Cloudera Certified Associate Administrator案例之Configure篇
Cloudera Certified Associate Administrator案例之Configure篇
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.下载CDH集群中最新的配置文件
问题描述:
某个集群的使用者需要通过客户端登陆集群,请使用CM下载HDFS和YARN的配置文件,保存到客户端机器的"/home/yinzhengjie/hadoop/etc/hadoop"目录下,并保持文件名不变。 解决方案:
可以通过登陆CM WebUI界面下载,也可以直接登陆服务器进行下载。
1>.使用正确的用户名密码登录CM界面,点击hdfs服务

2>. 下载HDFS的配置文件

3>.使用正确的用户名密码登录CM界面,点击yarn服务
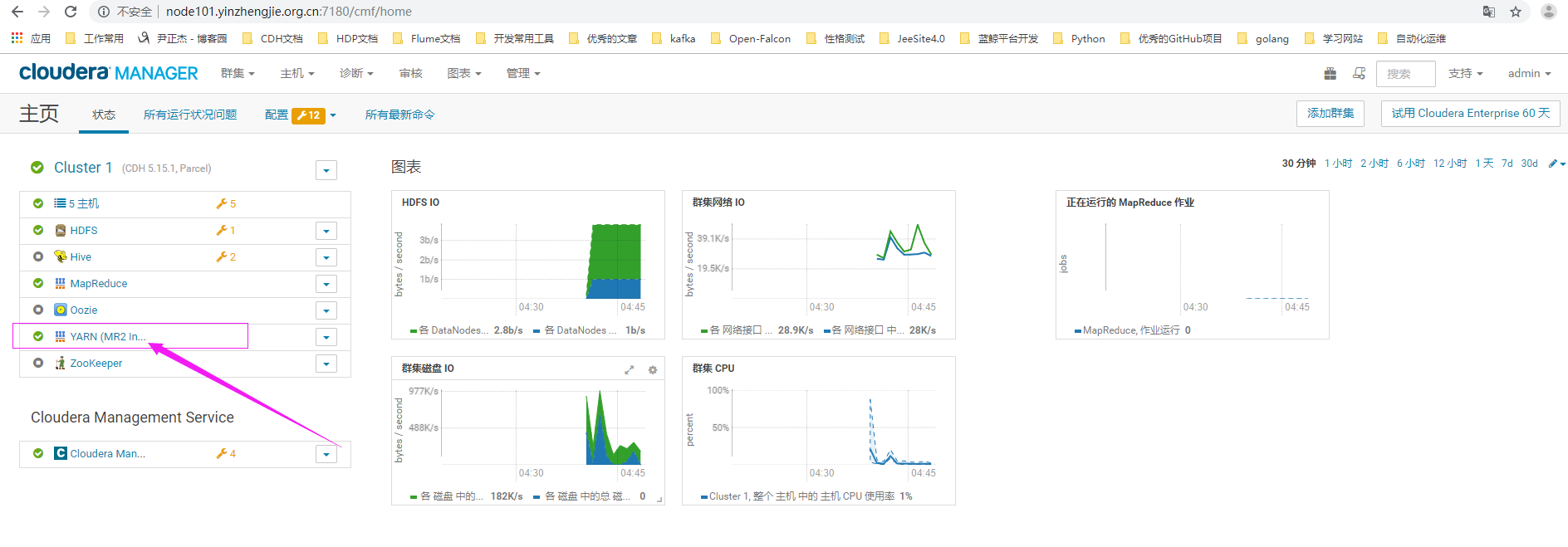
4>.下载YARN服务的配置文件
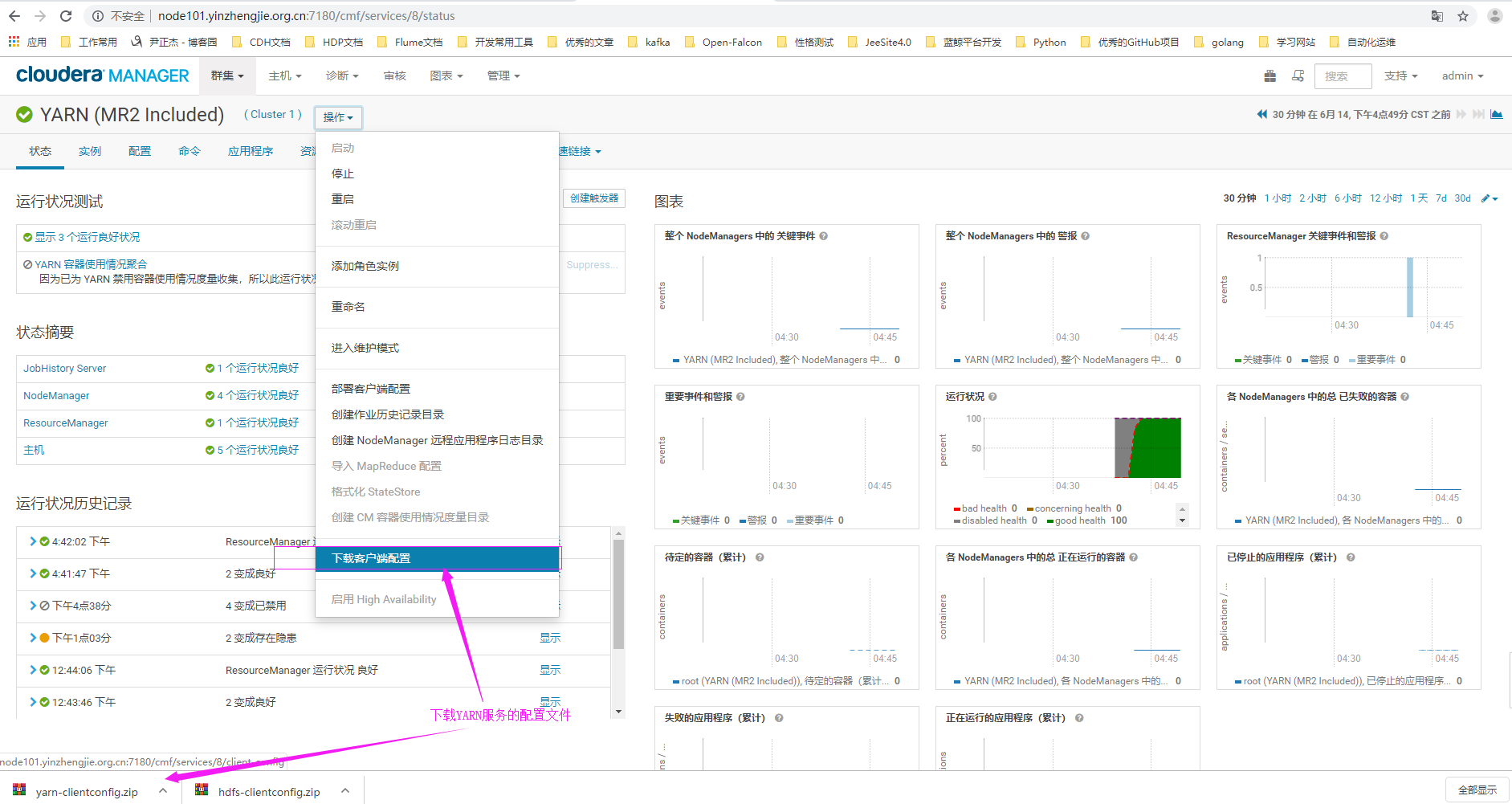
5>.查看集群后端存储配置文件的路径
[root@node101.yinzhengjie.org.cn ~]# ll /etc/hadoop/conf.cloudera.hdfs/ #HDFS集群存储路径
total
-rw-r--r-- root root Jun : __cloudera_generation__
-rw-r--r-- root root Jun : __cloudera_metadata__
-rw-r--r-- root root Jun : core-site.xml
-rw-r--r-- root root Jun : hadoop-env.sh
-rw-r--r-- root root Jun : hdfs-site.xml
-rw-r--r-- root root Jun : log4j.properties
-rw-r--r-- root root Jun : ssl-client.xml
-rw-r--r-- root root Jun : topology.map
-rwxr-xr-x root root Jun : topology.py
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# ll /etc/hadoop/conf.cloudera.yarn/ #YARN集群存储路径
total
-rw-r--r-- root root Jun : __cloudera_generation__
-rw-r--r-- root root Jun : __cloudera_metadata__
-rw-r--r-- root root Jun : core-site.xml
-rw-r--r-- root root Jun : hadoop-env.sh
-rw-r--r-- root root Jun : hdfs-site.xml
-rw-r--r-- root root Jun : log4j.properties
-rw-r--r-- root root Jun : mapred-site.xml
-rw-r--r-- root root Jun : ssl-client.xml
-rw-r--r-- root hadoop Jun : topology.map
-rwxr-xr-x root hadoop Jun : topology.py
-rw-r--r-- root root Jun : yarn-site.xml
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
二.限制HDFS服务的日志大小
问题描述:
根据管理要求,需要限制HDFS服务的日志大小。其限制为:NameNode服务保留4个日志文件,总量不超过8GB;Secondary NameNode 服务也保留4个日志文件,总量不超过8GB;两个服务总占用的磁盘空间 量不超过16GB。 解决方案:
单个服务的单个日志只要不超 过2GB,并将日志数设为4个,即可以满足要求。
1>.使用正确的用户名密码登录CM界面,点击hdfs服务
2>.搜索关键字“NameNode Max Log Size”
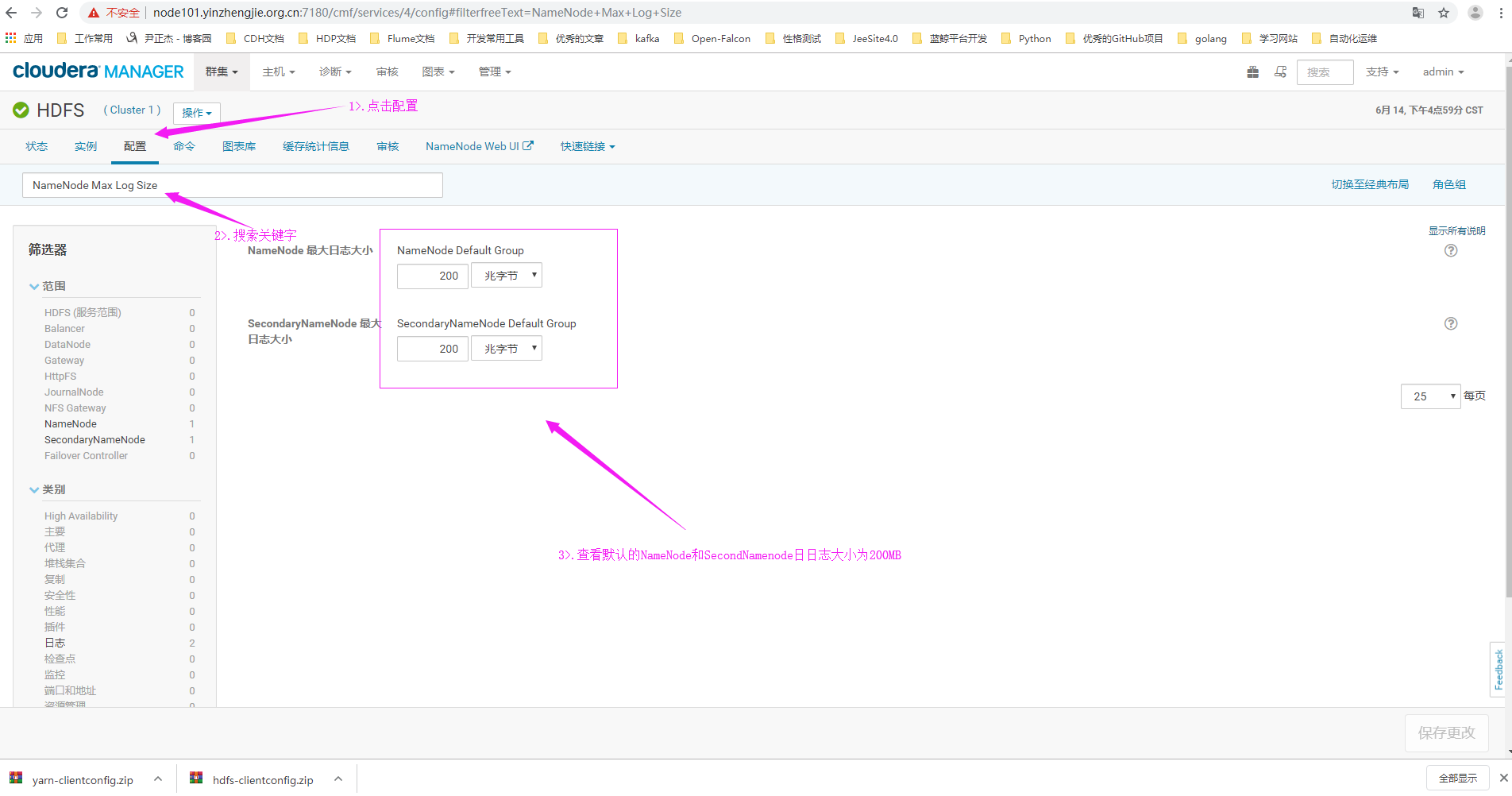
3>.修改默认值200MB为2GB并点击保存按钮

4>.搜索关键字“SecondaryNameNode Max Log Size”(中文对应:"SecondaryNameNode 最大日志文件备份")
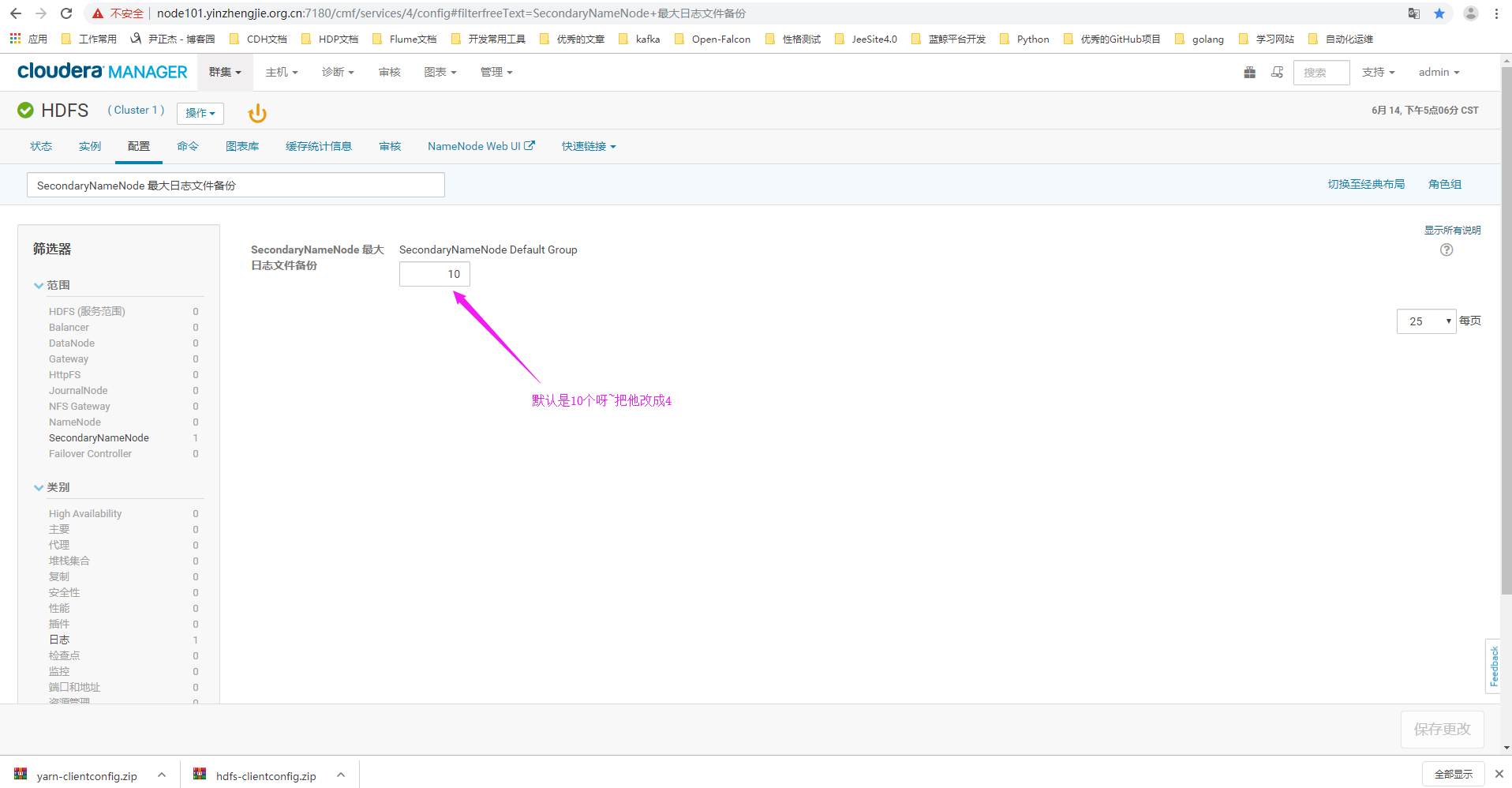
5>.修改日志文件的备份数为4
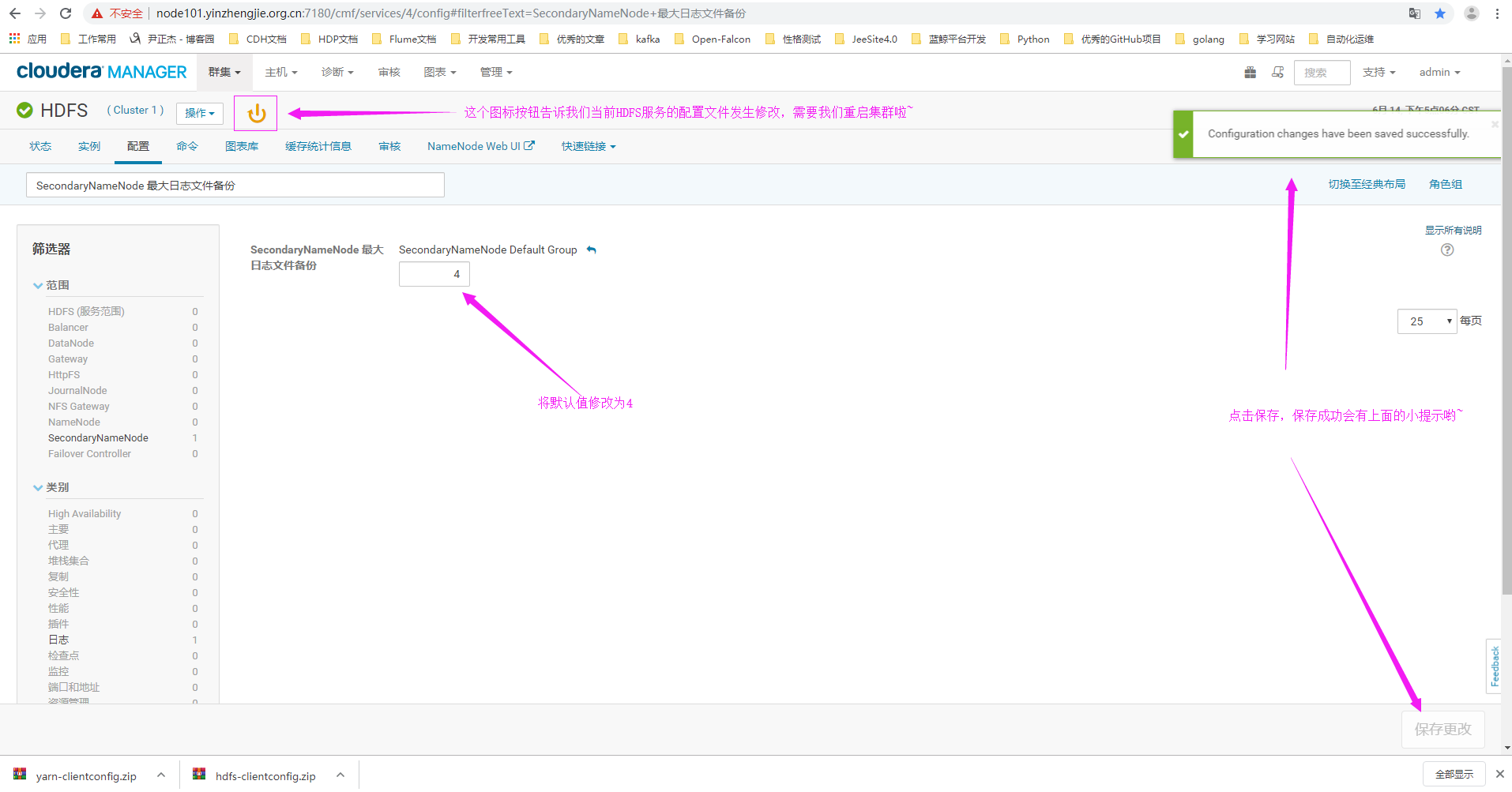
6>.重启HDFS服务

三.修改Namenode的堆内存
问题描述:
集群承接了日志分析需求,将保存百万、千万数量级的文件,因 此需要扩大NameNode使用的堆内存,使其可以管理尽可能多的文件。物理内存的分配要求为:节点总物理内存为31GB,为系统服务保留的内存为6.2GB;NameNode和Secondary NameNode需设置相等大小的堆内存; 所有服务的堆内存均需要乘以1.3后计入总使用量中。需要为NameNode和相关服务配置尽可能大且满足要求的内存量,且不能触发任何警告。 解决方案:
根据计算(31 - 6.2) / 1.3 = 19,因此 NameNode和Secondary NameNode各可设置9.5GB的堆内存。
1>.使用正确的用户名密码登录CM界面,点击hdfs服务
2>.点击配置,搜索关键字“Java Heap Size of NameNode in Bytes”(对应中文为:"NameNode 的 Java 堆栈大小(字节)")
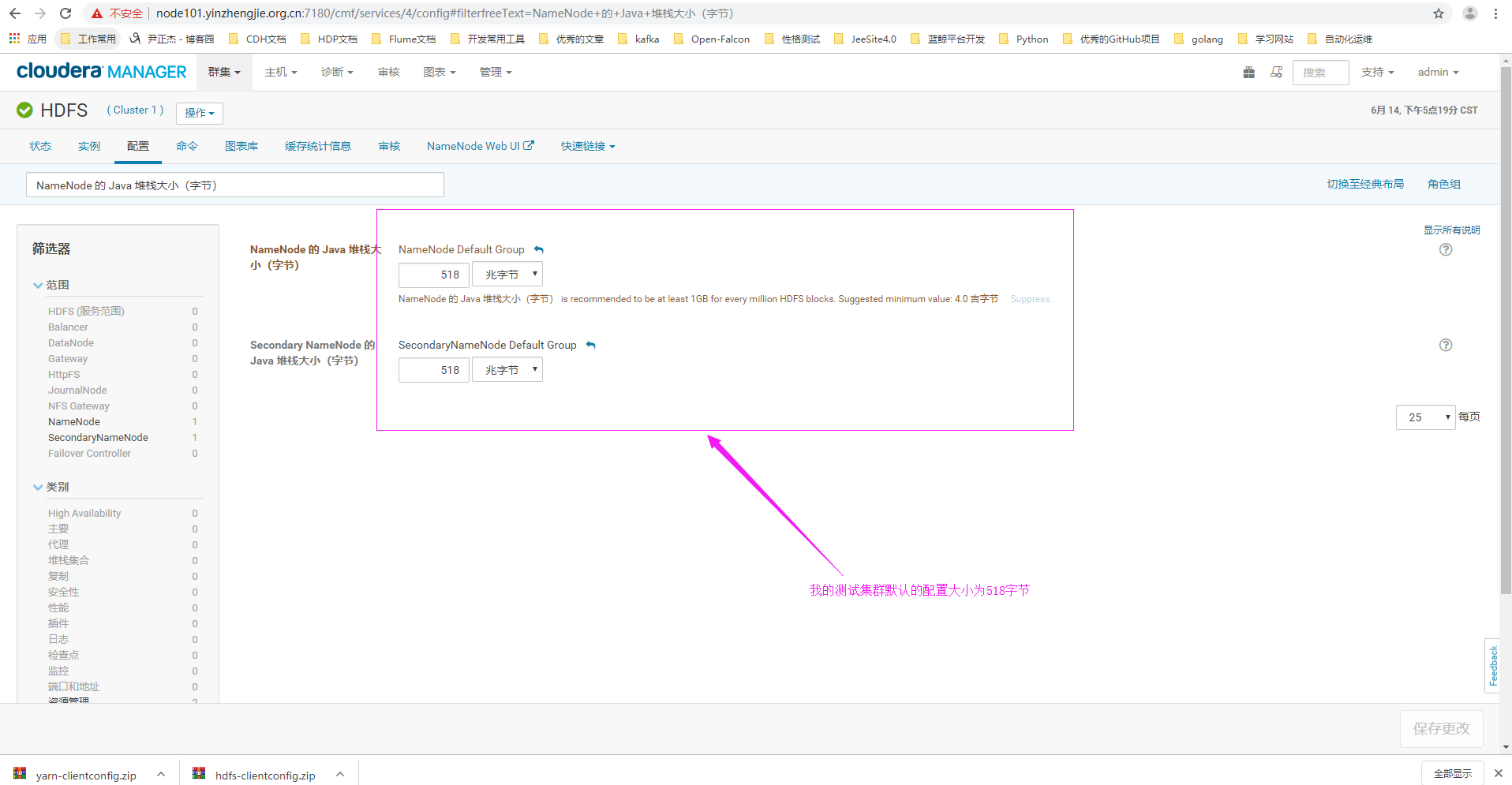
3>.设置NameNode和SencondName的堆内存为9.5GB
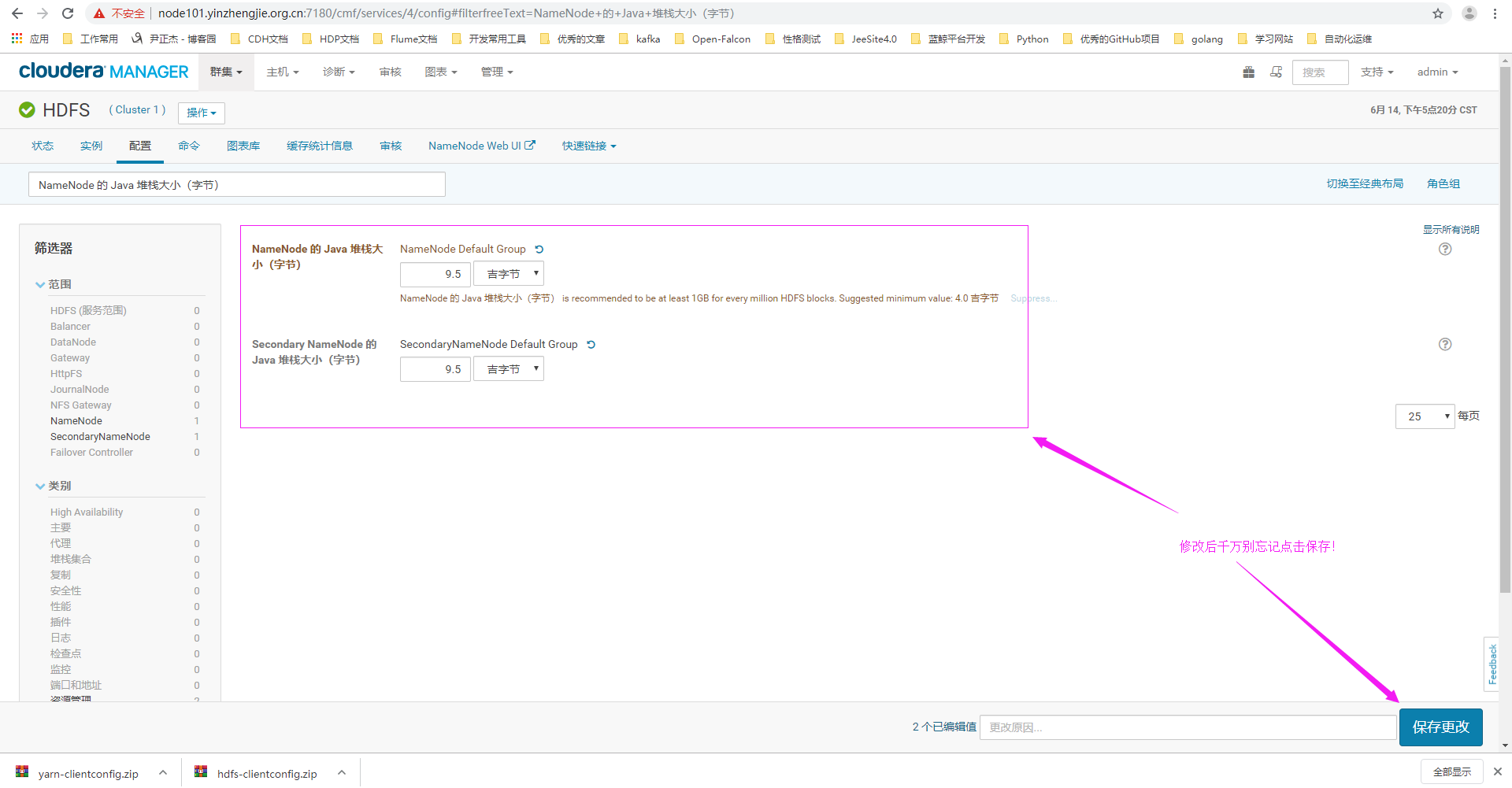
4>.重启HDFS集群(需要注意的是,如果我们设置的NameNode或者SecondNamenode的堆内存大小总和大于当前服务器内存时,我们在重启集群时会启动失败!)
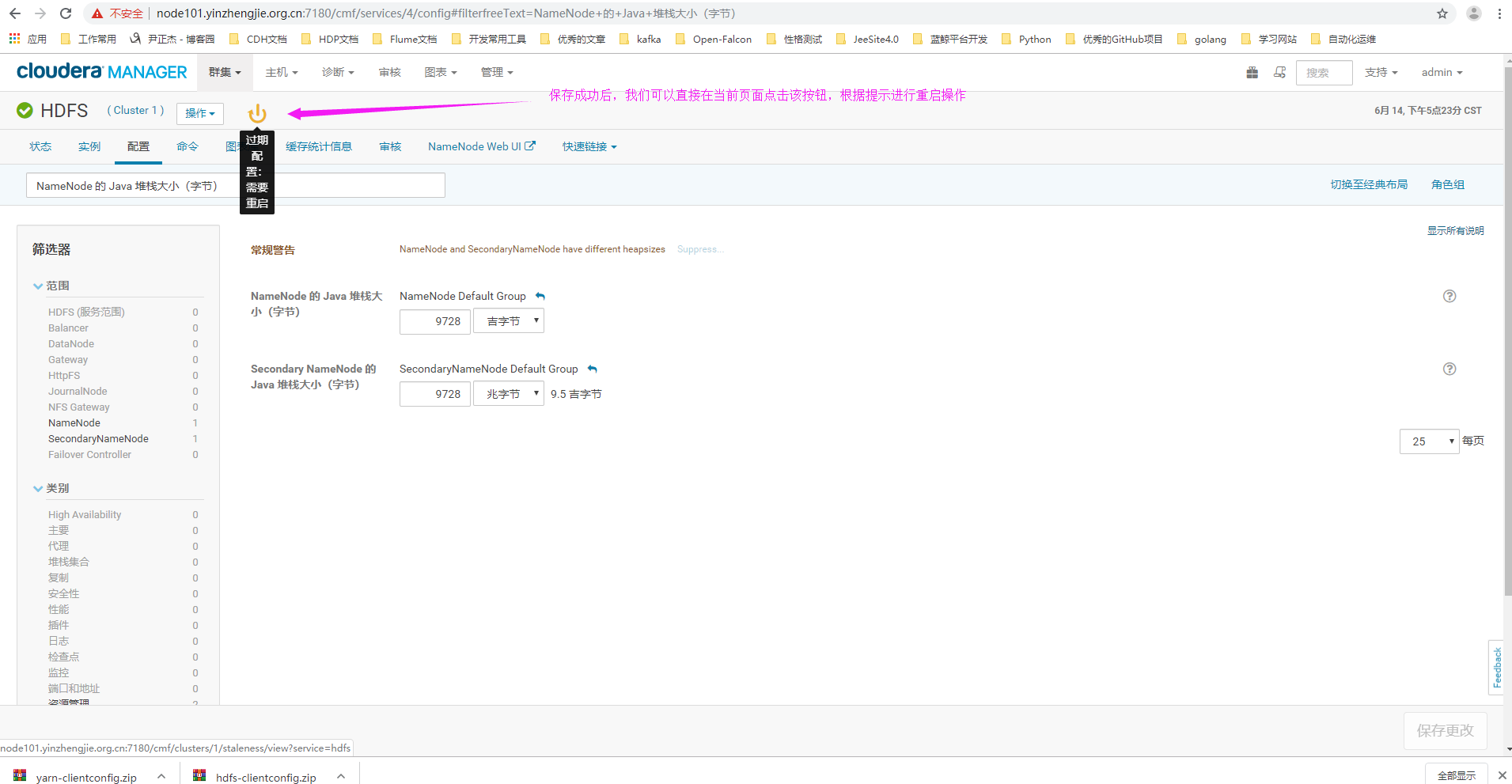
四.开启回收站功能
问题描述:
在描述公司的运维策略时,有人提出如果误删了HDFS的文件系统,可能几天都不会出现,尤其时当周末前发生这样的情况时。为了提供足够的保护级别,你决定将HDFS数据删除后永久清除的时间改为7天。 解决方案:
我们直接在Cloudera Manager WebUI界面进行配置即可。除了配置回收站,还可以配置权限,副本书,块大小,balancer等。
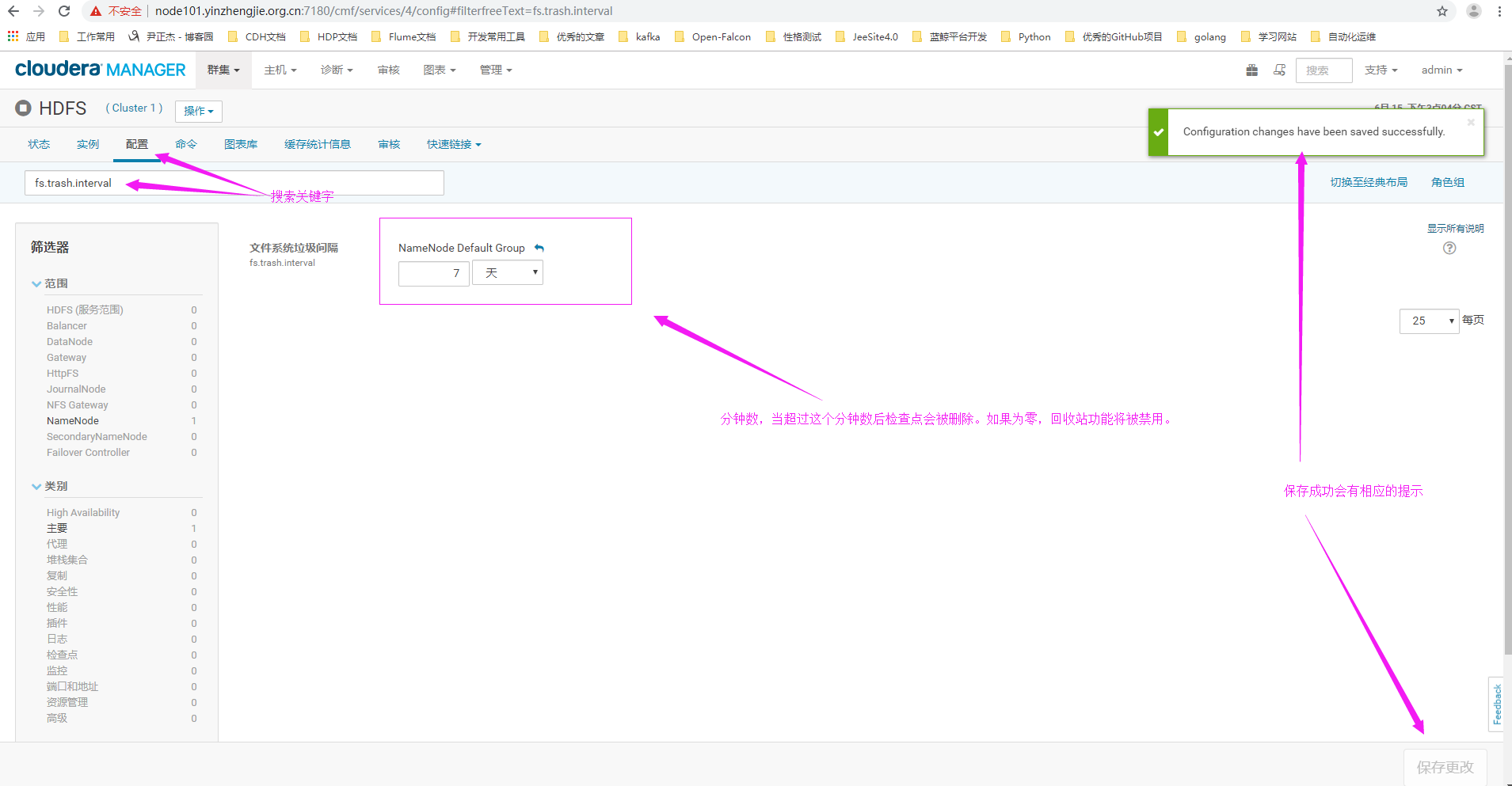
1>.点击HDFS服务

2>.点击配置,并搜索关键字"fs.trash.interval",修改其只为7天,即删除的文件在回收站中被保留的时间周期
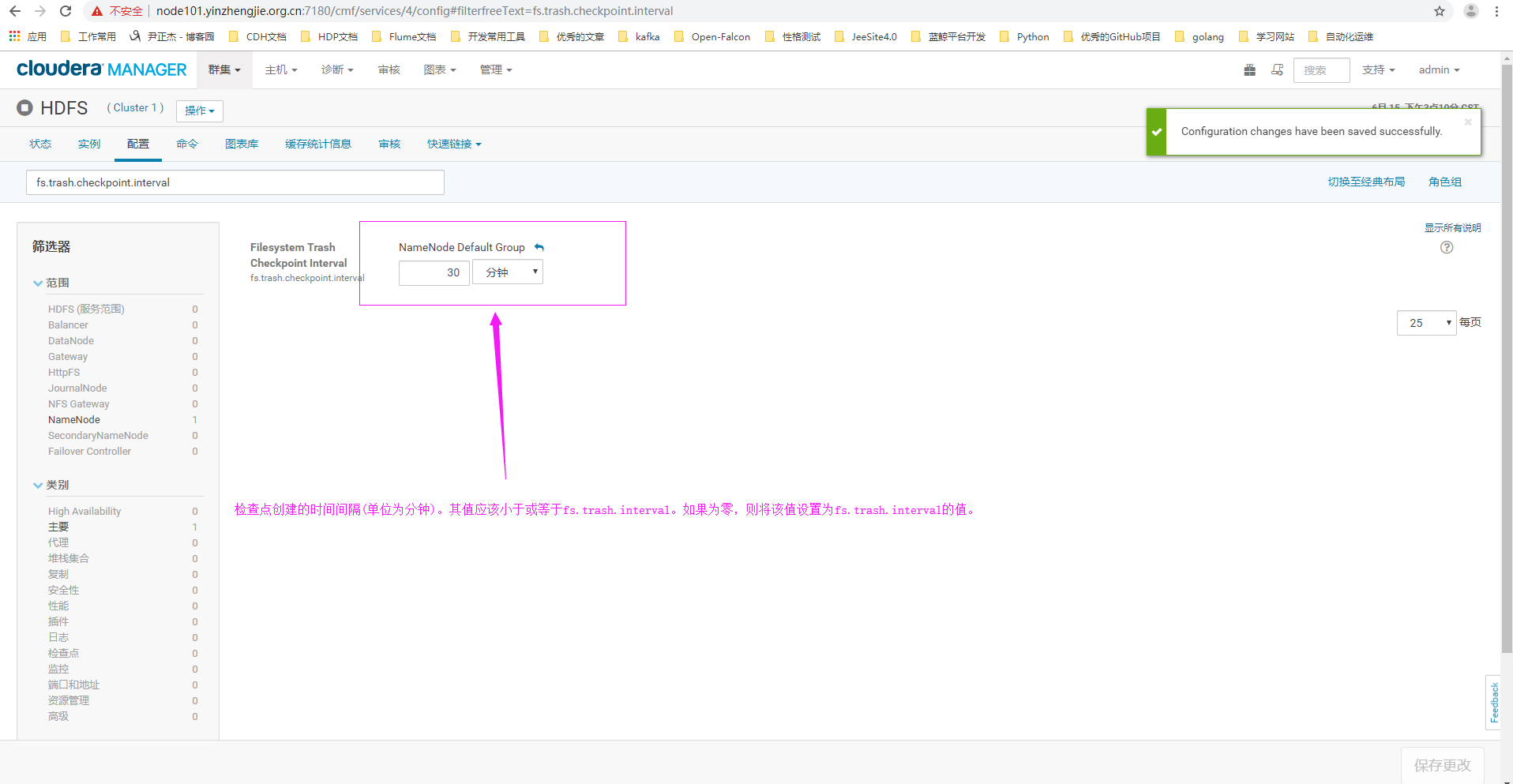
3>.搜索关键词"fs.trash.checkpoint.interval",即定义周期性检查回收站的文件是否过期的时间间隔,改值应该小于上面我们定义"fs.trash.interval"的值
五.
Cloudera Certified Associate Administrator案例之Configure篇的更多相关文章
- Cloudera Certified Associate Administrator案例之Troubleshoot篇
Cloudera Certified Associate Administrator案例之Troubleshoot篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.调整日志的进 ...
- Cloudera Certified Associate Administrator案例之Test篇
Cloudera Certified Associate Administrator案例之Test篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.准备工作(将CM升级到&qu ...
- Cloudera Certified Associate Administrator案例之Manage篇
Cloudera Certified Associate Administrator案例之Manage篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载Namenode镜像 ...
- Cloudera Certified Associate Administrator案例之Install篇
Cloudera Certified Associate Administrator案例之Install篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.创建主机模板(为了给主 ...
- Flume实战案例运维篇
Flume实战案例运维篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Flume概述 1>.什么是Flume Flume是一个分布式.可靠.高可用的海量日志聚合系统,支 ...
- CNCF基金会的Certified Kubernetes Administrator认证考试计划
关于CKA考试 CKA(Certified Kubernetes Administrator)是CNCF基金会(Cloud Native Computing Foundation)官方推出的Kuber ...
- 分享数百个 HT 工业互联网 2D 3D 可视化应用案例之 2019 篇
继<分享数百个 HT 工业互联网 2D 3D 可视化应用案例>2018 篇,图扑软件定义 2018 为国内工业互联网可视化的元年后,2019 年里我们与各行业客户进行了更深度合作,拓展了H ...
- 数百个 HT 工业互联网 2D 3D 可视化应用案例分享 - 2019 篇
继<分享数百个 HT 工业互联网 2D 3D 可视化应用案例>2018 篇,图扑软件定义 2018 为国内工业互联网可视化的元年后,2019 年里我们与各行业客户进行了更深度合作,拓展了H ...
- robotframework+selenium搭配chrome浏览器,web测试案例(搭建篇)
这两天发布版本 做的事情有点多,都没有时间努力学习了,先给自己个差评,今天折腾了一天, 把robotframework 和 selenium 还有appnium 都研究了一下 ,大概有个谱,先说说we ...
随机推荐
- 【NPDP笔记】第三章 新产品流程
3.1 产品开发,风险与汇报的过程,开发实践和流程提升成功率 管控新产品失败的风险,随着成本增加,风险降低 知识能改改进决策,降低风险,决策框架 识别问题与机会 收集信息 组织记录,组织员工 外部 ...
- C# .net 提升 asp.net mvc, asp.net core mvc 并发量
1.提升System.Net.ServicePointManager.DefaultConnectionLimit 2.提升最小工作线程数 ------ DefaultConnectionLimit在 ...
- 最常见的Java面试题及答案汇总(四)
反射 57. 什么是反射? 反射主要是指程序可以访问.检测和修改它本身状态或行为的一种能力 Java反射: 在Java运行时环境中,对于任意一个类,能否知道这个类有哪些属性和方法?对于任意一个对象,能 ...
- 【Spring Boot学习之四】Spring Boot事务管理
环境 eclipse 4.7 jdk 1.8 Spring Boot 1.5.2 一.springboot整合事务事务分类:编程事务.声明事务(XML.注解),推荐使用注解方式,springboot默 ...
- Google BERT摘要
1.BERT模型 BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为dec ...
- ES6学习小结
ES6(ES2015)--IE10+.Chrome.FireFox.移动端.NodeJS 编译.转换 1.在线转换 2.提前编译 babel = browser.js ES6: 1.变量 var 重复 ...
- k8s-ingress安装
一.编写nginx-ingress-controller.yaml文件 apiVersion: extensions/v1beta1 kind: Deployment metadata: name ...
- 第N个丑数
#include <bits/stdc++.h> using namespace std; #define ll long long /* 把只包含质因子2.3和5的数称作丑数(Ugly ...
- poj1458公共子序列 C语言
/*Common SubsequenceTime Limit: 1000MS Memory Limit: 10000KTotal Submissions: 56416 Accepted: 23516D ...
- status 和 typedef