在local模式下的spark程序打包到集群上运行
一、前期准备
前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客:
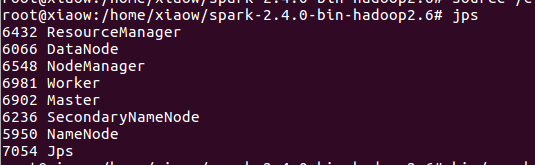
然后在spark伪分布式的环境下必须出现如下八个节点才算spark环境搭建好。
然后再在本地windows系统下有一个简单的词频统计程序。
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD object ScalaSparkDemo {
def main(args: Array[String]) {
/**
* 第一步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要连接的Spark集群的Master的URL,
* 如果设置为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差
* (例如只有1G的内存)的初学者
*/
val conf = new SparkConf() //创建SparkConf对象,由于全局只有一个SparkConf所以不需要工厂方法
conf.setAppName("wow,my first spark app") //设置应用程序的名称,在程序的监控界面可以看得到名称
//conf.setMaster("local") //此时程序在本地运行,不需要安装Spark集群
/**
* 第二步:创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须要有一个
* SparkContext
* SparkContext核心作用:初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler,TaskScheduler,SchedulerBacked,
* 同时还会负责Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
val sc = new SparkContext(conf) //创建SpackContext对象,通过传入SparkConf实例来定制Spark运行的具体参数的配置信息
/**
* 第三步:根据具体的数据来源(HDFS,HBase,Local,FileSystem,DB,S3)通过SparkContext来创建RDD
* RDD的创建基本有三种方式,(1)根据外部的数据来源(例如HDFS)(2)根据Scala集合(3)由其它的RDD操作
* 数据会被RDD划分为成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*/
//读取本地文件并设置为一个Partition
// val lines = sc.textFile("words.txt", 1) //第一个参数为为本地文件路径,第二个参数minPartitions为最小并行度,这里设为1
sc.setLogLevel("WARN")
val lines = sc.parallelize(List("pandas","i like pandas"))
//类型推断 ,也可以写下面方式
// val lines : RDD[String] =sc.textFile("words.txt", 1)
/**
* 第四步:对初始的RDD进行Transformation级别的处理,例如map,filter等高阶函数
* 编程。来进行具体的数据计算
* 第4.1步:将每一行的字符串拆分成单个的单词
*/
//对每一行的字符串进行单词拆分并把所有行的结果通过flat合并成一个大的集合
val words = lines.flatMap { line => line.split(" ") }
/**
* 第4.2步在单词拆分的基础上,对每个单词实例计数为1,也就是word=>(word,1)tuple
*/
val pairs = words.map { word => (word, 1) }
/**
* 第4.3步在每个单词实例计数为1的基础之上统计每个单词在文中出现的总次数
*/
//对相同的key进行value的累加(包括local和Reduce级别的同时Reduce)
val wordCounts = pairs.reduceByKey(_ + _)
//打印结果
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))
//释放资源
sc.stop()
}
}
二、导出jar包
这里注意词频统计程序的包名为test,类名为ScalaSparkDemo。

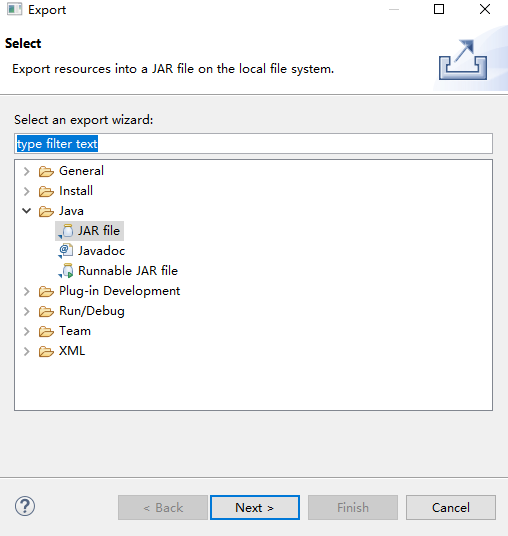
注意这里勾选要打包所依赖的一些文件。当然可以选择把整个工程打包。还要注意这里打包后的文件名为test.jar。

然后上传到Ubuntu中,使用这个命令 bin/spark-submit --class test.ScalaSparkDemo --master local /home/xiaow/test.jar 即可运行。/home/xiaow/test.jar:指明此jar包在主节点上的位置。关于打包到集群的详细命令,可以查阅我的这一篇博客:Spark学习之在集群上运行Spark

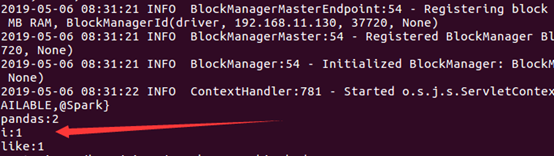
如此,搞定收工!!!
在local模式下的spark程序打包到集群上运行的更多相关文章
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- Spark学习笔记——在集群上运行Spark
Spark运行的时候,采用的是主从结构,有一个节点负责中央协调, 调度各个分布式工作节点.这个中央协调节点被称为驱动器( Driver) 节点.与之对应的工作节点被称为执行器( executor) 节 ...
- 012 Spark在IDEA中打jar包,并在集群上运行(包括local模式,standalone模式,yarn模式的集群运行)
一:打包成jar 1.修改代码 2.使用maven打包 但是目录中有中文,会出现打包错误 3.第二种方式 4.下一步 5.下一步 6.下一步 7.下一步 8.下一步 9.完成 二:在集群上运行(loc ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 06、部署Spark程序到集群上运行
06.部署Spark程序到集群上运行 6.1 修改程序代码 修改文件加载路径 在spark集群上执行程序时,如果加载文件需要确保路径是所有节点能否访问到的路径,因此通常是hdfs路径地址.所以需要修改 ...
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
随机推荐
- 2019-09-16 16:42:03.621946: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA Traceback (most recent cal
-- ::] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA ...
- 一种Winform类electron的实现
最近看了一篇文章 Winform客户端内嵌Vue页面 使用html作为winform的界面(其实这种做法早在MFC时代就已经有了),不过感觉文章中的封装并不够彻底,所以我忍不住要发一篇博客来说说我 ...
- [转]【kafka】用 Docker 部署 Kafka
ref : https://www.jianshu.com/p/7635ea96e53f 用 Docker 部署 Kafka Kafka 简介 作为一个消息中间件,Kafka 以高扩展性.高吞吐量 ...
- bind named.conf 的理解
[root@46 /]#yum -y install bind bind-chroot bind-libs bind-utils caching-nameserver目录说明/var/named/ch ...
- java定时任务框架Quartz入门与Demo搭建
- 荔枝派zero从焊接到跑起linux
步骤 焊flash芯片(如果大于16M,需要改烧录工具的源码) 焊引脚,为了串口看数据 焊接flash芯片,需要注意1号脚的位置,flash芯片在开发板背面,1号脚位置是靠近麦克风的那边 以下为编译相 ...
- 【GMT43智能液晶模块】例程二十:LAN_DNS实验——域名解析
源代码下载链接: 链接:https://pan.baidu.com/s/16EW6AYpHpXljmBdNvMJM7g提取码:6lyk 复制这段内容后打开百度网盘手机App,操作更方便哦 GMT43购 ...
- k8s记录-docker导入导出改标签
docker save <repository>:<tag> -o <repository>.tar docker save mysql:latest -o m ...
- Spark实战系列目录
1 Spark rdd -- action函数详解与实战 2 Spark rdd -- transformations函数详解与实战(上) 3 Spark rdd -- transformations ...
- 【bat批处理】批量执行某个文件夹下的所有sql文件bat批处理
遍历文件夹下所有的sql文件,然后命令行执行 for /r "D:\yonyou\UBFV60\U9.VOB.Product.Other" %%a in (*.sql) do ( ...