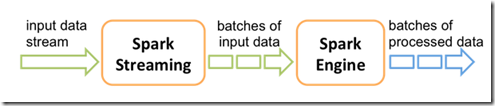
三、DStream
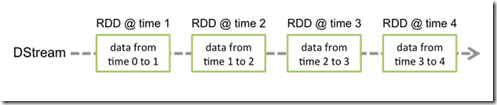
Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。
DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。 DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,不可变的,分布式的数据集。DStream中的每个RDD都包含了一个时间段内的数据。
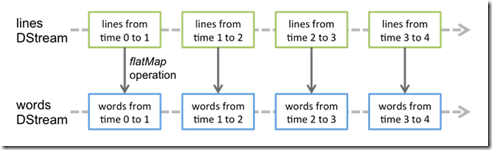
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。
但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。
底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,
然后对开发人员提供了方便易用的高层次的API。
四、Spark Streaming与Storm的对比
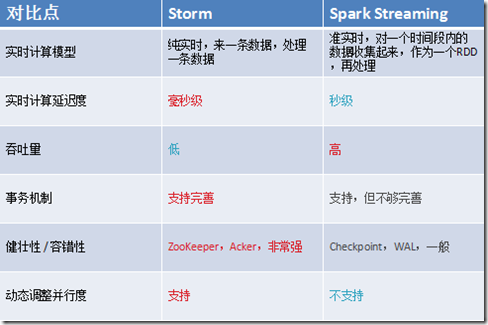
1、Spark Streaming与Storm的优劣分析
事实上,Spark Streaming绝对谈不上比Storm优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。 Spark Streaming仅仅在吞吐量上比Storm要优秀,而吞吐量这一点,也是历来挺Spark Streaming,贬Storm的人着重强调的。
但是问题是,是不是在所有的实时计算场景下,都那么注重吞吐量?不尽然。因此,通过吞吐量说Spark Streaming强于Storm,不靠谱。 事实上,Storm在实时延迟度上,比Spark Streaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性 / 容错性、
动态调整并行度等特性,都要比Spark Streaming更加优秀。 Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,
也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了Spark Streaming的优势和功能。
2、Spark Streaming与Storm的应用场景
对于Storm来说:
1、建议在那种需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时金融系统,要求纯实时进行金融交易和分析
2、此外,如果对于实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm
3、如果还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
4、如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择 对于Spark Streaming来说:
1、如果对上述适用于Storm的三点,一条都不满足的实时场景,即,不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,
而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,
用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
49、Spark Streaming基本工作原理的更多相关文章
- 一图看懂hadoop Spark On Yarn工作原理
hadoop Spark On Yarn工作原理
- Spark Streaming简介及原理
简介: SparkStreaming是一套框架. SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理. 支持多种数据源获取数据: Spark ...
- Spark Streaming fileStream实现原理
fileStream是Spark Streaming Basic Source的一种,用于“近实时”地分析HDFS(或者与HDFS API兼容的文件系统)指定目录(假设:dataDirectory)中 ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- 63、Spark Streaming:架构原理深度剖析
一.架构原理深度剖析 StreamingContext初始化时,会创建一些内部的关键组件,DStreamGraph,ReceiverTracker,JobGenerator,JobScheduler, ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- Spark Streaming笔记
Spark Streaming学习笔记 liunx系统的习惯创建hadoop用户在hadoop根目录(/home/hadoop)上创建如下目录app 存放所有软件的安装目录 app/tmp 存放临时文 ...
- spark streaming (一)
实时计算介绍 Spark Streaming, 其实就是一种Spark提供的, 对于大数据, 进行实时计算的一种框架. 它的底层, 其实, 也是基于我们之前讲解的Spark Core的. 基本的计算模 ...
- Spark Streaming 入门
概述 什么是 Spark Streaming? Spark Streaming is an extension of the core Spark API that enables scalable, ...
随机推荐
- oracle 分页sql
select * from ( SELECT A.*, ROWNUM RN FROM ( SELECT A.*,B.USERPWiD from 测试表2 A left join 测试表3 B on A ...
- (转)Python_如何把Python脚本导出为exe程序
原文地址:https://www.cnblogs.com/robinunix/p/8426832.html 一.pyinstaller简介 Python是一个脚本语言,被解释器解释执行.它的发布方式: ...
- C# vb .net实现过度曝光效果滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的过度曝光效果呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第 ...
- 读取txt文件的数据,并将其转换为矩阵
import numpy as nppath_txt_data = 'C:/Users/51102/Desktop/my_yolo/data/box/train.txt'def input_data( ...
- Python进阶(六)----装饰器
Python进阶(六)----装饰器 一丶开放封闭原则 开放原则: 增加一些额外的新功能 封闭原则: 不改变源码.以及调用方式 二丶初识装饰器 装饰器: 也可称装饰器函数,诠释开放封闭原则 ...
- vue 数据更新问题
在uni-app构建选项卡时,方法中改变的数组数据 无法更新v-if中的布尔值 在函数中打印出来是修改成功了,但在页面中并没有进行响应 布局如下: <swiper :current=" ...
- koa2--session的实现
koa2原生功能只提供了cookie的操作,但是没有提供session操作.session只能自己实现或者通过第三方中间件实现. 如果session数据量很小,可以直接存在内存中 如果session数 ...
- 二维码扫码登录原理及简单demo
扫码登录原理转载自: https://www.cnblogs.com/liyasong/p/saoma.html 需求介绍 首先,介绍下什么是扫码登录.现在,大部分同学手机上都装有qq和淘宝,天猫等这 ...
- vue v-for中的item改变无法引起视图的更新
写过angularjs的同学知道,如果ng-repeat中的item绑定到对应的model,item改变是会引起视图的更新的,但是vue中不起作用,具体的解决办法: 在vue脚手架中,首先引入vue ...
- Gitlab创建一个项目(三)使用IntelliJ IDEA开发项目
Gitlab创建一个项目 Gitlab创建一个项目(二)创建新用户以及分配项目 1.登陆到gitlab 2.点击项目名,获取http的URL 3.idea打开,选择git 4.设置项目路径以及本地保存 ...