yandex 图片自动下载
yandex 图片自动下载命令行程序
一个在 yandex 上搜索图片并下载到本地的 node cli 程序.
使用帮助:
$0 <搜索关键词> [-t=超时(默认 1000)] [-r 是否替换下载(默认 false)]
示例:
$0 shop # 搜索 shop 并下载
$0 shop -t=0 # 不使用超时
$0 shop -t=0 -r # 覆盖重名文件
一个群友让做的程序, ¥100. 需求就是使用 yandex 搜索图片, 并自动下载到本地.
分析
- 打开 https://yandex.com/images/search?text=shop
- 查看 images/search? 请求, p={当前页数}
- 返回结果 blocks[0].params.lastPage 是最大页数
- 返回结果中所有 img_url={原图地址}
win 下简单的命令行交互
这里用批处理实现, 其实 node 中也可以做交互的.
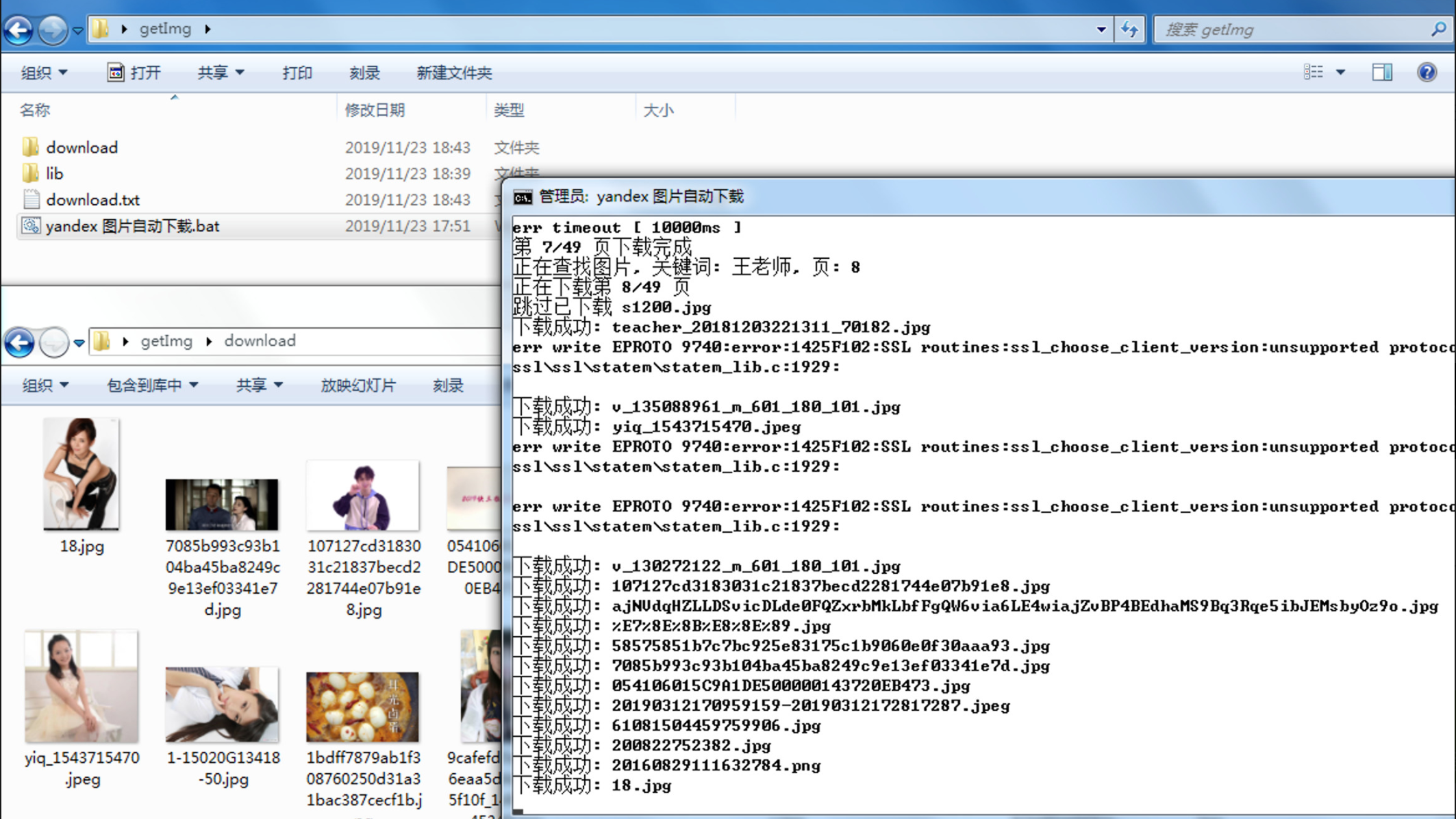
C:.
│ yandex 图片自动下载.bat
│
└─lib
node_modules
index.js
node.exe
yandex 图片自动下载.bat 文件内容
color f0 && chcp 936 && cls && @echo off
title yandex 图片自动下载
mode con cols=120 lines=30
:down
set /p keyword=输入关键词开始下载:
.\lib\node.exe .\lib\index.js "%keyword%"
echo ==========================
echo 全部下载完成
goto :down
源码
index.js
const fs = require('fs')
const url = require('url')
const path = require('path')
const fly = require('flyio')
const text = process.argv[2]
if(text === undefined) {
console.log(`
使用帮助:
$0 <搜索关键词> [-t=超时(默认 10000)] [-r 是否替换下载(默认 false)]
示例:
$0 shop # 搜索 shop 并下载
$0 shop -t=0 # 不使用超时
$0 shop -t=0 -r # 覆盖重名文件
`)
return
}
const argv = parseArgv()
const userConfig = {
text, // 用户搜索的关键词
timeout: argv['-t'] === undefined ? 10000 : Number(argv['-t']), // 设置超时时间, 默认 10 秒
replace: argv['-r'] || false, // 是否替换下载, 默认否
}
const config = userConfig
fly.config.timeout = config.timeout
const downHistoryFile = `${process.cwd()}/download.txt`
fs.writeFileSync(downHistoryFile, '')
const downDir = `${process.cwd()}/download`
new Promise(async () => {
let text = userConfig.text
let {urls: lastUrls = [], lastPage = 0} = (await getImgUrls({text}).catch(err => console.log('err', err))) || {}
if(lastPage === 0) {
console.log('没有搜索结果, 你可以更换关键词重试')
return
}
for (let p = 0; p < lastPage; p++) {
let curPage = p + 1
let urls = []
if(curPage === 1) {
urls = lastUrls
} else {
let getRes = await getImgUrls({text, p: curPage}).catch(err => console.log('err', err))
urls = (getRes || {}).urls || [] // 获取页数
}
urls = [...new Set(urls)] // 去除重复的 url
// urls = urls.slice(0, 3)
const paseUrls = []
urls.map(item => {
const {pathname, href} = url.parse(item)
let {base, ext, name} = path.parse(pathname);
ext = ext || '.jpg' // 如果没有扩展名时, 默认给定为 jpg
// let fullName = paseUrls.find(item => item.fullName === base) // 如果保存文件名重复, 则添加时间戳处理
// ? `${name}_${uuid()}_${ext}`
// : base
// let fullName = `${name}_${uuid()}_${ext}`
let fullName = `${name || uuid()}${ext}`
paseUrls.push({
name,
fullName,
href,
})
})
console.log(`正在下载第 ${curPage}/${lastPage} 页`)
await Promise.all(paseUrls.map(item => download(item.href, item.fullName))).finally(async () => {
console.log(`第 ${curPage}/${lastPage} 页下载完成`)
})
}
})
function hasFile(filePath) {
return fs.existsSync(filePath)
}
function parseArgv() {
return process.argv.slice(2).reduce((acc, arg) => {
let [k, v = true] = arg.split('=')
acc[k] = v
return acc
}, {})
}
async function getImgUrls(arg = {}) {
arg = {
text: 'shop',
p: 1,
...arg,
}
return new Promise((resolve, reject) => {
console.log(`正在查找图片, 关键词: ${arg.text}, 页: ${arg.p}`)
let api = `https://yandex.com/images/search?format=json&request=%7B%22blocks%22%3A%5B%7B%22block%22%3A%22serp-controller%22%2C%22params%22%3A%7B%7D%2C%22version%22%3A2%7D%2C%7B%22block%22%3A%22serp-list_infinite_yes%22%2C%22params%22%3A%7B%22initialPageNum%22%3A0%7D%2C%22version%22%3A2%7D%2C%7B%22block%22%3A%22more_direction_next%22%2C%22params%22%3A%7B%7D%2C%22version%22%3A2%7D%2C%7B%22block%22%3A%22gallery__items%3Aajax%22%2C%22params%22%3A%7B%7D%2C%22version%22%3A2%7D%5D%2C%22bmt%22%3A%7B%22lb%22%3A%22%22%7D%2C%22amt%22%3A%7B%22las%22%3A%22justifier-height%3D1%3Bthumb-underlay%3D1%3Bjustifier-setheight%3D1%3Bfitimages-height%3D1%3Bjustifier-fitincuts%3D1%3Bchunk.219.0%3D1%3Bchunk.169.0%3D1%22%7D%7D&yu=2650822041574437239&p=${arg.p}&text=${encodeURIComponent(arg.text)}&rpt=image&uinfo=sw-1920-sh-1200-ww-905-wh-1045-pd-2-wp-16x10_2560x1600`
// console.log('api', api)
fly.get(api)
.then(res => {
const data = res.data
handleData(data, r => resolve(r))
}).catch(err => {
reject(err)
})
})
}
function execSync(cmd, out = false) {
const child_process = require('child_process')
let str = child_process.execSync(cmd).toString().trim()
out && console.log(str)
return str
}
async function handleData(data, cb) {
try {
const lastPage = data.blocks[0].params.lastPage
const urls = []
data.blocks.forEach(item => {
(item.html.match(/img_url=.*?&/g) || []).forEach(item => {
urls.push(decodeURIComponent((item.match(/img_url=(.*?)&/) || [])[1] || ""))
})
})
cb({
lastPage,
urls,
})
} catch (error) {
console.log('error', error)
cb({
msg: '搜索结果出现错误',
error,
lastPage: 0,
urls: [],
})
}
}
async function download(u, p) {
fs.writeFileSync(downHistoryFile, fs.readFileSync(downHistoryFile) + u + '\r\n')
const savePath = `${downDir}/${p}`
if(!config.replace && hasFile(savePath)) {
console.log(`跳过已下载 ${p}`)
return true
} else {
if(!hasFile(downDir)) {
fs.mkdirSync(downDir)
}
return fly.download(u, savePath)
.then(d => {
console.log(`下载成功: ${p}`)
})
.catch(err => console.log('err', err.message))
}
}
function uuid(sep = '') {
let increment = process.increment === undefined ? (process.increment = 1) : (process.increment = (process.increment + 1))
return `${Date.now()}_${increment}`.replace(/_/g, sep)
}
package.json
{
"name": "getImg",
"version": "1.0.0",
"description": "",
"main": "index.js",
"keywords": [],
"author": "xw",
"dependencies": {
"flyio": "^0.6.14",
"request": "^2.88.0"
},
"license": "ISC"
}
注:
本程序有个小问题, 懒得解决, 看大家能不能发现.
yandex 图片自动下载的更多相关文章
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- MIT-Adobe FiveK Dataset 图片自动下载
MIT-Adobe FiveK Dataset 图片自动下载 MIT-Adobe FiveK是现在很多做图像增强(image enhancement)与图像修饰(image retouching)方面 ...
- 【Python开发】【神经网络与深度学习】网络爬虫之图片自动下载器
python爬虫实战--图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识(没看的赶紧去看)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap show ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- dedecms复制网上的带有图片的文章,图片不能自动下载到本地的解决方法
dede有时看到比较好的文章需要复制,粘贴到自己的dede后台发布,dede是有图片自动本地化的功能,就是复制过来后自动下载到你的服务器上了,这样省去了你单独去另存图片再上传的过程,尤其是遇到有很多图 ...
- 基于.NetCore开发博客项目 StarBlog - (17) 自动下载文章里的外部图片
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...
- 【壁纸自动换】自动下载、更换壁纸(Bing壁纸)--XinBSBingWallPaper[2.7更新]
XinBSBingWallPaper主要功能: 1.支持自动下载Bing壁纸.Netbian壁纸.美国国家地理杂志图片. 2.自动搜索.下载多国Bing首页壁纸. 3.支持定时自动更换桌面壁纸. 4. ...
- JS图片自动或者手动滚动效果(支持left或者up)
JS图片自动或者手动滚动效果(支持left或者up) JS图片自动或者手动滚动效果 在谈组件之前 来谈谈今天遇到搞笑的事情,今天上午接到一个杭州电话 0571-28001187 即说是杭州人民法院的 ...
随机推荐
- Redis持久化 - RDB和AOF
原文:https://segmentfault.com/a/1190000016021217 一.持久化的作用 1. 什么是持久化 持久化(Persistence),即把数据(如内存中的对象)保存到可 ...
- Beta冲刺博客汇总(校园帮-追光的人)
所属课程 软件工程1916 作业要求 Beta冲刺博客汇总 团队名称 追光的人 作业目标 汇总Beta阶段的博客,方便查看 冲刺日志 Beta之前-凡事预则立(校园帮-追光的人)5-22 Beta冲刺 ...
- servlet 容器与servlet
servlet代表应用 解析Tomcat内部结构和请求过程 https://www.cnblogs.com/zhouyuqin/p/5143121.html servlet的本质是什么,它是如何工作的 ...
- 数据库join解释 与视图
数据库的视图是表运算的结果. 数据库的表是数据单元: join是运算符: 视图是运算结果. 数据库join解释 1.join:将两个表结构连接成一个视图 2.left.right.inner: 从基准 ...
- 上传OSS报错
修改OSS
- ent 基本使用十五 一个图遍历的例子
以下是来自官方的一个user group pet 的查询demo 参考关系图 环境准备 docker-compose mysql 环境 version: "3" services: ...
- MyBatis框架,增删改查
一.recourses中核心配置文件mybatis-config.xml 二. recourse中jdbc.properties 三.entity实体类 四.Dao层 五.ISmbmsUserDao. ...
- Python-DDT框架
Install pip install ddt 实例 import unittest from ddt import ddt, data, unpack @ddt class MyTestCase(u ...
- oracle 如何快速删除两表非关联数据(脏数据)?
1.情景展示 现在有两者表,表1中的主键id字段和表2的index_id相对应.如何删除两表非关联数据? 2.解决方案 --第1步 delete from VIRTUAL_CARD t where ...
- 系统性能工具篇(sar)
转自:系统性能工具篇(sar) 1. 介绍 内容很多 是sysstat软件包的一部分 自动运行:/etc/crontab/sysstat $ cat /etc/cron.d/sysstat # The ...