利用Python进行数据分析 第7章 数据清洗和准备(1)
学习时间:2019/10/25 周五晚上22点半开始。
学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完。
实际反馈:集中学习1.5小时,学习6页;集中学习1.7小时(100分钟),学习5页;
实际20191103学完,因本周工作耽误未进行学习,耗时5天,10小时,平均每页20分钟。
数据准备工作:加载、清理、转换以及重塑,通常会占用分析师80%的时间或更多!!!学会高效的数据清洗和准备,将绝对提升生产力!本章将讨论处理缺失数据、重复数据、字符串操作和其他分析数据转换的工具。下一章将关注用多种方法合并、重塑数据集。
7.1 处理缺失数据
缺失数据在pandas中呈现的方式有些不完美,但对于大多数用户可以保证功能正常。
对于数值数据,pandas使用浮点值NaN(Not a Number)表示缺失数据。称其为哨兵值,可以方便地检测出来:
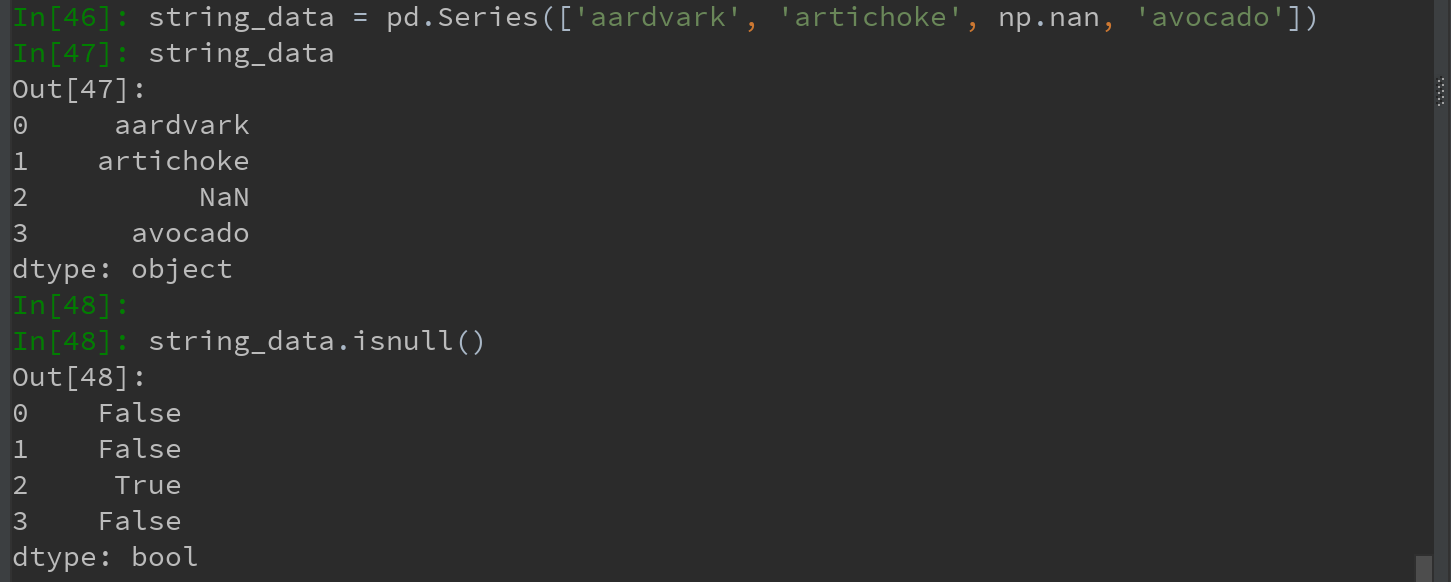
在pandas中,将缺失值表示为NA(R语言地惯用法),表示not available。NA数据可能是不存在地数据或虽然存在但没有观察到。(进行数据清洗时,为便于分析最好直接对缺失数据进行分析,以判断数据采集地问题或缺失胡数据可能导致的偏差。)
Python内置的None值在对象数据中也可以作为NA:

表7-1 一些关于缺失数据处理的函数

7.1.1 滤除缺失数据
过滤缺失数据,用dropna更为实用(也可通过pandas.isnull或布尔索引的手工方法)
对于Series,dropna返回一个仅含非空数据和索引值的Series:

等价于:

对于DataFrame对象, dropna默认丢弃任何含有缺失值的行:

1)传入 how = 'all' 将只丢弃全为NA的行:

2)传入 axis = 1,将丢弃含有NA的所有列,如果同时传入 how = 'all' 则会丢弃全为NA的列:
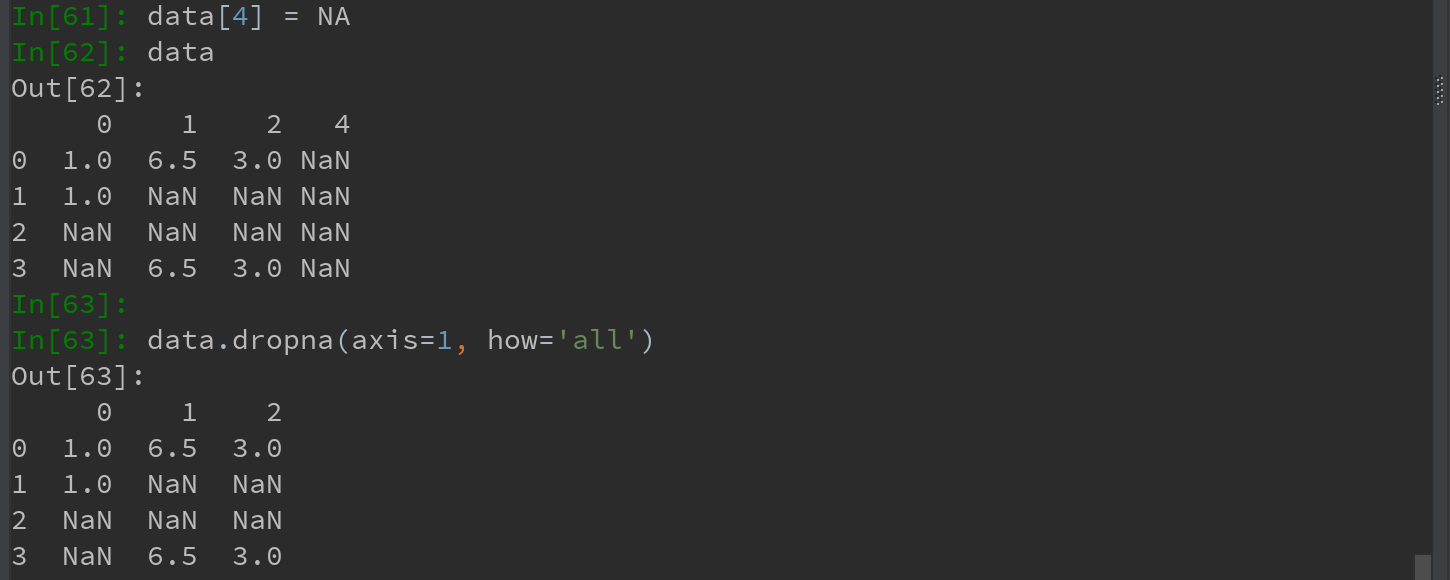
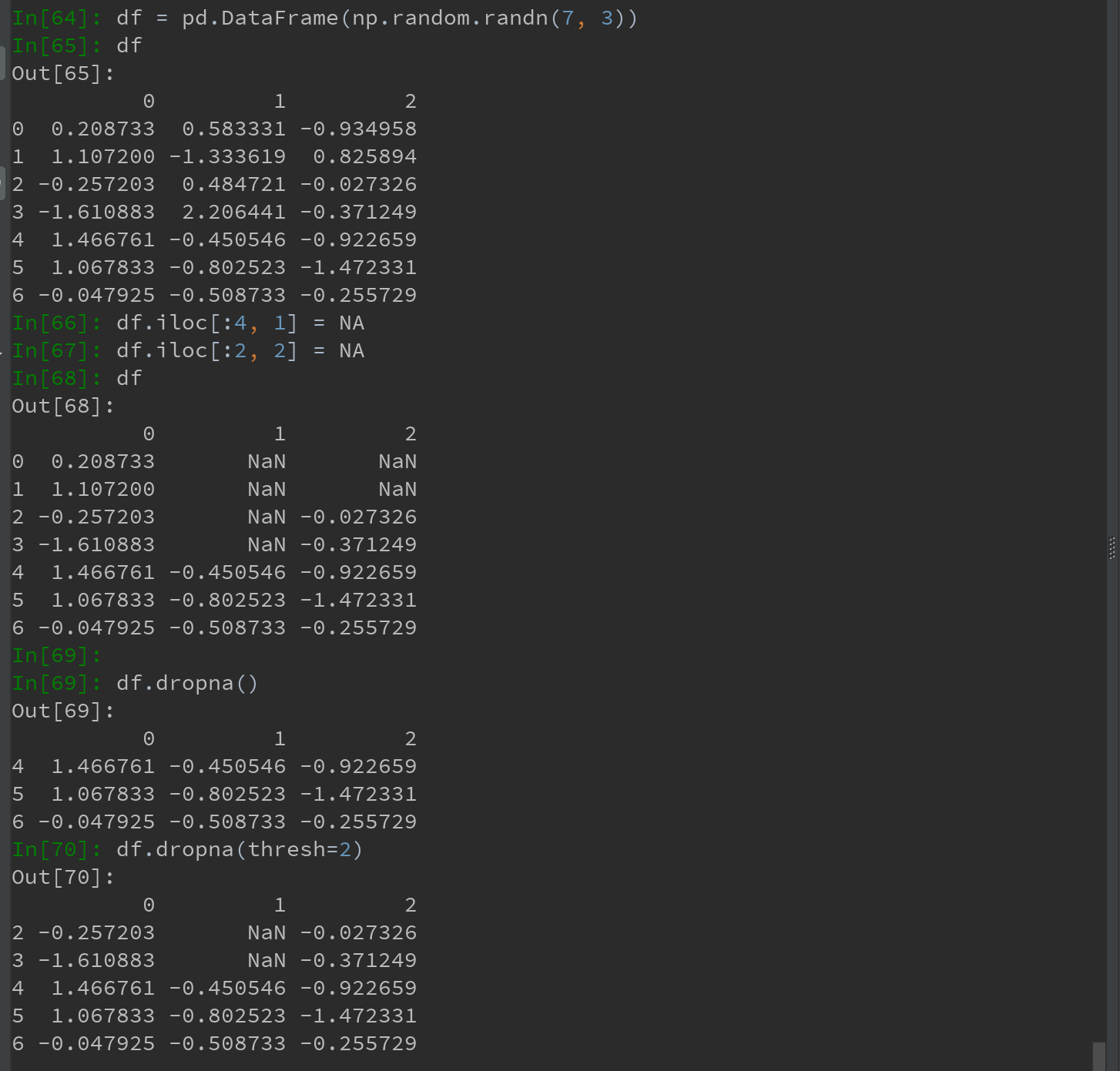
3)另一个滤除DataFrame行的问题涉及时间序列数据。假设需要留下一部分观测数据,可用 thresh=N 参数实现此目的(丢弃前N行含有NA的行,对于列如何处理???):
7.1.2 填充缺失数据
如果不想滤除缺失数据,而是希望通过其他方式填补哪些缺失数据,则fillna方法是最主要的函数。通过一个常数调用fillna就会将缺失值替换为该常数:
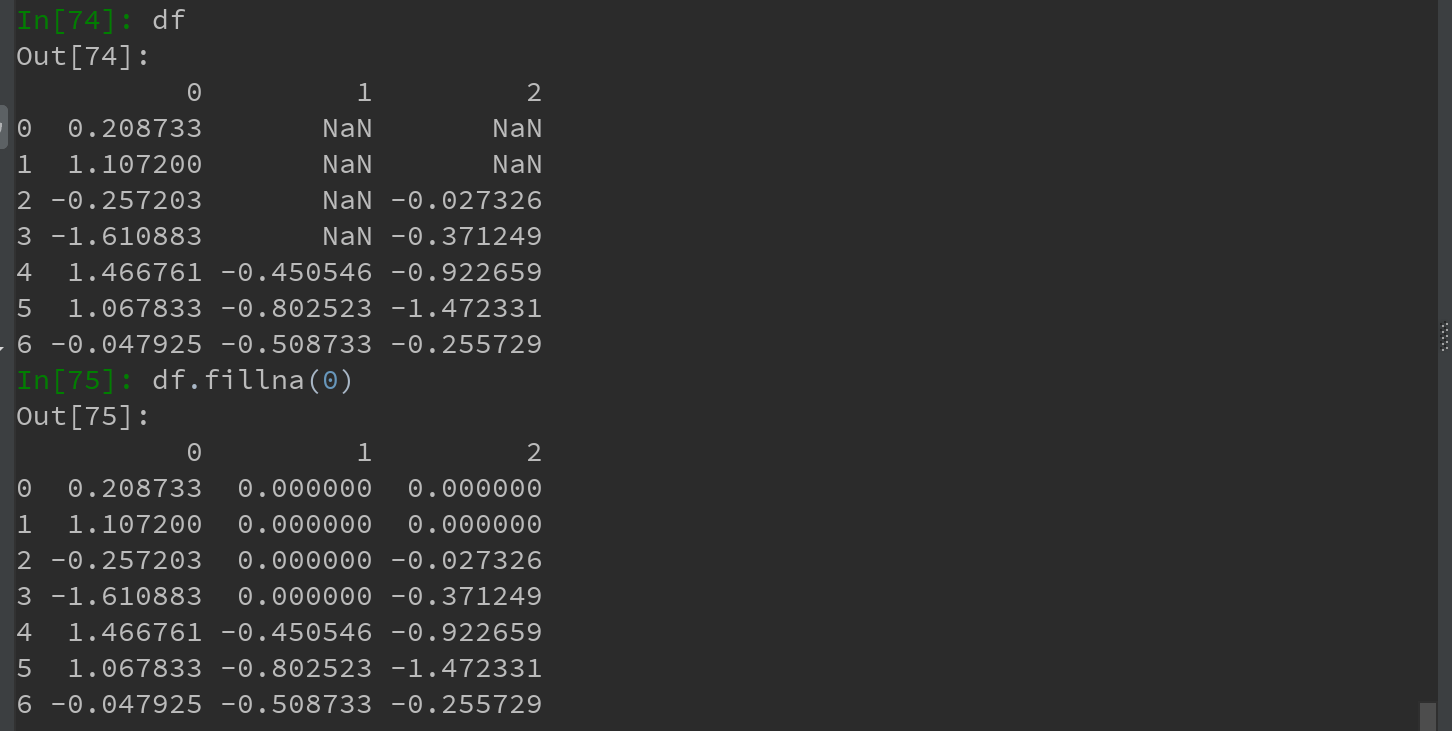
通过一个字典调用fillna,可实现对不同列填充不同的值:
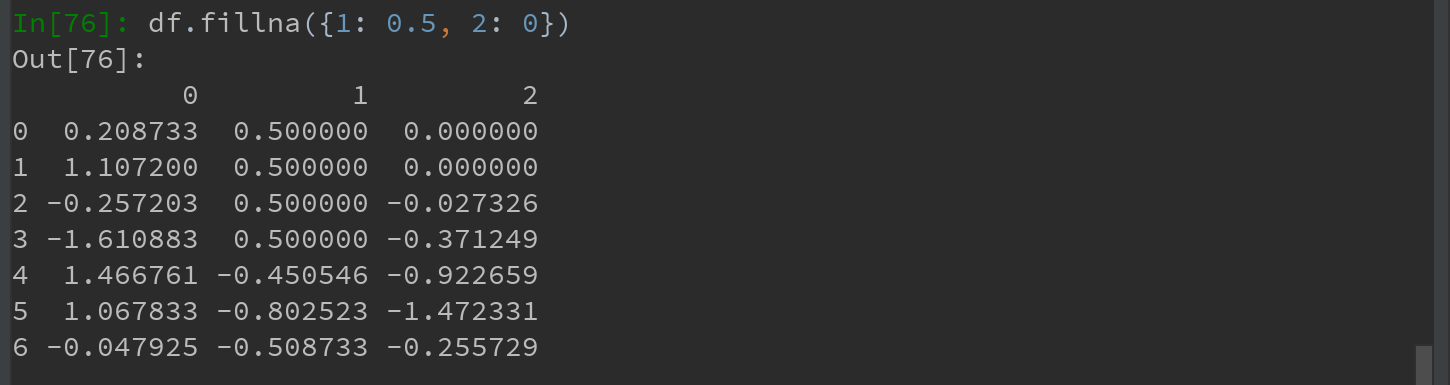
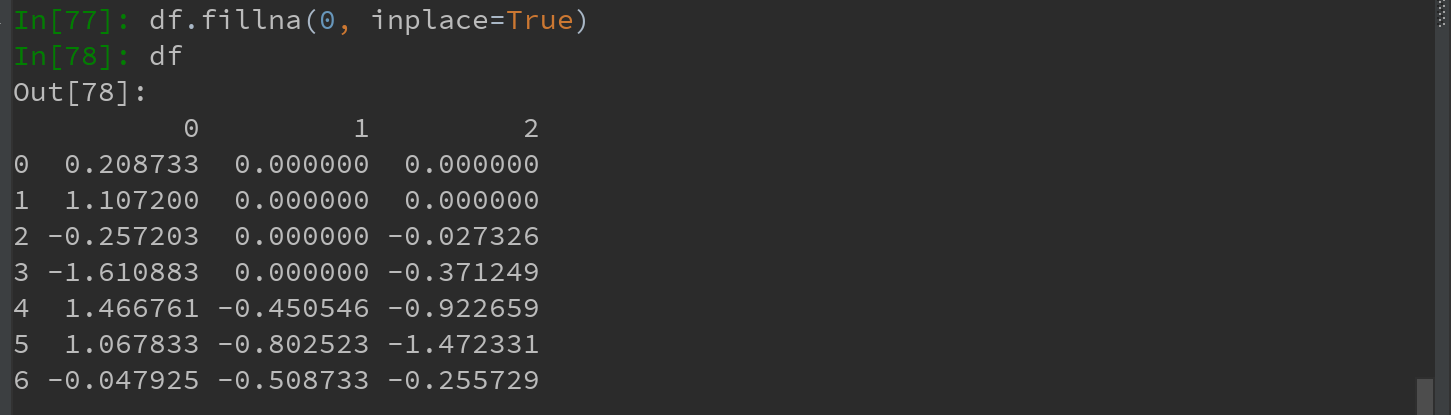
fillna默认会返回新对象,如果想对现有对象进行就地修改,则可以通过传入 inplace = True实现:
对reindex(书中为reindexing,是否有误?)有效的插值方法,同样适用于fillna:

Ps:还可以创新的用fillna实现许多别的功能,比如,传入Series的平均值或中位数:
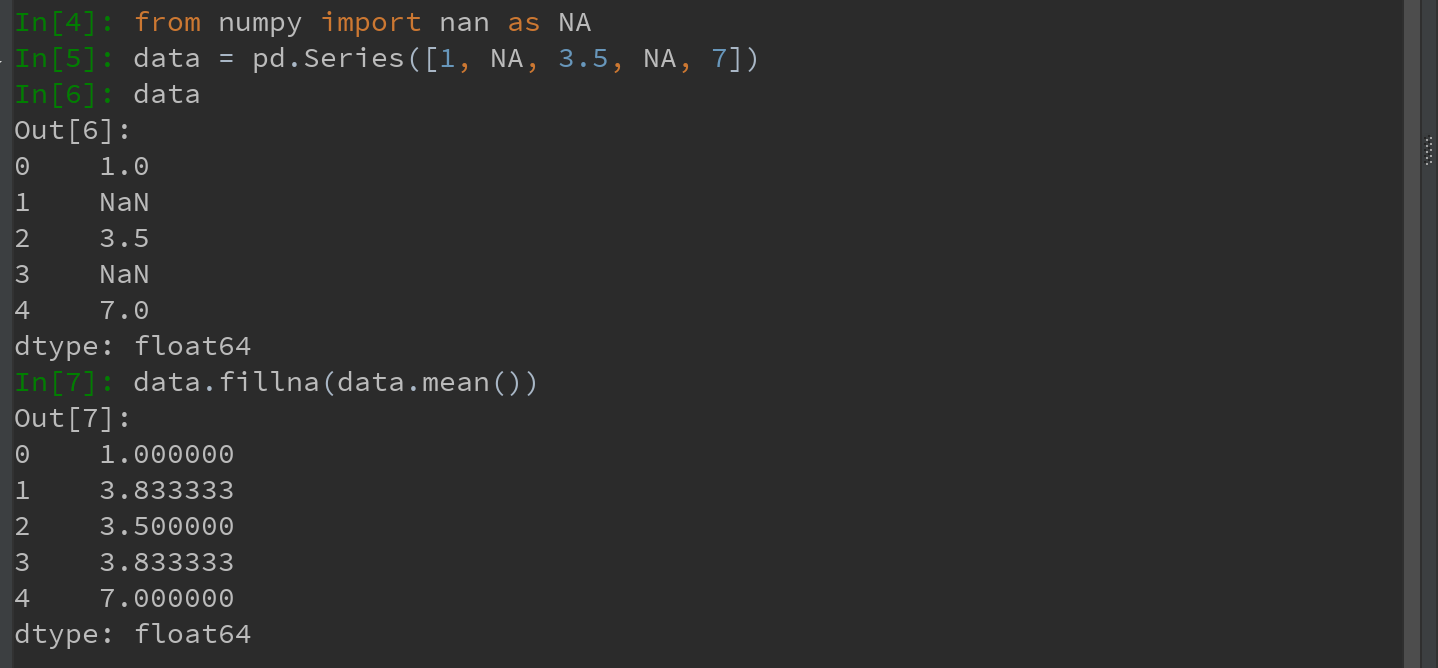
注意:在使用NA之前,一定要先从numpy中导入nan命名为NA
表7-2 fillna的参考

7.2 数据转换
本章截至目前,均介绍的是数据的重排。另一类重要操作则是过滤、清理以及其他的转换工作。
7.2.1 移除重复数据
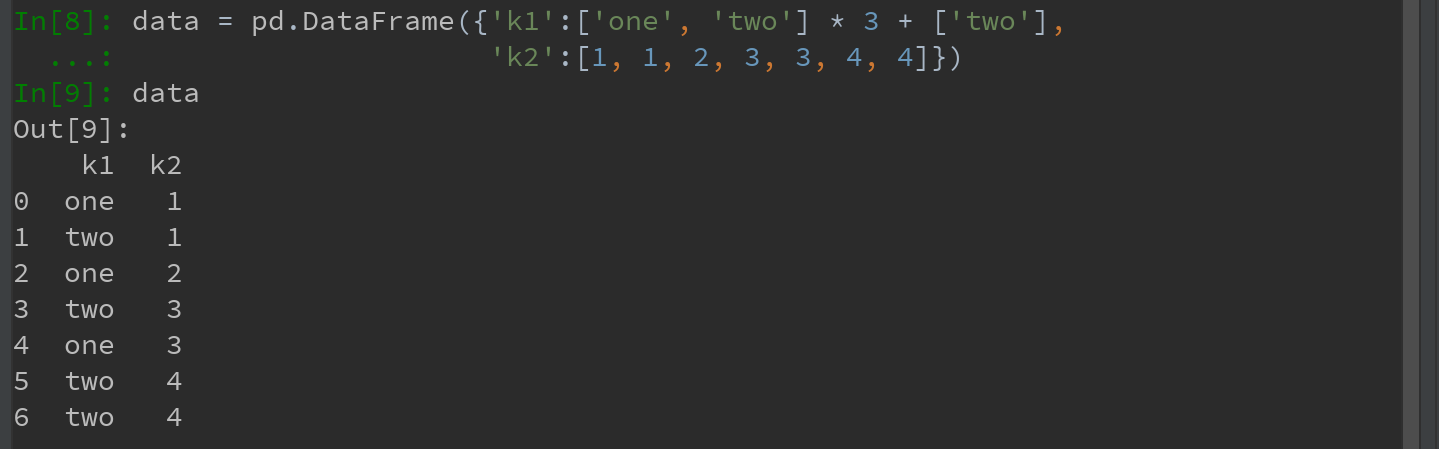
DataFrame中出现重复行
DataFrame的duplicated方法返回一个布尔类型Series,表示各行是否是重复行(前面出现过的行):

DataFrame的drop_duplicates方法,则会返回一个DataFrame:

Ps:上述两个方法,默认会判断全部列,也可以制定部分列进行重复判断。
若只希望根据指定列进行过滤重复项的操作:
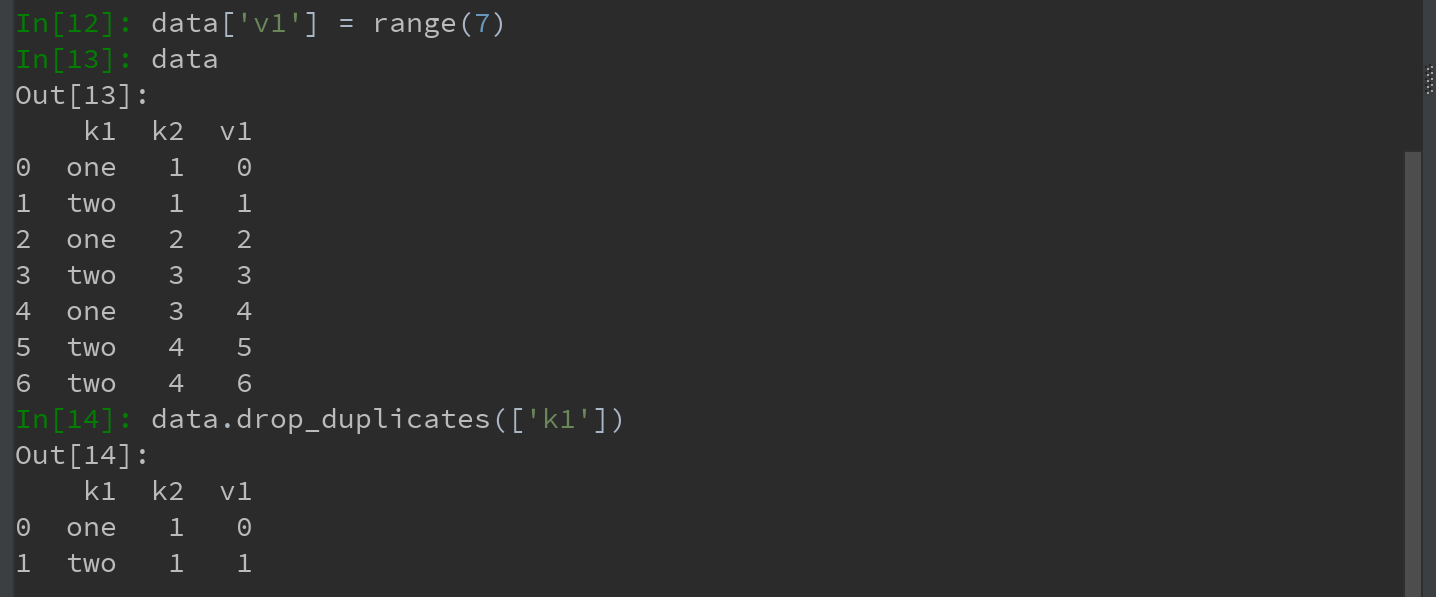
duplicated和drop_duplicates默认保留的是第一个出现的值的组合。传入keep='last'则保留最后一个:

7.2.2 利用函数或映射进行数据转换
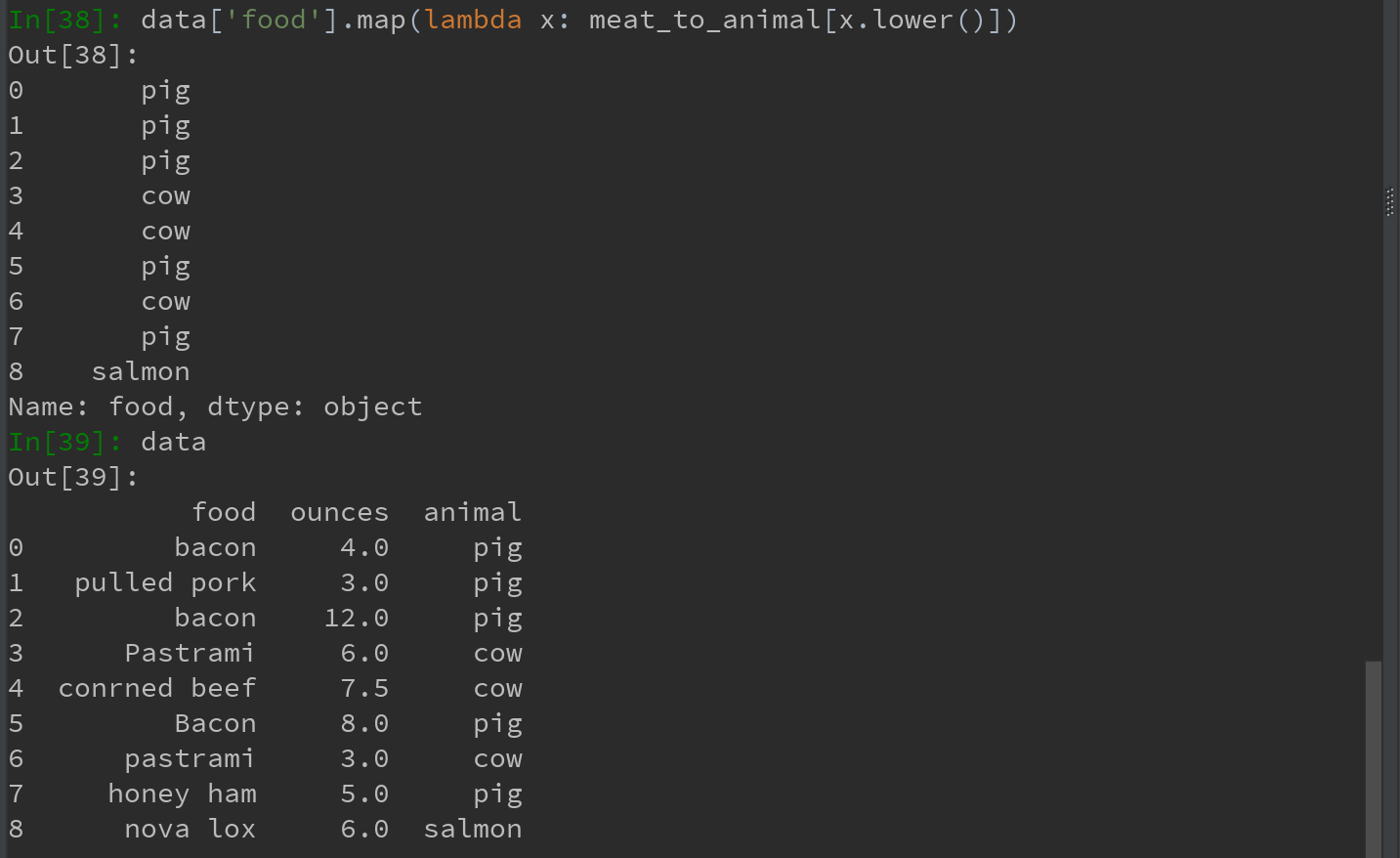
对许多数据集,可能希望根据数组、Series或DataFrame列中的值来实现转换工作。如下数据:
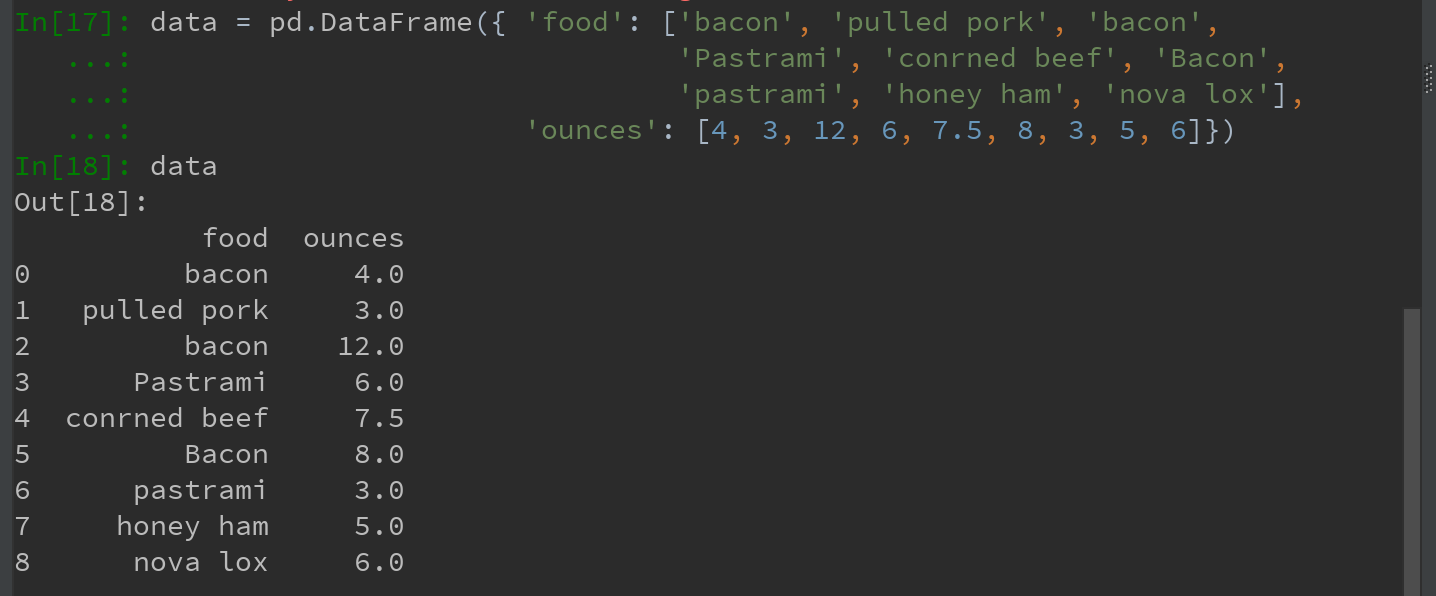
若希望添加一列表示该肉类食物的动物类型,现有如下不同肉类到动物的映射:
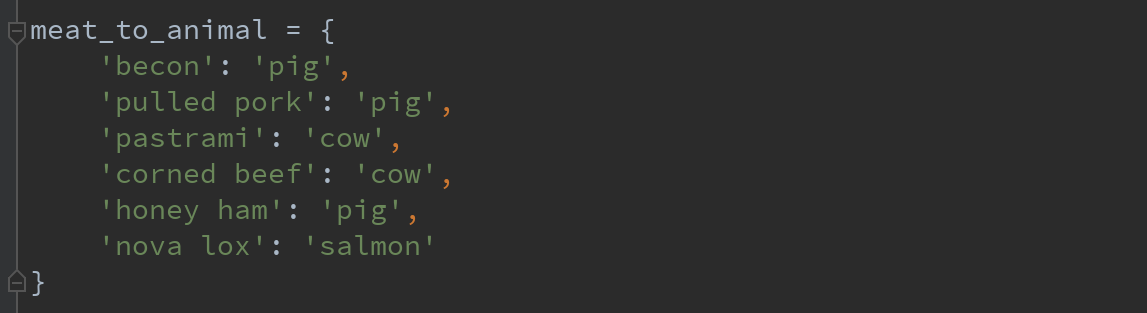
Series的map方法可以接受一个函数或含有映射关系的字典型对象。
先将数据中的大写转换为小写,可以使用Series的str.lower方法。
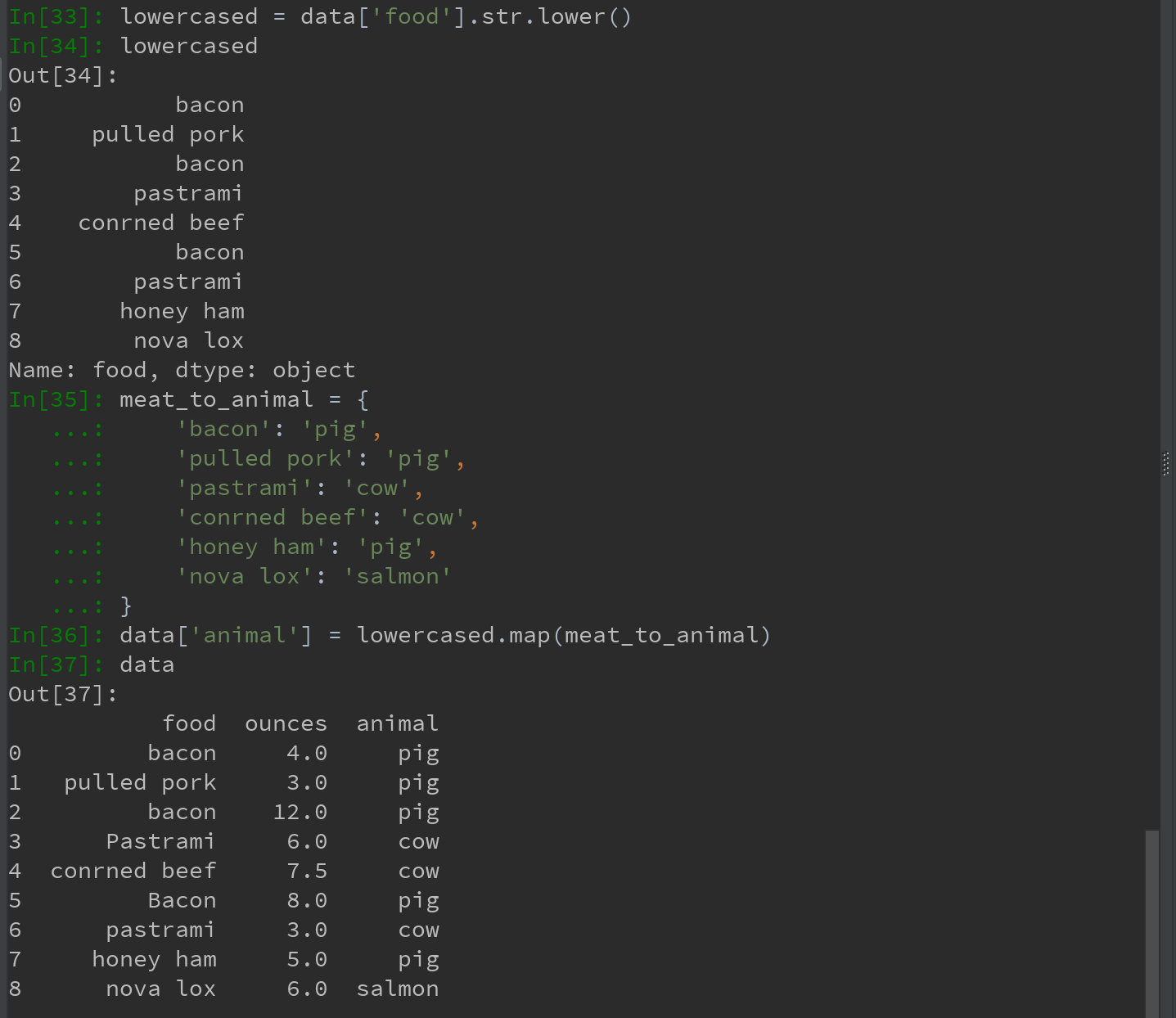
也可以传入一个能够完成全部这些工作的函数:
7.2.3 替换值
利用fillna方法填充缺失数据,可以看成是值替换的一种特殊情况。
map可用于修改对象的数据子集,而replace提供了一种实现值替换功能更简单、更灵活的方式。
对于Series:
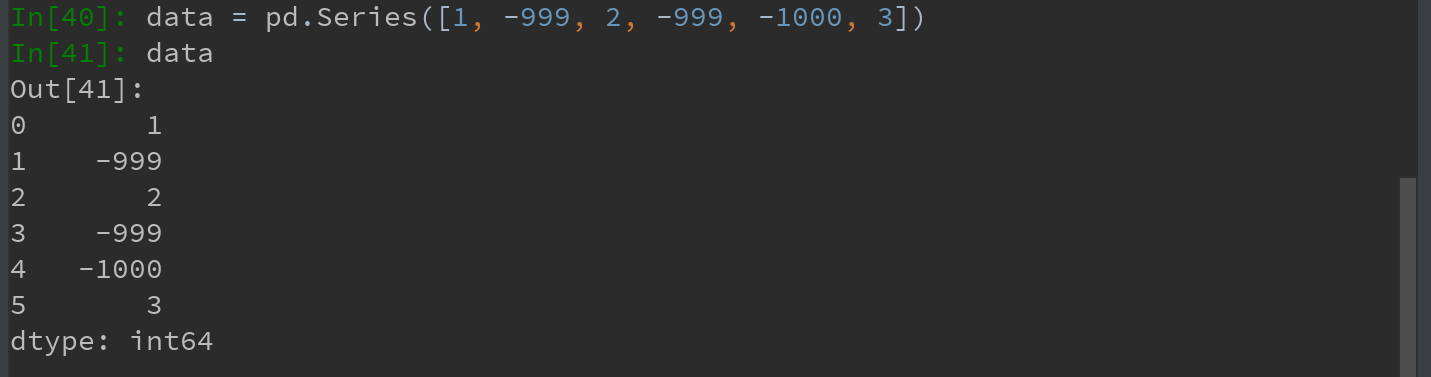
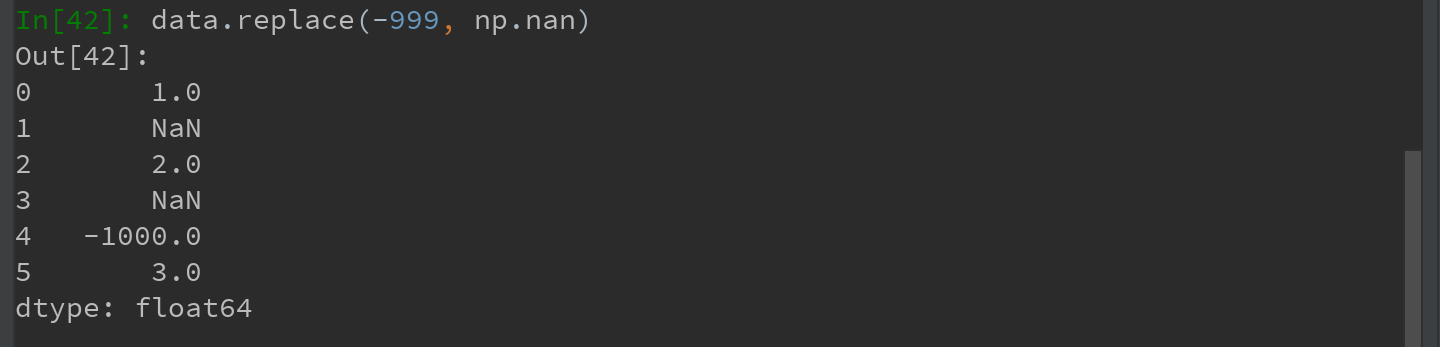
-999可能是一个表示缺失数据的标记值。需要将其替换为pandas能够理解的NA值,则可用replace来产生一个新的Series(除非传入inplace=True进行就地修改,否则生产将新的Series):
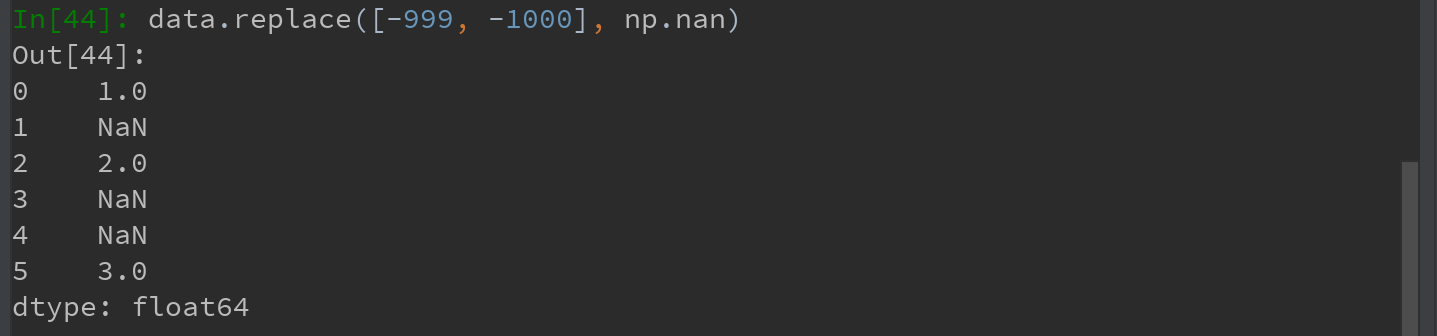
如果希望一次性替换多个值,可传入一个由待替换值组成的列表以及一个替换值:
如要让每个值有不同的替换值,可传入一个替换值列表:

Ps:传入的参数也可以是字典:
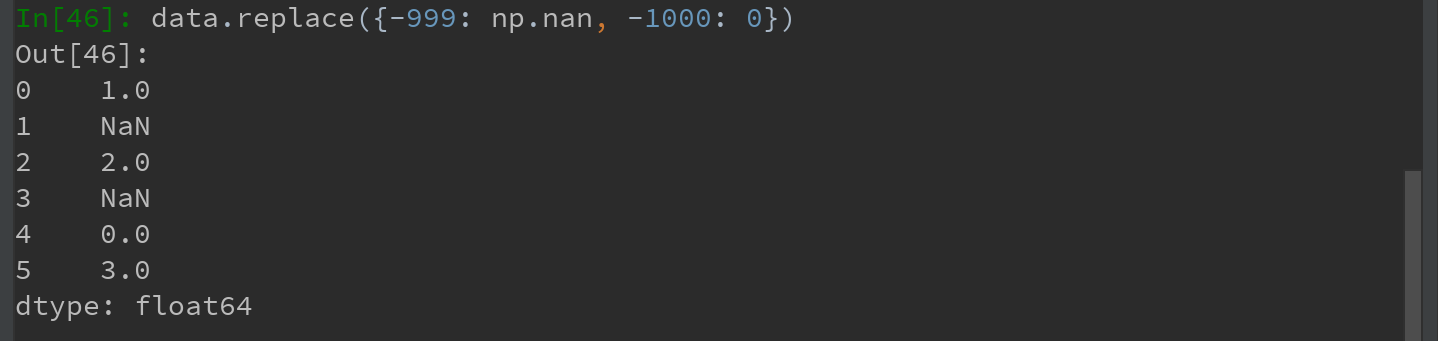
注意:data.replace方法与data.str.replace不同,后者做的是字符串的元素级替换。
7.2.4 重命名轴索引 - DataFrame
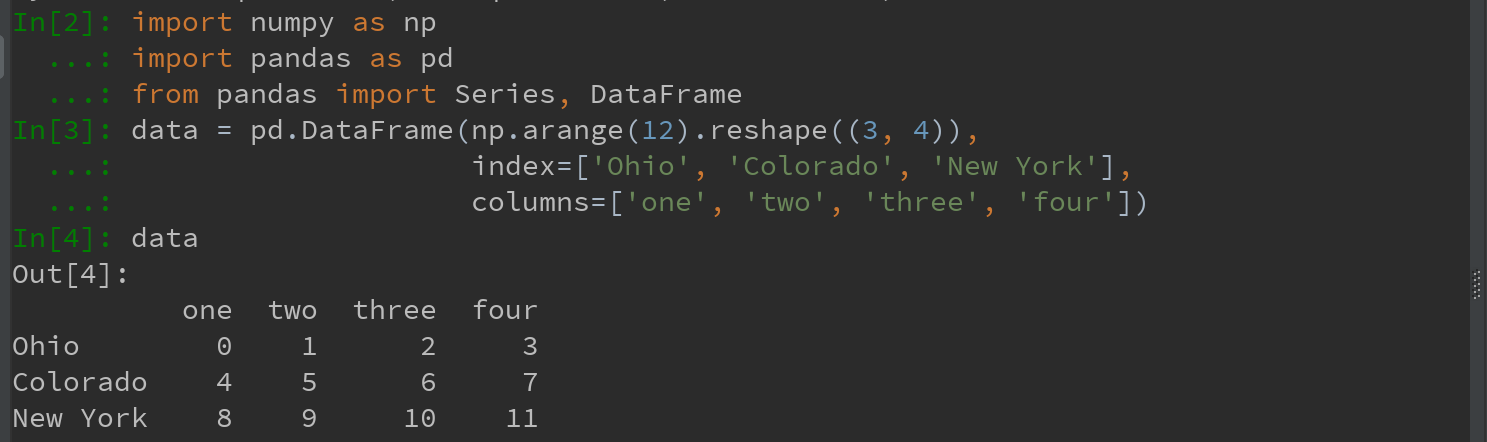
跟Series中的值一样,DataFrame轴标签也可以通过函数或映射进行转换,从而得到一个新的不同标签的对象。轴也也可以被就地修改,而无需新键一个数据结构。看例子:
跟Series一样,轴索引也有一个map方法:

将其赋值给index,就可以对DataFrame进行就地修改:

Ps:特别说明,rename可以结合字典型对象实现对部分轴标签的更新:

rename可以实现赋值DataFrame并对其索引和列标签进行赋值。如果希望就地修改某个数据库,传入inplace=True即可:

7.2.5 离散化和面元划分
为便于分析,连续数据常被离散化或拆分为“面元”(bin)。
假设有一组人员数据,希望将他们划分为不同的年龄组:

1)将这些数据划分为“18-25”、“26-35”、“36-60”及“60以上”几个面元。可以使用pandas的cut函数实现:

pandas返回的是一个特殊的Categories对象,结果展示了pandas.cut划分的面元。可将其看做一组表示面元名称的字符串。它的底层含有一个表示不同分类名称的类型数组,以及一个codes属性中的年龄数据的标签:
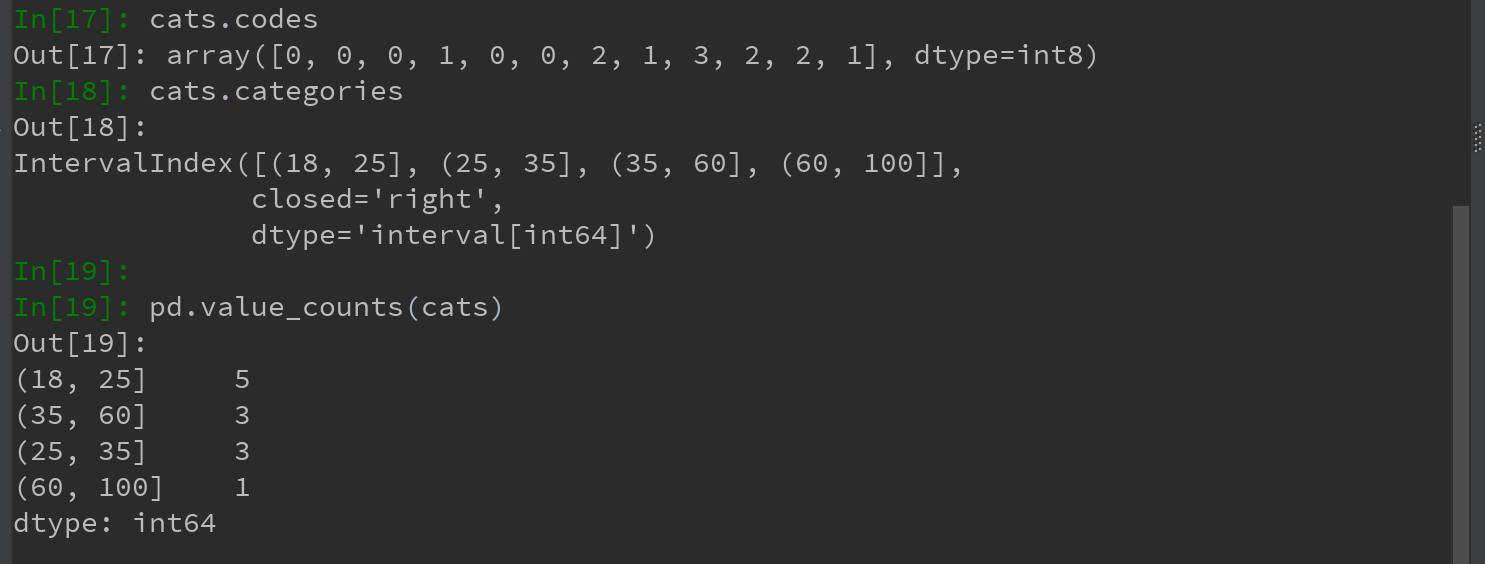
pd.value_counts(cats)是pandas.cut结果的面元计数。
2)跟“区间”的数学符合一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过right=False进行修改:

可以通过传递一个列表或数组到lables,设置自己的面元名称:

3)如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元。
如,下面的例子,将一些均匀分布的数据分成四组:
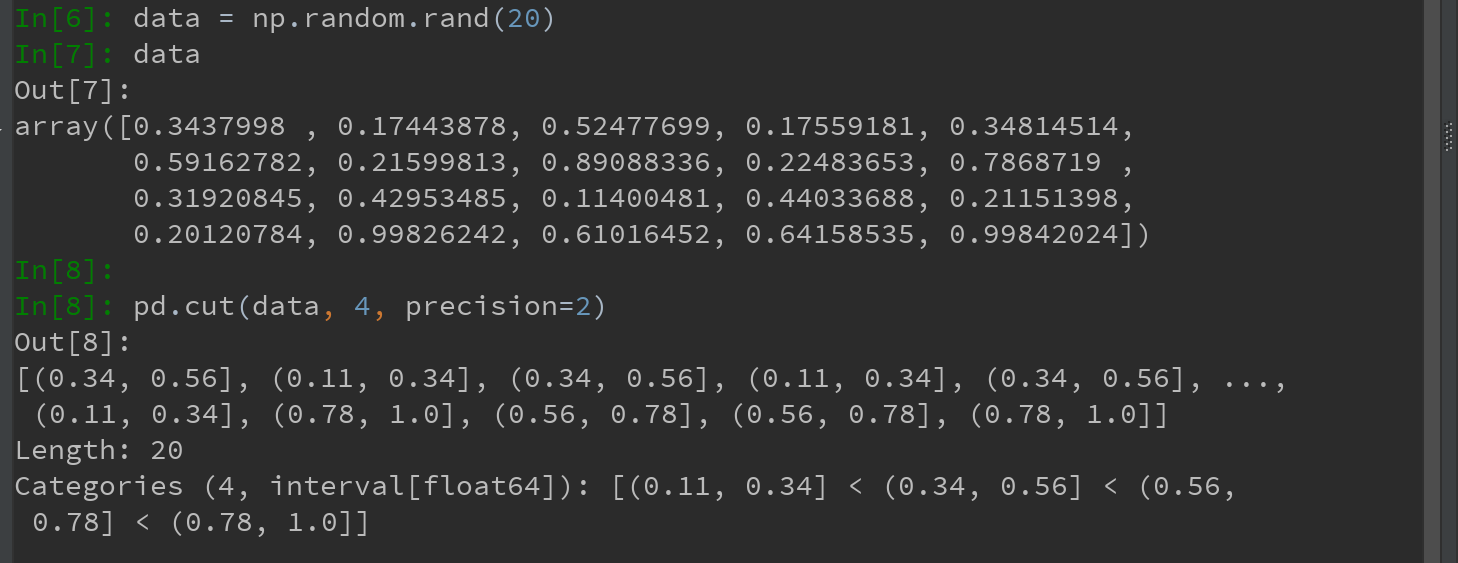
Ps:其中percision = 2,用于限定小数只取两位
4)qcut是一个非常类似于cut的函数,可以根据样本分位数对数据进行面元划分。
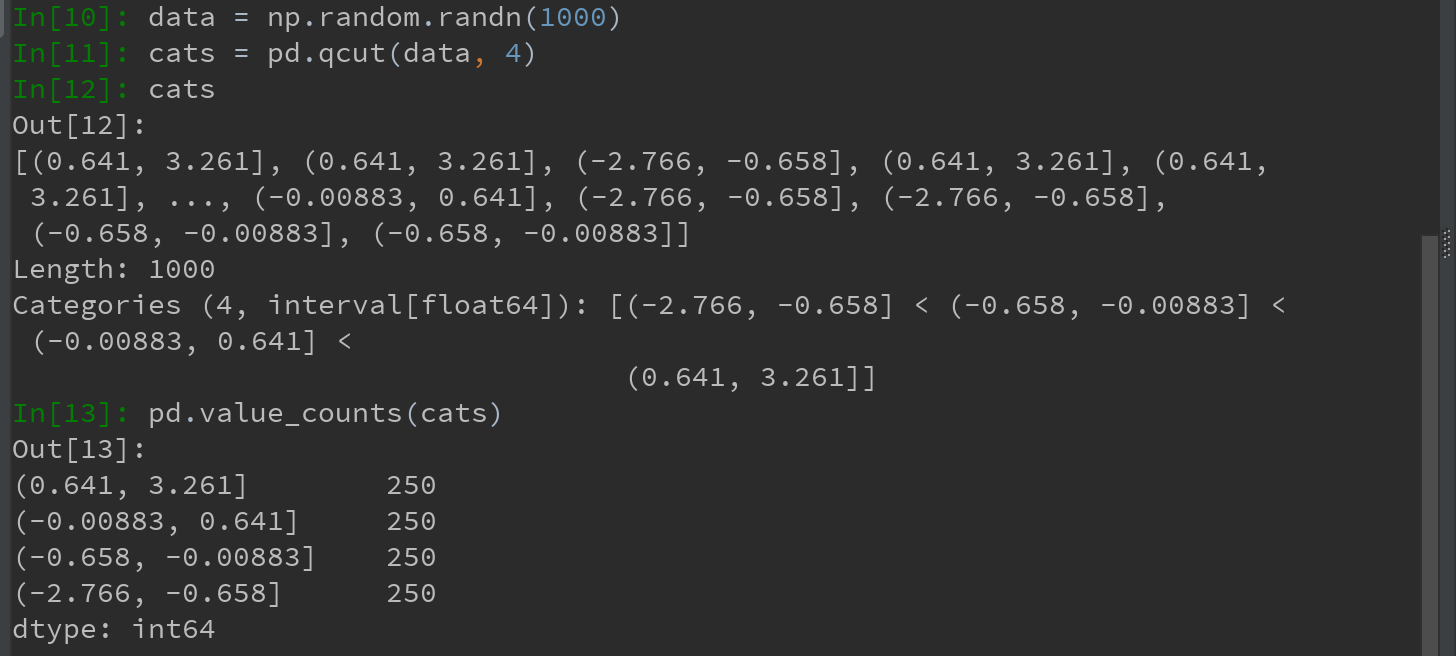
Ps:于cut类似,也可传递自定义的分位数(0到1之间的数值,包含端点):

本章稍后讲解聚合和分组运算时会再次用到cut和qcut,因为这两个离散化函数对分为和分组分析非常重要。
7.2.6 检测和过滤异常值
过滤或变换异常值(outlier)在很大程度上就是运用数组运算。
看一个含有正态分布数据的DataFrame:
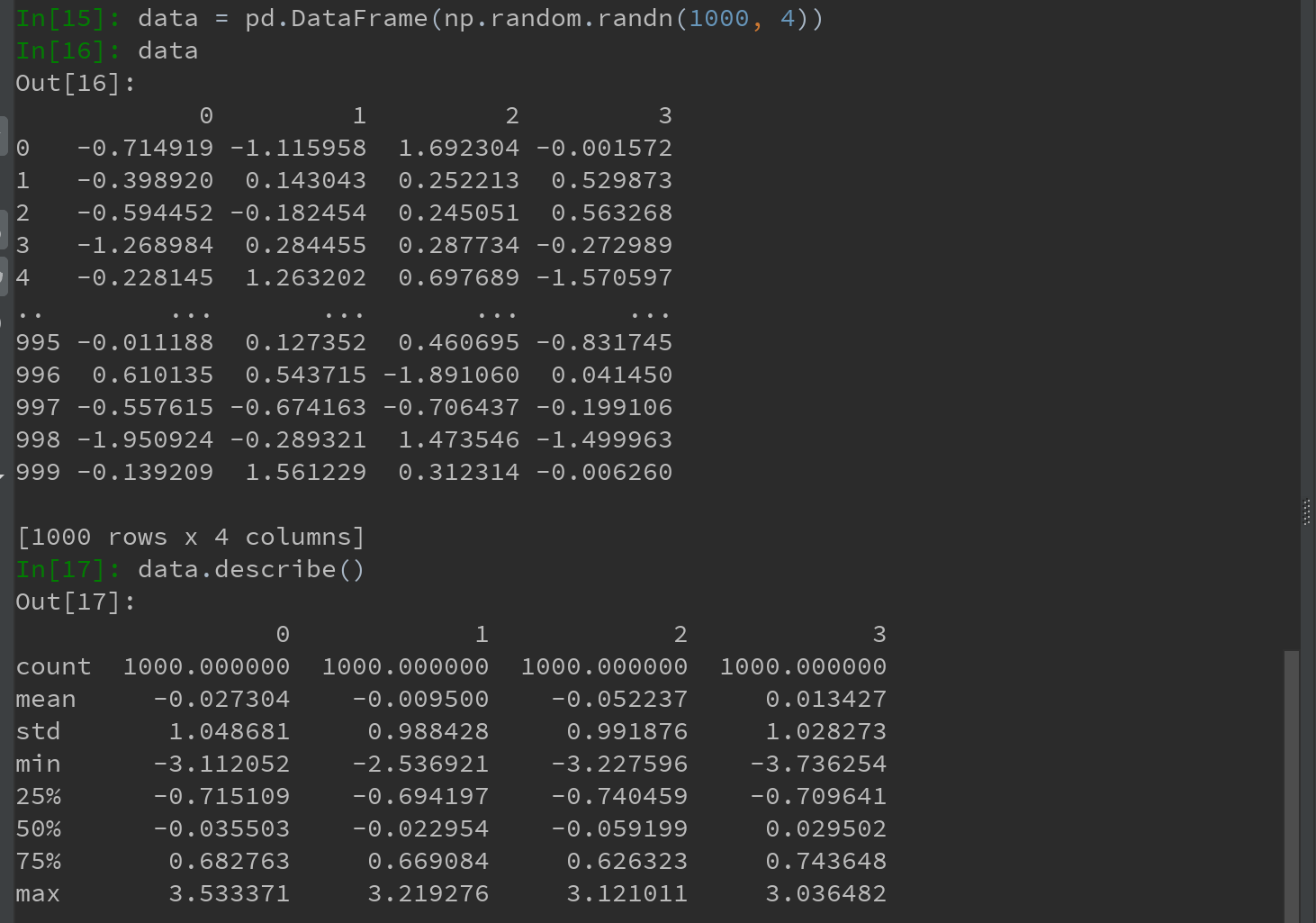
1)假设你想要找出某列中绝对值大小超过3的值:

2)要选出全部含有“超过3或-3的值”的行,可在布尔型DataFrame中使用any方法:
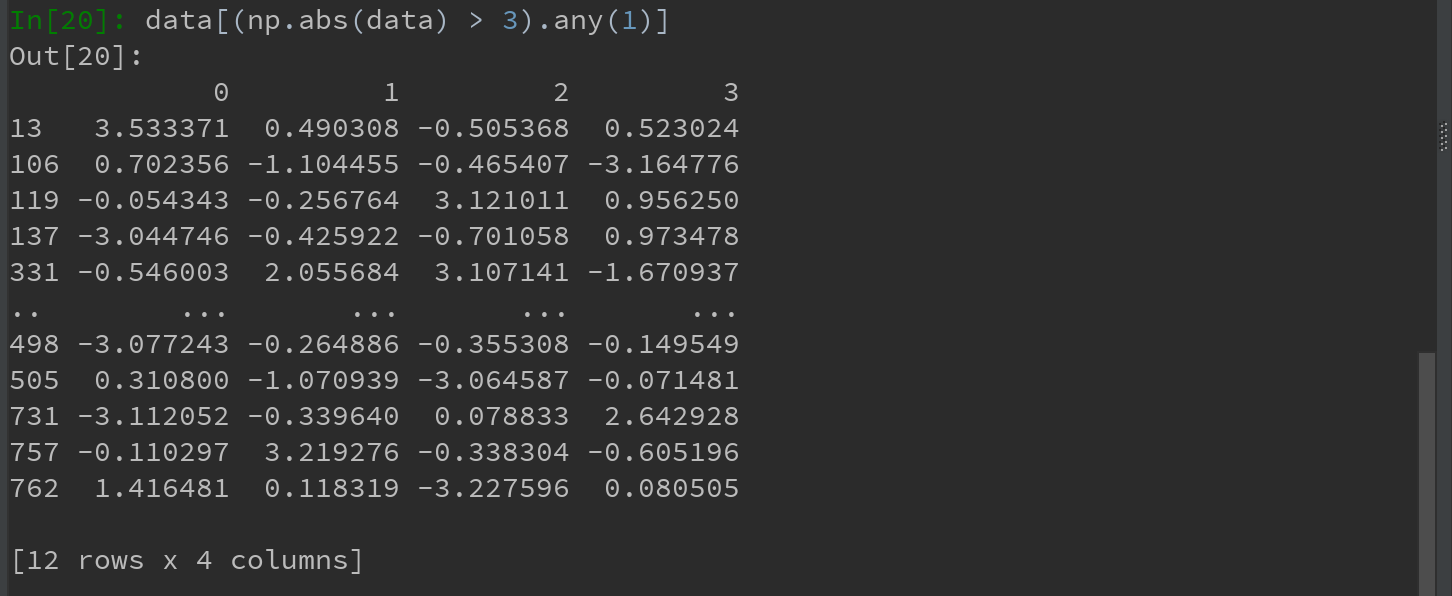
Ps:关于any函数,参考布尔型数组方法:https://www.cnblogs.com/ElonJiang/p/11624310.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.any.html
3)对值进行设置
下面的代码可将值限制在区间-3到3以内:
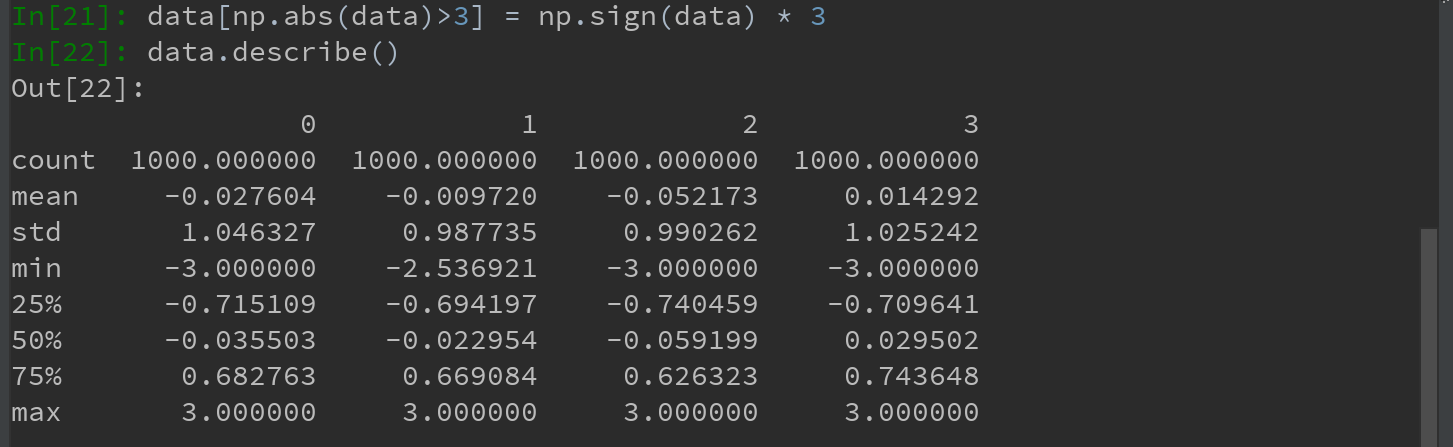
根据数值的值是正还是负,np.sign(data)可以生成1和-1:

Ps:sign()是Python的Numpy中的取数字符号(数字前的正负号)的函数
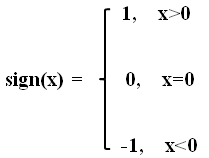
7.2.7 排列和随机采样
利用numpy.random.permutation函数可以轻松实现对Series或DataFrame的列的排列工作(permuting,随机重排序)。通过需要排列的轴的长度调用permutation,可产生一个表示新顺序的整数数组:
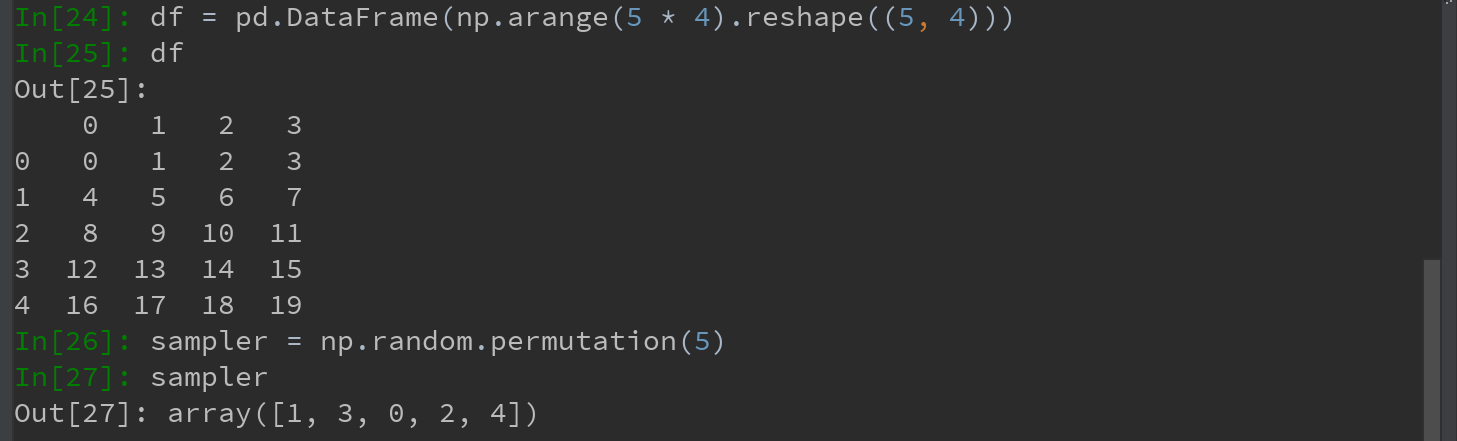
然后可以在基于iloc的索引操作或take函数中使用该数组:

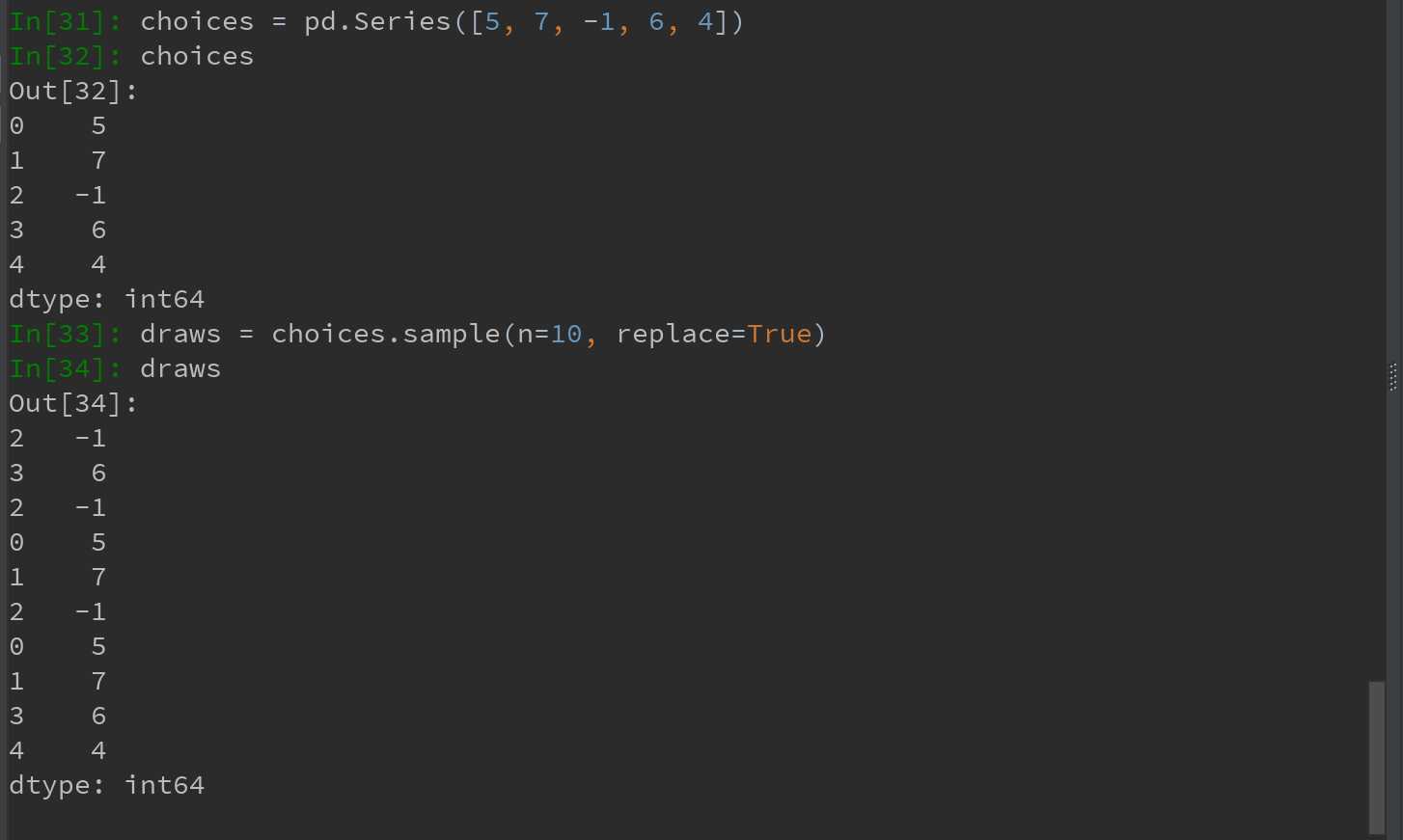
如果不想要替换的方式选取随机子集,可在Series和DataFrame上使用sample方法:

要通过替换的方式产生样本(允许重复选择),可传递replace=True到sample:
7.2.8 计算指标/哑变量
一种常用于统计建模或机器学习的转换方式:将分类变量(ategorical variable)转换薇“哑变量”或“指标矩阵”。
如果DataFrame的某一列中含有k个不同的值,则可派生出一个k列矩阵或DataFrame(其值全为1和0).
pandas有一个get_dummies函数可以实现该功能。使用如下例子:
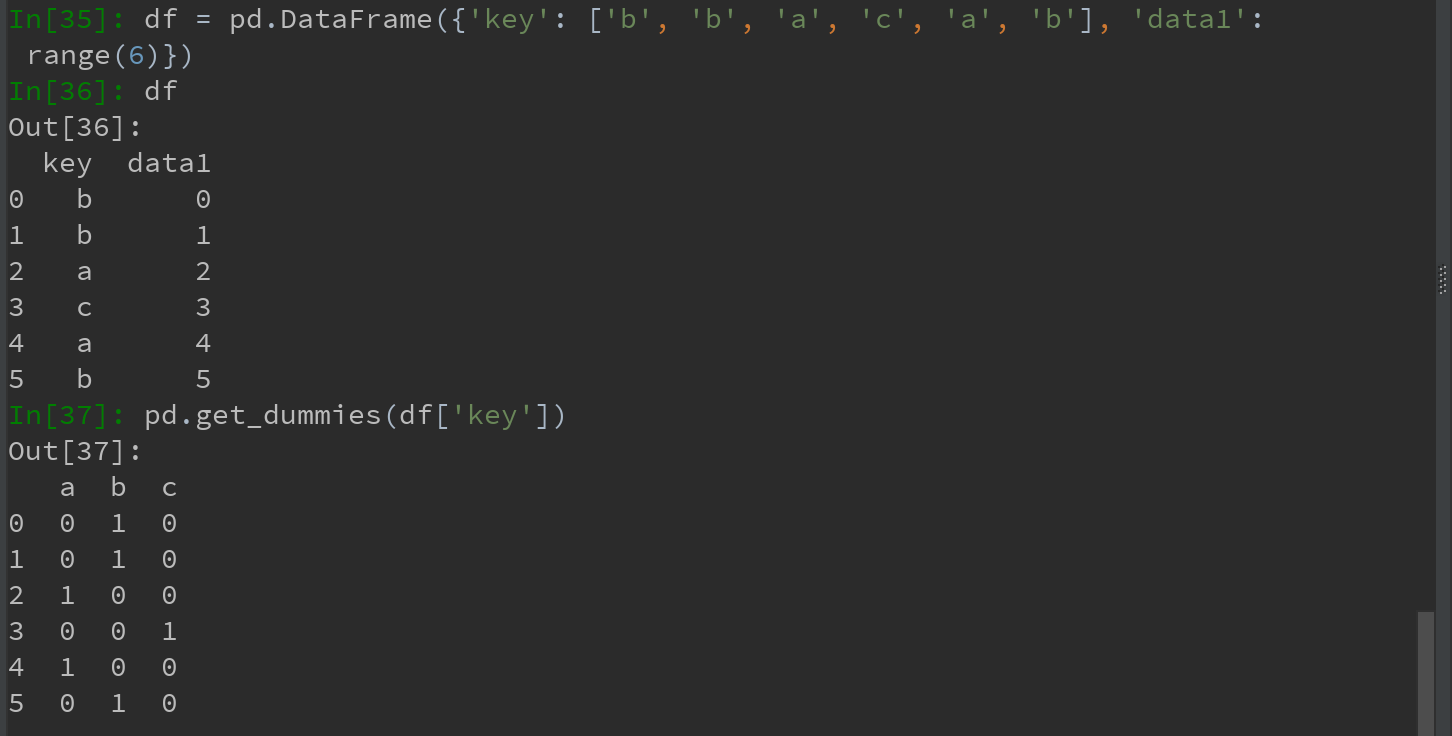
Ps:get_dumpmies方法,实现的是:对指定列中的所有不同值(去重后)在每一行中进行检索计数,有值则为‘1’,无值则为‘0’。故,派生得到的新DataFrame,其行数同原始DataFrame,其列数则有指定的列中不同值个数决定。
若想给指标DataFrame的列加上一个前缀,以便能够跟其他数据进行合并。则可使用get_dummies的prefix参数实现:
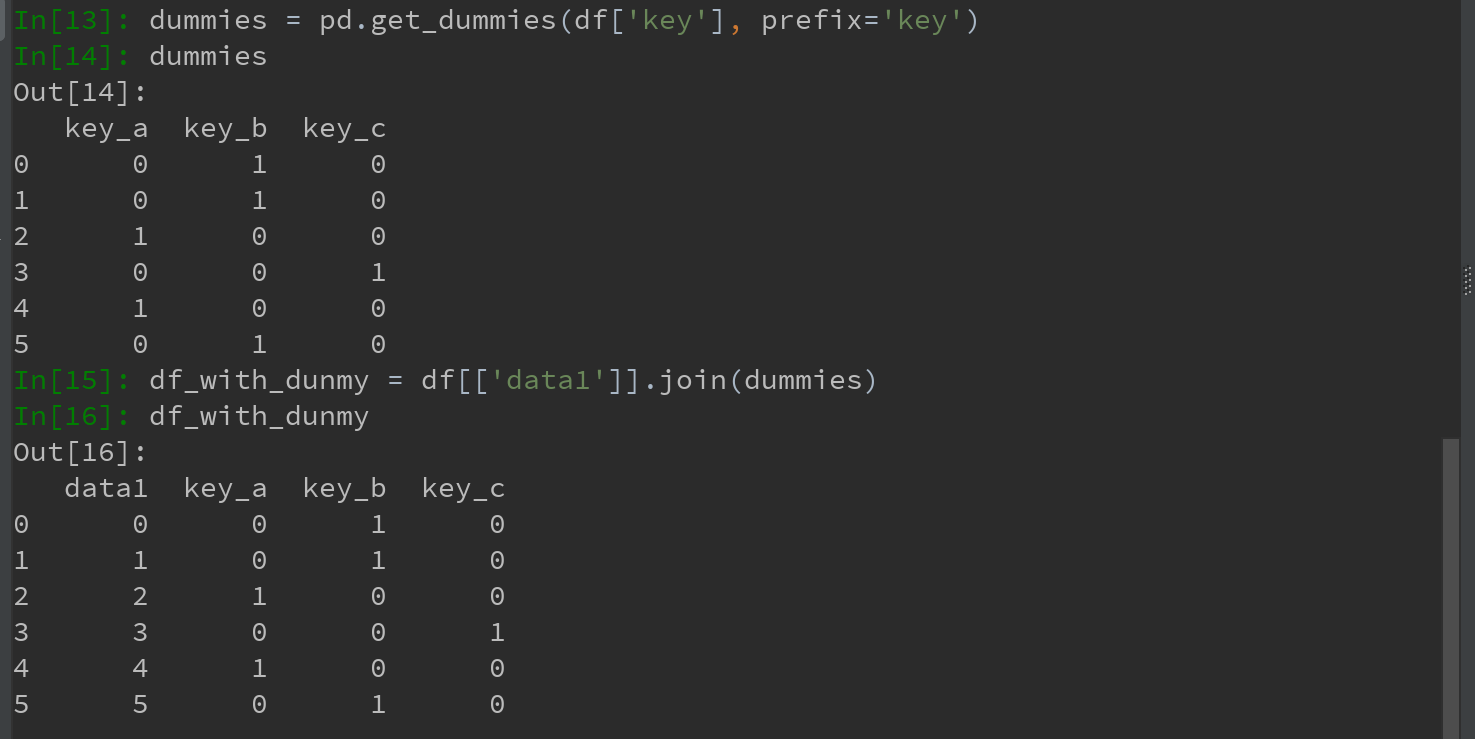
Ps:这块的df_with_dunmy操作,未搞明白???
电影数据处理例子,暂无数据,暂不学习
统计应用的一个实用秘诀:结合get_dummies和诸如cut之类的离散化函数:
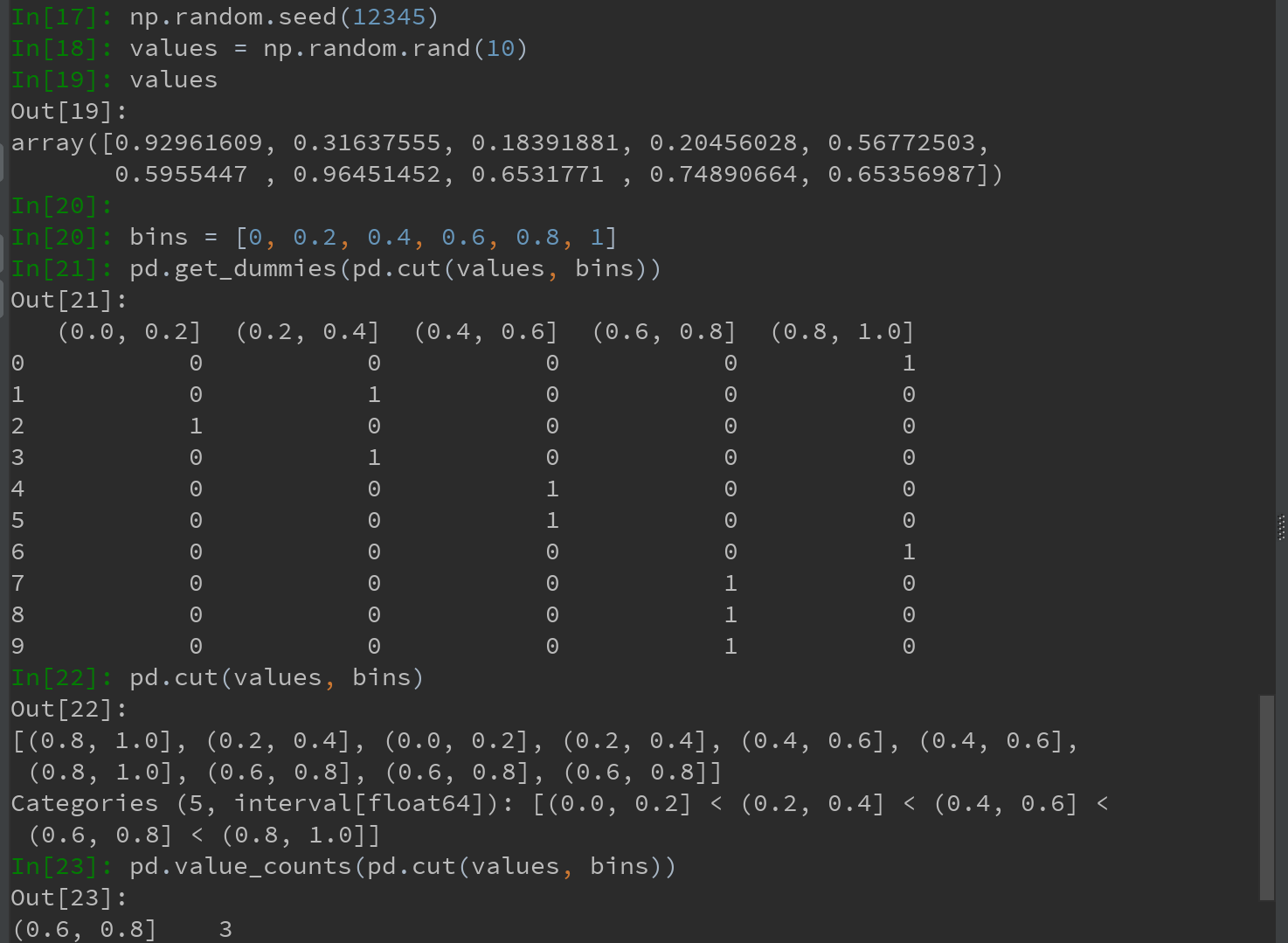
Ps:本例中使用np.random.seed,是为了使例子具有确定性。
np.random.seed()函数可以保证生成的随机数具有可预测性。可以使多次生成的随机数相同:
1.如果使用相同的seed( )值,则每次生成的随即数都相同;
2.如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
在机器学习和深度学习中,如果要保证部分参数(比如W权重参数)的随机初始化值相同,可以采用这种方式来实现。
利用Python进行数据分析 第7章 数据清洗和准备(1)的更多相关文章
- 利用Python进行数据分析 第7章 数据清洗和准备(2)
7.3 字符串操作 pandas加强了Python的字符串和文本处理功能,使得能够对整组数据应用字符串表达式和正则表达式,且能够处理烦人的缺失数据. 7.3.1 字符串对象方法 对于许多字符串处理和脚 ...
- 利用Python进行数据分析 第4章 IPython的安装与使用简述
本篇开始,结合前面所学的Python基础,开始进行实战学习.学习书目为<利用Python进行数据分析>韦斯-麦金尼 著. 之前跳过本书的前述基础部分(因为跟之前所学的<Python基 ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数 通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数. 1)一元(unary)ufunc,如,sqrt和exp函数 2)二元(unary) ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 利用Python进行数据分析 第5章 pandas入门(2)
5.2 基本功能 (1)重新索引 - 方法reindex 方法reindex是pandas对象地一个重要方法,其作用是:创建一个新对象,它地数据符合新地索引. 如,对下面的Series数据按新索引进行 ...
- 利用Python进行数据分析 第5章 pandas入门(1)
pandas库,含有使数据清洗和分析工作变得更快更简单的数据结构和操作工具.pandas是基于NumPy数组构建. pandas常结合数值计算工具NumPy和SciPy.分析库statsmodels和 ...
- 《利用python进行数据分析》读书笔记 --第一、二章 准备与例子
http://www.cnblogs.com/batteryhp/p/4868348.html 第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得 ...
- 《利用Python进行数据分析·第2版》第四章 Numpy基础:数组和矢量计算
<利用Python进行数据分析·第2版>第四章 Numpy基础:数组和矢量计算 numpy高效处理大数组的数据原因: numpy是在一个连续的内存块中存储数据,独立于其他python内置对 ...
随机推荐
- mysql group by 报错 ,only_full_group_by 三种解决方案
报错信息 Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'data ...
- Git的使用(4) —— 分支的概念和使用
1. 概念 在SVN中,分支并不是很便于使用.但是在Git中,分支就变成了特别好用的功能呢,受到大多数使用者的青睐. 分支中有几个概念: (1) 分支:分支就是每一次提交创建的点连接成的线. (2) ...
- sql查询性能调试,用SET STATISTICS IO和SET STATISTICS TIME---解释比较详细
一个查询需要的CPU.IO资源越多,查询运行的速度就越慢,因此,描述查询性能调节任务的另一种方式是,应该以一种使用更少的CPU.IO资源的方式重写查询命令,如果能够以这样一种方式完成查 ...
- Java初级黄金体验 其二
Java初级黄金体验 其二 引言:让我们看一下你的C盘有多少个文件和文件夹 初级 Java IO : 第一个纪念碑 小程序大致功能 让我们看一下E盘有多少个文件 上代码 最近太多的作业 代码可以无限改 ...
- [Web前端] WEEX、React-Native开发App心得 (转载)
转自: https://www.jianshu.com/p/139c5074ae5d 2018 JS状态报告: https://2018.stateofjs.com/mobile-and-deskto ...
- 狼人杀面杀APP(FGUI教程)
本教程为FairyGUI进阶教程,这是一套完整的面杀桌游APP.游戏不仅有发放随机身份的功能,还涉及10个页面的切换与各页面不同状态(最多达9种状态)的切换,众多复杂UI的交互,多语言切换,3D粒子在 ...
- Linux中进程的几种状态
linux是一个多用户,多任务的系统,可以同时运行多个用户的多个程序,就必然会产生很多的进程,而每个进程会有不同的状态. Linux进程状态:R (TASK_RUNNING),可执行状态. 只有在该状 ...
- AI人工智能学习数据集
AI人工智能学习数据集,列表如下. 商务合作,科技咨询,版权转让:向日葵,135—4855__4328,xiexiaokui#qq.com boston_house_prices.csvbreast_ ...
- 基本使用——OkHttp3详细使用教程
基本使用——OkHttp3详细使用教程 转 https://blog.csdn.net/xx326664162/article/details/77714126 概述 OkHttp现在应该算是最火的H ...
- 算法习题---5-5复合词(UVa10391)
一:题目 输入一系列由小写字母组成的单词.输入已按照字典序排序,且不超过120000个.找出所有的复合词,即恰好由两个单词连接而成的单词 (一)样例输入 a alien born less lien ...