机器学习 降维算法: isomap & MDS
最近在看论文的时候看到论文中使用isomap算法把3D的人脸project到一个2D的image上。提到降维,我的第一反应就是PCA,然而PCA是典型的线性降维,无法较好的对非线性结构降维。ISOMAP是‘流形学习’中的一个经典算法,流形学习贡献了很多降维算法,其中一些与很多机器学习算法也有结合,先粗糙的介绍一下’流形学习‘。
流形学习
流形学习应该算是个大课题了,它的基本思想就是在高维空间中发现低维结构。比如这个图:
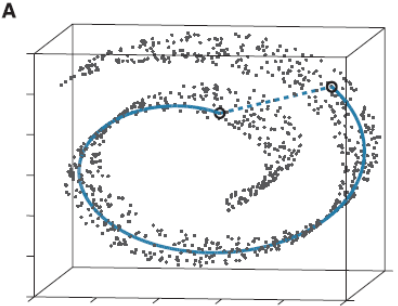
这些点都处于一个三维空间里,但我们人一看就知道它像一块卷起来的布,图中圈出来的两个点更合理的距离是A中蓝色实线标注的距离,而不是两个点之间的欧式距离(A中蓝色虚线)。
此时如果你要用PCA降维的话,它根本无法发现这样卷曲的结构(因为PCA是典型的线性降维,而图示的结构显然是非线性的),最后的降维结果就会一团乱麻,没法很好的反映点之间的关系。而流形学习在这样的场景就会有很好的效果。
经典MDS(Multidimensional Scaling)
如上文所述,MDS接收的输入是一个距离矩阵DD,我们把一些点画在坐标系里:

如果只告诉一个人这些点之间的距离(假设是欧氏距离),他会丢失那些信息呢?
a.我们对点做平移,点之间的距离是不变的。
b.我们对点做旋转、翻转,点之间的距离是不变的。
所以想要从D还原到原始数据X是不可能的,因为只给了距离信息之后本身就丢掉了很多东西,不过不必担心,即使这样我们也可以对数据进行降维(why?点这里)。
ISOMAP(等距特征映射)
其实线性流形方法无法在非线性流形上解决的问题,无非是需要解决两个问题:
1、如何测量流形上的几何距离?
2、如何将高维的2016维欧式空间映射到三维的低维空间?
首先,针对问题1,将MDS算法中的欧式距离换成“测地距离”,先抛一个“测地线的维基定义”。预热以后,我们来看经典的瑞士卷(图A),注意以下图A、B、C均来源于原文论文Fig3截图:
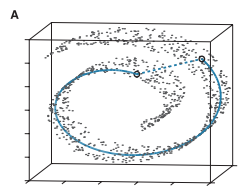
现在要我们把自己想象成是瑞士卷上的蚂蚁(对人类来说瑞士卷是三维的,对蚂蚁来说是二维的),上图A中的两个黑色圈圈为两只恩爱无比的蚂蚁,如何让这两只蚂蚁在最短的时间内见面呢?要走最短路径测地线蓝色线才是正道(直线最短?直接沿着虚线强行阔过去?你不想活了么?)因此,抛弃欧式距离,引来测地距离~
邻近点:直接计算邻近点之间的欧式空间距离
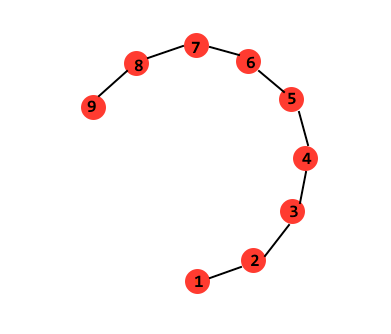
远距离的点:计算邻近点之间的最短距离连接成的序列,如下图所示(来源于博客),要计算空间中远距离的亮点1与9,计算1到9的最短路径1、2、3...9,沿着路径依次类推直到到达目的地9(根据流形中的全局非线性和局部线性属性):
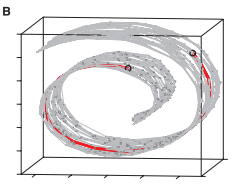
最后形成如下图所示的瑞士卷上的逼近测地线,如下图B中的红色线条所示:
实现方法:引入图论框架,将数据作为图中的点,点与其邻近点之间使用边来连接,逼近的测地线使用最短路径代替。
Isomap算法流程如下:
步骤1:构建邻接图G(复杂度:O(DN2))
基于输入空间X中流形G上的的邻近点对i,j之间的欧式距离dx (i,j),选取每个样本点距离最近的K个点(K-Isomap)或在样本点选定半径为常数ε的圆内所有点为该样本点的近邻点,将这些邻近点用边连接,将流形G构建为一个反映邻近关系的带权流通图G;
步骤2:计算所有点对之间的最短路径(复杂度:O(DN2))
通过计算邻接图G上任意两点之间的最短路径逼近流形上的测地距离矩阵DG={dG(i,j)},最短路径的实现以Floyd或者Dijkstra算法为主。
步骤3:构建k维坐标向量(复杂度:O(dN2))
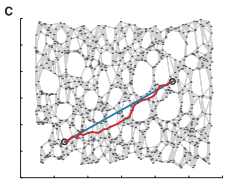
根据图距离矩阵DG={dG(i,j)}使用经典Mds算法在d维空间Y中构造数据的嵌入坐标表示(如下图C所示),选择低维空间Y的任意两个嵌入坐标向量yi与yj使得代价函数最小:
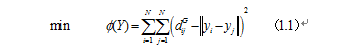
其中等式1.1的全局最优解可以通过将坐标向量yi设置为距离矩阵DG前d个特征值对应的特征向量来得到。
(还是偷懒了,没有去看看具体的例子,要用的时候再说把23333)
Reference:
[1] https://blog.csdn.net/dark_scope/article/details/53229427
[2] https://www.cnblogs.com/wing1995/p/5479036.html
机器学习 降维算法: isomap & MDS的更多相关文章
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- 【转】四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
最近在找降维的解决方案中,发现了下面的思路,后面可以按照这思路进行尝试下: 链接:http://www.36dsj.com/archives/26723 引言 机器学习领域中所谓的降维就是指采用某种映 ...
- 机器学习--降维算法:PCA主成分分析
引言 当面对的数据被抽象为一组向量,那么有必要研究一些向量的数学性质.而这些数学性质将成为PCA的理论基础. 理论描述 向量运算即:内积.首先,定义两个维数相同的向量的内积为: (a1,a2,⋯,an ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 降维算法整理--- PCA、KPCA、LDA、MDS、LLE 等
转自github: https://github.com/heucoder/dimensionality_reduction_alo_codes 网上关于各种降维算法的资料参差不齐,同时大部分不提供源 ...
- 机器学习: t-Stochastic Neighbor Embedding 降维算法 (一)
Introduction 在计算机视觉及机器学习领域,数据的可视化是非常重要的一个应用,一般我们处理的数据都是成百上千维的,但是我们知道,目前我们可以感知的数据维度最多只有三维,超出三维的数据是没有办 ...
- 机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现
简述 在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响.同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或 ...
- 机器学习: t-Stochastic Neighbor Embedding 降维算法 (二)
上一篇文章,我们介绍了SNE降维算法,SNE算法可以很好地保持数据的局部结构,该算法利用条件概率来衡量数据点之间的相似性,通过最小化条件概率 pj|i 与 pi|j 之间的 KL-divergence ...
- 机器学习实战基础(二十):sklearn中的降维算法PCA和SVD(一) 之 概述
概述 1 从什么叫“维度”说开来 我们不断提到一些语言,比如说:随机森林是通过随机抽取特征来建树,以避免高维计算:再比如说,sklearn中导入特征矩阵,必须是至少二维:上周我们讲解特征工程,还特地提 ...
随机推荐
- go语言new和make
1.new func new(Type) *Type 内建函数,内建函数 new 用来分配内存,它的第一个参数是一个类型,它的返回值是一个指向新分配类型默认值的指针! 2.make func make ...
- Vector(动态数组)怎么用咧↓↓↓
定义方式:vector<int> a; //二维vector<int>a[100] 在末尾压入容器:a.push_back(x);//二维 a[i].push_back(x) ...
- ASCII编码(以备不时之需)
- Ubuntu 安装MySQL报共享库找不到
错误信息1: ./mysqld: error : cannot open shared object file: No such file or directory 解决办法:安装改库 # apt-g ...
- CTF PHP反序列化
目录 php反序列化 一.序列化 二.魔术方法 1.构造函数和析构函数 2.__sleep()和__wakeup() 3.__toString() 4.__set(), __get(), __isse ...
- js十大排序算法收藏
十大经典算法排序总结对比 转载自五分钟学算法&https://www.cnblogs.com/AlbertP/p/10847627.html 一张图概括: 主流排序算法概览 名词解释: n: ...
- 爬虫urllib2 的异常错误处理URLError和HTTPError
urllib2 的异常错误处理 在我们用urlopen或opener.open方法发出一个请求时,如果urlopen或opener.open不能处理这个response,就产生错误. 这里主要说的是U ...
- JavaScript之 BOM 与 DOM
1. JavaScript 组成 2. DOM.DOCUMENT.BOM.WINDOW 区别 DOM 是为了操作文档出现的 API , document 是其的一个对象:BOM 是为了操作浏览器出现的 ...
- 170道python面试题(转)
作者:麋鹿链接:https://www.zhihu.com/question/54513391/answer/779646691来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- [LeetCode] 582. Kill Process 终止进程
Given n processes, each process has a unique PID (process id) and its PPID (parent process id). Each ...