sqoop2相关实例:hdfs和mysql互相导入(转)
原文地址:http://blog.csdn.net/dream_an/article/details/74936066
超详细讲解Sqoop2应用与实践
摘要:超详细讲解Sqoop2应用与实践,从hdfs上的数据导入到postgreSQL中,再从postgreSQL数据库导入到hdfs上。详细讲解创建link和创建job的操作,以及如何查看sqoop2的工作状态。
1.准备,上一篇超详细讲解Sqoop2部署过程,Sqoop2自动部署源码
1.1.为了能查看sqoop2 status,编辑 mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>sbin/mr-jobhistory-daemon.sh start historyserver1.2.创建postgreSQL上的准备数据。创建表并填充数据-postgresql
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
INSERT INTO products (product_no, name, price) VALUES (1,'Cheese',9.99);1.3.创建hdfs上的准备数据
xiaolei@wang:~$ vim product.csv
2,'laoganma',13.5
xiaolei@wang:~$ hadoop fs -mkdir /hdfs2jdbc
xiaolei@wang:~$ hadoop fs -put product.csv /hdfs2jdbc1.3.配置sqoop2的server
sqoop:000> set server --host localhost --port 12000 --webapp sqoop- 1
1.4.启动hadoop,特别是启动historyserver,启动sqoop2
sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
sqoop2-server start1.5.如果未安装Sqoop2或者部署有问题,上一篇超详细讲解Sqoop2部署过程,Sqoop2自动部署源码
2.通过sqoop2,hdfs上的数据导入到postgreSQL
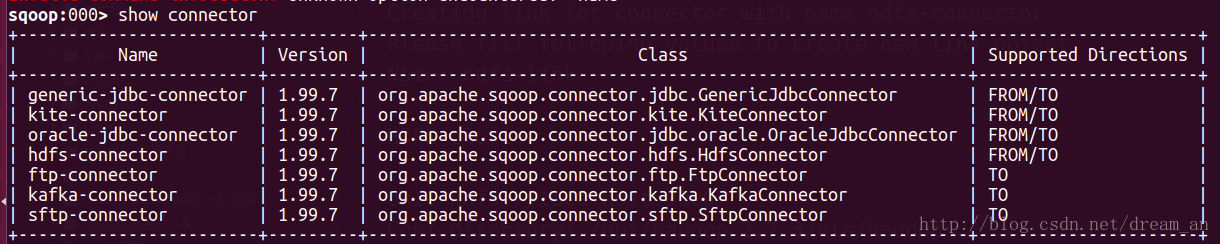
sqoop:000> show connector- 1
2.1.创建hdfs-link,注明(必填)的要写正确,其他的可以回车跳过。
sqoop:000> create link --connector hdfs-connector
Creating link for connector with name hdfs-connector
Please fill following values to create new link object
Name: hdfs-link #link名称(必填)
HDFS cluster
URI: hdfs://localhost:9000 #hdfs的地址(必填)
Conf directory: /opt/hadoop-2.7.3/etc/hadoop #hadoop的配置地址(必填)
Additional configs::
There are currently 0 values in the map:
entry#
New link was successfully created with validation status OK and name hdfs-link2.2.创建jdbc-link
sqoop:000> create link --connector generic-jdbc-connector
Creating link for connector with name generic-jdbc-connector
Please fill following values to create new link object
Name: jdbc-link #link名称(必填)
Database connection
Driver class: org.postgresql.Driver #jdbc驱动类(必填)
Connection String: jdbc:postgresql://localhost:5432/whaleaidb # jdbc链接url(必填)
Username: whaleai #数据库的用户(必填)
Password: ****** #数据库密码(必填)
Fetch Size:
Connection Properties:
There are currently 0 values in the map:
entry#
SQL Dialect
Identifier enclose:
New link was successfully created with validation status OK and name jdbc-link2.3.查看已经创建好的hdfs-link和jdbc-link
sqoop:000> show link
+----------------+------------------------+---------+
| Name | Connector Name | Enabled |
+----------------+------------------------+---------+
| jdbc-link | generic-jdbc-connector | true |
| hdfs-link | hdfs-connector | true |
+----------------+------------------------+---------+2.4.创建从hdfs导入到postgreSQL的job
sqoop:000> create job -f hdfs-link -t jdbc-link
Creating job for links with from name hdfs-link and to name jdbc-link
Please fill following values to create new job object
Name: hdfs2jdbc #job 名称(必填)
Input configuration
Input directory: /hdfs2jdbc #hdfs的输入路径 (必填)
Override null value:
Null value:
Incremental import
Incremental type:
0 : NONE
1 : NEW_FILES
Choose: 0 (必填)
Last imported date:
Database target
Schema name: public #postgreSQL默认的public(必填)
Table name: products #要导入的数据库表(必填)
Column names:
There are currently 0 values in the list:
element#
Staging table:
Clear stage table:
Throttling resources
Incremental type:
0 : NONE
1 : NEW_FILES
Choose: 0 #(必填)
Last imported date:
Throttling resources
Extractors:
Loaders:
Classpath configuration
Extra mapper jars:
There are currently 0 values in the list:
element#
New job was successfully created with validation status OK and name hdfs2jdbc2.5.启动 hdfs2jdbc job
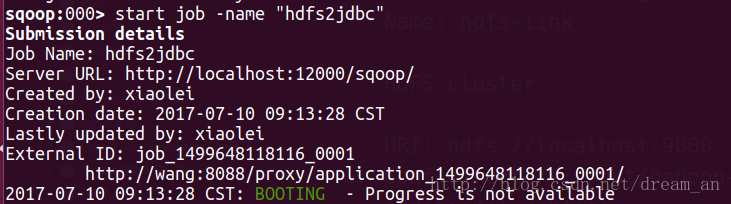
sqoop:000> start job -name "hdfs2jdbc"- 1
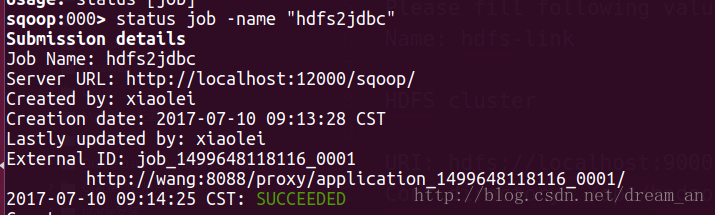
2.6.查看job执行状态,成功。
sqoop:000> status job -name "hdfs2jdbc"- 1
3.通过sqoop2,postgreSQL上的数据导入到hdfs上
3.1.因为所需的link在第2部分已经,这里只需创建从postgreSQL导入到hdfs上的job。
sqoop:000> create job -f jdbc-link -t hdfs-link
Creating job for links with from name jdbc-link and to name hdfs-link
Please fill following values to create new job object
Name: jdbc2hdfs #job 名称(必填)
Database source
Schema name: public #postgreSQL默认的为public(必填)
Table name: products #数据源 数据库的表(必填)
SQL statement:
Column names:
There are currently 0 values in the list:
element#
Partition column:
Partition column nullable:
Boundary query:
Incremental read
Check column:
Last value:
Target configuration
Override null value:
Null value:
File format:
0 : TEXT_FILE
1 : SEQUENCE_FILE
2 : PARQUET_FILE
Choose: 0 #(必填)
Compression codec:
0 : NONE
1 : DEFAULT
2 : DEFLATE
3 : GZIP
4 : BZIP2
5 : LZO
6 : LZ4
7 : SNAPPY
8 : CUSTOM
Choose: 0 #(必填)
Custom codec:
Output directory: /jdbc2hdfs #hdfs上的输出路径(必填)
Append mode:
Throttling resources
Extractors:
Loaders:
Classpath configuration
Extra mapper jars:
There are currently 0 values in the list:
element#
New job was successfully created with validation status OK and name jdbc2hdfs3.2. 启动jdbc2hdfs job
sqoop:000> start job -name "jdbc2hdfs"
Submission details
Job Name: jdbc2hdfs
Server URL: http://localhost:12000/sqoop/
Created by: xiaolei
Creation date: 2017-07-10 09:26:42 CST
Lastly updated by: xiaolei
External ID: job_1499648118116_0002
http://wang:8088/proxy/application_1499648118116_0002/
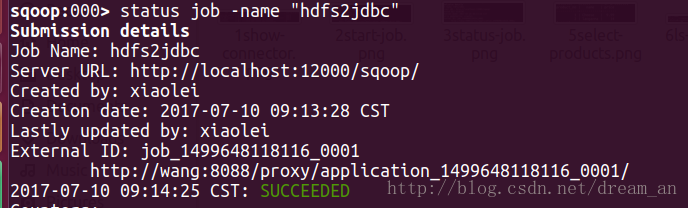
2017-07-10 09:26:42 CST: BOOTING - Progress is not available3.3.查看job执行状态,成功。
sqoop:000> status job -name "jdbc2hdfs"- 1
3.4.查看hdfs上的数据已经存在
xiaolei@wang:~$ hadoop fs -ls /jdbc2hdfs
Found 1 items
-rw-r--r-- 1 xiaolei supergroup 30 2017-07-10 09:26 /jdbc2hdfs/4d2e5754-c587-4fcd-b1db-ca64fa545515.txt3.5.通过web UI,可见两次执行的job都已成功 http://localhost:8088/cluster
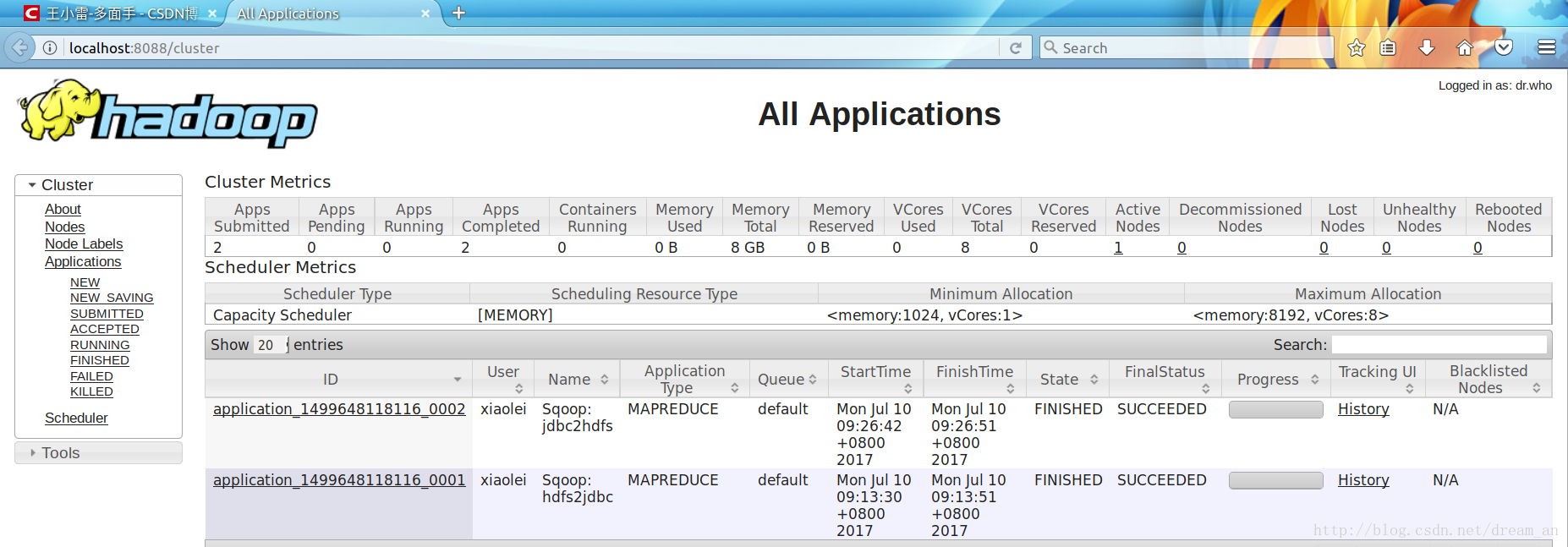
上一篇超详细讲解Sqoop2部署过程,Sqoop2自动部署源码
完结-彩蛋
1.踩坑
sqoop:000> stop job -name joba
Exception has occurred during processing command
Exception: org.apache.sqoop.common.SqoopException Message: MAPREDUCE_0003:Can’t get RunningJob instance -
解决: 编辑 mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>2.踩坑
sbin/mr-jobhistory-daemon.sh start historyserver### Exception: org.apache.sqoop.common.SqoopException Message: GENERIC_JDBC_CONNECTOR_0001:Unable to get a connection -
解决: jdbc url写错,重新配置
3.踩坑
java.lang.Integer cannot be cast to java.math.BigDecimal
解决:数据库中的数据与hdfs上的数据无法转换,增加数据或者替换数据。
sqoop2相关实例:hdfs和mysql互相导入(转)的更多相关文章
- 使用MapReduce将mysql数据导入HDFS
package com.zhen.mysqlToHDFS; import java.io.DataInput; import java.io.DataOutput; import java.io.IO ...
- 使用 sqoop 将mysql数据导入到hdfs(import)
Sqoop 将mysql 数据导入到hdfs(import) 1.创建mysql表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` va ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- MySQL数据导入导出方法与工具mysqlimport
MySQL数据导入导出方法与工具mysqlimport<?xml:namespace prefix = o ns = "urn:schemas-microsoft-com:office ...
- MySQL导出导入命令的用例
1.导出整个数据库 mysqldump -u 用户名 -p 数据库名 > 导出的文件名 mysqldump -u wcnc -p smgp_apps_wcnc > wcnc.sql 2.导 ...
- MYSQL 数据库导入导出命令
MySQL命令行导出数据库 1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录 如我输入的命令行:cd C:\Program Files\MySQL\MySQL Serve ...
- MYSQL数据库导入导出(可以跨平台)
MYSQL数据库导入导出.sql文件 转载地址:http://www.cnblogs.com/cnkenny/archive/2009/04/22/1441297.html 本人总结:直接复制数据库, ...
- mysql数据导入
1.windows解压 2.修改文件名,例如a.txt 3.rz 导入到 linux \data\pcode sudo su -cd /data/pcode/rm -rf *.txt 4.合并到一个文 ...
- SQL[连载2]语法及相关实例
SQL[连载2]语法及相关实例 SQL语法 数据库表 一个数据库通常包含一个或多个表.每个表由一个名字标识(例如:"Websites"),表包含带有数据的记录(行). 在本教程中, ...
随机推荐
- 高系统的分布性有状态的中间层Actor模型
写在前面 https://www.cnblogs.com/gengzhe/p/ray_actor.html Orleans是基于Actor模型思想的.NET领域的框架,它提供了一种直接而简单的方法来构 ...
- Maven ------ 了解与安装
1.什么是Maven Maven :项目对象模型(POM),可以通过一段描述信息来管理项目的构建,报告和文档的项目管理工具软件, maven 来自犹太语意为知识的积累,为了在项目中简化构建过程,最直观 ...
- Java面试宝典(2020版)
一.Java 基础 1. JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境. JRE:Java ...
- 华为 S5700 交换机 批量修改端口方法
常常在配置交换机端口的时候需要将多个端口设置为相同的配置,当时各端口逐一去配置不仅慢,而且容易出错,这个时候就需要对端口进行批量设置,不仅快捷,而且避免了反复输出容易出错的情况.不同系列.不同版本交换 ...
- Java可视化计算器
利用java中的AWT和SWING包来做可视化界面. 首先来简单了解一下这两个包: AWT和Swing都是Java中用来做可视化界面的.AWT(Abstract Window Toolkit):抽象窗 ...
- c#十进制转换
1.方法定义 /// <summary> /// 十进制转换 /// </summary> /// <param name="hexChar"> ...
- Java Mockito 笔记
Mockito 1 Overview 2 Maven 项目初始化 3 示例 3.1 第一个示例 3.2 自动 Mock 3.3 Mock 返回值 3.4 Mock 参数 3.5 自动注入 Mock 对 ...
- 利用cv与matplotlib.pyplot读图片与显示图片
import matplotlib.pyplot as pltimport cv2 as cva=cv.imread('learn.jpg')cv.imshow('learn',a)fig=plt.f ...
- Python进阶----多表查询(内连,左连,右连), 子查询(in,带比较运算符)
Python进阶----多表查询(内连,左连,右连), 子查询(in,带比较运算符) 一丶多表查询 多表连接查询的应用场景: 连接是关系数据库模型的主要特点,也是区别于其他 ...
- 2年java,蚂蚁一面,卒
其实我一个都没答上来.并不是因为我笨,是因为我不会.在大扰的帮助下,现在我会了,求求你再给我一个机会. TreeSet/HashSet 区别 顾名思义,首先是结构上的不同 1.TreeSet背后的结构 ...