推荐算法之Thompson(汤普森)采样
如果想理解汤普森采样算法,就必须先熟悉了解贝塔分布。
一、Beta(贝塔)分布
Beta分布是一个定义在[0,1]区间上的连续概率分布族,它有两个正值参数,称为形状参数,一般用α和β表示,Beta分布的概率密度函数形式如下:
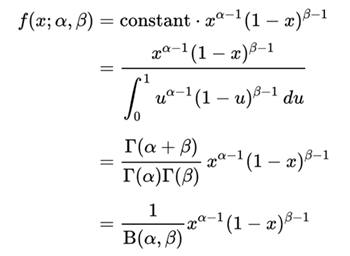
这里的Γ表示gamma函数。
Beta分布的均值是:
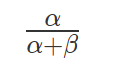
方差:
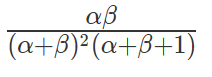
Beta分布的图形(概率密度函数):

从Beta分布的概率密度函数的图形我们可以看出,Beta分布有很多种形状,但都是在0-1区间内,因此Beta分布可以描述各种0-1区间内的形状(事件)。因此,它特别适合为某件事发生或者成功的概率建模。同时,当α=1,β=1的时候,它就是一个均匀分布。
贝塔分布主要有 α和 β两个参数,这两个参数决定了分布的形状,从上图及其均值和方差的公式可以看出:
1)α/(α+β)也就是均值,其越大,概率密度分布的中心位置越靠近1,依据此概率分布产生的随机数也多说都靠近1,反之则都靠近0。
2)α+β越大,则分布越窄,也就是集中度越高,这样产生的随机数更接近中心位置,从方差公式上也能看出来。
二、举例理解Beta分布
贝塔分布可以看作是一个概率的分布,当我们不知道一个东西的具体概率是多少时,它给出了所有概率出现的可能性大小,可以理解为概率的概率分布。
以棒球为例子:
棒球运动的一个指标就是棒球击球率,就是用一个运动员击中的球数除以总的击球数,一般认为0.27是一个平均的击球水平,如果击球率达到0.3就会认为非常优秀了。如果我们要预测一个棒球运动员,他整个赛季的棒球击球率,怎么做呢?你可以直接计算他目前的棒球击球率,用击中数除以击球数。但是,这在赛季开始阶段时是很不合理的。假如这个运动员就打了一次,还中了,那么他的击球率就是100%;如果没中,那么就是0%,甚至打5、6次的时候,也可能运气爆棚全中击球率100%,或者运气很糟击球率0%,所以这样计算出来的击球率是不合理也是不准确的。
为什么呢?
当运动员首次击球没中时,没人认为他整个赛季都会一次不中,所以击球率不可能为0。因为我们有先验期望,根据历史信息,我们知道击球率一般会在0.215到0.36之间。如果一个运动员一开始打了几次没中,那么我们知道他可能最终成绩会比平均稍微差一点,但是一般不可能会偏离上述区间,更不可能为0。
如何解决呢?
一个最好的方法来表示这些先验期望(统计中称为先验(prior))就是贝塔分布,表示在运动员打球之前,我们就对他的击球率有了一个大概范围的预测。假设我们预计运动员整个赛季的击球率平均值大概是0.27左右,范围大概是在0.21到0.35之间。那么用贝塔分布来表示,我们可以取参数 α=81,β=219,因为α/(α+β)=0.27,图形分布也主要集中在0.21~0.35之间,非常符合经验值,也就是我们在不知道这个运动员真正击球水平的情况下,我们先给一个平均的击球率的分布。
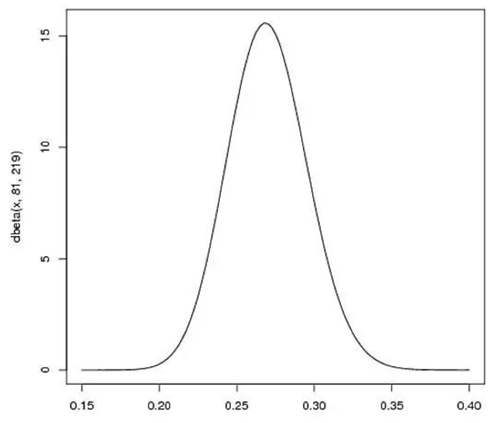
假设运动员一次击中,那么现在他本赛季的记录是“1次打中;1次打击”。那么我们更新我们的概率分布,让概率曲线做一些移动来反应我们的新信息。
Beta(α0+hits,β0+misses)
注:α0,β0是初始化参数,也就是本例中的81,219。hits表示击中的次数,misses表示未击中的次数。
击中一次,则新的贝塔分布为Beta(81+1,219),一次并不能反映太大问题,所以在图形上变化也不大,不画示意图了。然而,随着整个赛季运动员逐渐进行比赛,这个曲线也会逐渐移动以匹配最新的数据。由于我们拥有了更多的数据,因此曲线(击球率范围)会逐渐变窄。假设赛季过半时,运动员一共打了300次,其中击中100次。那么新的贝塔分布是Beta(81+100,219+200),如下图:

可以看出,曲线更窄而且往右移动了(击球率更高),由此我们对于运动员的击球率有了更好的了解。新的贝塔分布的期望值为0.303,比直接计算100/(100+200)=0.333要低,是比赛季开始时的预计0.27要高,所以贝塔分布能够抛出掉一些偶然因素,比直接计算击球率更能客观反映球员的击球水平。
总结:
这个公式就相当于给运动员的击中次数添加了“初始值”,相当于在赛季开始前,运动员已经有81次击中219次不中的记录。 因此,在我们事先不知道概率是什么但又有一些合理的猜测时,贝塔分布能够很好地表示为一个概率的分布。
三、汤普森采样
汤普森采样的背后原理正是上述所讲的Beta分布,你把贝塔分布的 a 参数看成是推荐后用户点击的次数,把分布的 b 参数看成是推荐后用户未点击的次数,则汤普森采样过程如下:
1、取出每一个候选对应的参数 a 和 b;
2、为每个候选用 a 和 b 作为参数,用贝塔分布产生一个随机数;
3、按照随机数排序,输出最大值对应的候选;
4、观察用户反馈,如果用户点击则将对应候选的 a 加 1,否则 b 加 1;
注:实际上在推荐系统中,要为每一个用户都保存一套参数,比如候选有 m 个,用户有 n 个,那么就要保存 2 m n个参数。
汤普森采样为什么有效呢?
1)如果一个候选被选中的次数很多,也就是 a+b 很大了,它的分布会很窄,换句话说这个候选的收益已经非常确定了,就是说不管分布中心接近0还是1都几乎比较确定了。用它产生随机数,基本上就在中心位置附近,接近平均收益。
2)如果一个候选不但 a+b 很大,即分布很窄,而且 a/(a+b) 也很大,接近 1,那就确定这是个好的候选项,平均收益很好,每次选择很占优势,就进入利用阶段。反之则有可能平均分布比较接近与0,几乎再无出头之日。
3)如果一个候选的 a+b 很小,分布很宽,也就是没有被选择太多次,说明这个候选是好是坏还不太确定,那么分布就是跳跃的,这次可能好,下次就可能坏,也就是还有机会存在,没有完全抛弃。那么用它产生随机数就有可能得到一个较大的随机数,在排序时被优先输出,这就起到了前面说的探索作用。
python代码实现:
choice = numpy.argmax(pymc.rbeta(1 + self.wins, 1 + self.trials - self.wins))
推荐算法之Thompson(汤普森)采样的更多相关文章
- 推荐算法之E&E
一.定义 E&E就是探索(explore)和利用(exploit). Exploit:基于已知最好策略,开发利用已知具有较高回报的item(贪婪.短期回报),对于推荐来讲就是用户已经发现的兴趣 ...
- Mahout推荐算法API详解
转载自:http://blog.fens.me/mahout-recommendation-api/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 【笔记3】用pandas实现矩阵数据格式的推荐算法 (基于用户的协同)
原书作者使用字典dict实现推荐算法,并且惊叹于18行代码实现了向量的余弦夹角公式. 我用pandas实现相同的公式只要3行. 特别说明:本篇笔记是针对矩阵数据,下篇笔记是针对条目数据. ''' 基于 ...
- FP-tree推荐算法
推荐算法大致分为: 基于物品和用户本身 基于关联规则 基于模型的推荐 基于物品和用户本身 基于物品和用户本身的,这种推荐引擎将每个用户和每个物品都当作独立的实体,预测每个用户对于每个物品的喜好程度,这 ...
- apriori推荐算法
大数据时代开始流行推荐算法,所以作者写了一篇教程来介绍apriori推荐算法. 推荐算法大致分为: 基于物品和用户本身 基于关联规则 基于模型的推荐 基于物品和用户本身 基于物品和用户本身的,这种推荐 ...
- 推荐算法——距离算法
本文内容 用户评分表 曼哈顿(Manhattan)距离 欧式(Euclidean)距离 余弦相似度(cos simliarity) 推荐算法以及数据挖掘算法,计算"距离"是必须的~ ...
- 将 Book-Crossing Dataset 书籍推荐算法中 CVS 格式测试数据集导入到MySQL数据库
本文内容 最近看<写给程序员的数据挖掘指南>,研究推荐算法,书中的测试数据集是 Book-Crossing Dataset 提供的亚马逊用户对书籍评分的真实数据.推荐大家看本书,写得不错, ...
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- Mahout推荐算法基础
转载自(http://www.geek521.com/?p=1423) Mahout推荐算法分为以下几大类 GenericUserBasedRecommender 算法: 1.基于用户的相似度 2.相 ...
随机推荐
- ROS官网新手级教程总结
第 1 关卡:安装和配置 ROS 环境 目标:在计算机上安装和配置 ROS 环境. 安装 ROS 按照 ROS 安装说明进行安装. 管理环境 确定环境变量 ROS_ROOT 和 ROS_PACKAGE ...
- Scrapy笔记07- 内置服务
Scrapy笔记07- 内置服务 Scrapy使用Python内置的的日志系统来记录事件日志. 日志配置 LOG_ENABLED = true LOG_ENCODING = "utf-8&q ...
- 学习Spring-Data-Jpa(九)---注解式方法查询之@NamedQuery、@NamedNativeQuery
1.@NamedQuery.@NamedNativeQuery @NamedQuery与@NamedNativeQuery都是定义查询的一种形式,@NamedQuery使用的是JPQL,而@Named ...
- 37 树莓派识别opencv-dnn
https://heartbeat.fritz.ai/real-time-object-detection-on-raspberry-pi-using-opencv-dnn-98827255fa60 ...
- 自用ftp上传脚本
#!/bin/sh backupserver=$1 #localdir=ftp_result_tmp username=$3 password=$4 #remodir='./Log/2018-01-2 ...
- 原题链接在这里:980. Unique Paths III
原题链接在这里:https://leetcode.com/problems/unique-paths-iii/ 题目: On a 2-dimensional grid, there are 4 typ ...
- <虚树+树型DP> SDOI2011消耗战
<虚树+树型DP> SDOI2011消耗战 #include <iostream> #include <cstdio> #include <cstring&g ...
- LOJ2687 BOI2013Vim 题解
题目链接 这里只写个摘要,具体的可以看 神仙Itst的博客 大概是每相邻两个位置之间的线段要么被覆盖一次,要么被覆盖三次,然后DP,如下图: 代码: #include<bits/stdc++.h ...
- 【luoguP1533】可怜的狗狗
题目链接 发现区间按左端点排序后右端点也是单调的,所以扫一遍就行了,用权值线段树维护第\(k\)大 #include<algorithm> #include<iostream> ...
- Linux下的串口编程(转)
https://blog.csdn.net/tigerjibo/article/details/6179291 #include<stdio.h> /*标准输入输出定义*/ #includ ...