CUDA ---- 简介
CUDA简介
CUDA是并行计算的平台和类C编程模型,我们能很容易的实现并行算法,就像写C代码一样。只要配备的NVIDIA GPU,就可以在许多设备上运行你的并行程序,无论是台式机、笔记本抑或平板电脑。熟悉C语言可以帮助你尽快掌握CUDA。
CUDA编程
CUDA编程允许你的程序执行在异构系统上,即CUP和GPU,二者有各自的存储空间,并由PCI-Express 总线区分开。因此,我们应该先注意二者术语上的区分:
- Host:CPU and itsmemory (host memory)
- Device: GPU and its memory (device memory)
代码中,一般用h_前缀表示host memory,d_表示device memory。
kernel是CUDA编程中的关键,他是跑在GPU的代码,用标示符__global__注明。
host可以独立于host进行大部分操作。当一个kernel启动后,控制权会立刻返还给CPU来执行其他额外的任务。所以,CUDA编程是异步的。一个典型的CUDA程序包含由并行代码补足的串行代码,串行代码由host执行,并行代码在device中执行。host端代码是标准C,device是CUDA C代码。我们可以把所有代码放到一个单独的源文件,也可以使用多个文件或库。NVIDIA C编译器(nvcc)可以编译host和device生成可执行程序。
这里再次说明下CUDA程序的处理流程:
- 从CPU拷贝数据到GPU。
- 调用kernel来操作存储在GPU的数据。
- 将操作结果从GPU拷贝至CPU。
Memory操作
cuda程序将系统区分成host和device,二者有各自的memory。kernel可以操作device memory,为了能很好的控制device端内存,CUDA提供了几个内存操作函数:

为了保证和易于学习,CUDA C 的风格跟C很接近,比如:
cudaError_t cudaMalloc ( void** devPtr, size_t size )
我们主要看看cudaMencpy,其函数原型为:
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count,cudaMemcpyKind kind )
其中cudaMemcpykind的可选类型有:
- cudaMemcpyHostToHost
- cudaMemcpyHossToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpuDeviceToDevice
具体含义很好懂,就不多做解释了。
对于返回类型cudaError_t,如果正确调用,则返回cudaSuccess,否则返回cudaErrorMemoryAllocation。可以使用char* cudaGetErrorString(cudaError_t error)将其转化为易于理解的格式。
组织线程
掌握如何组织线程是CUDA编程的重要部分。CUDA线程分成Grid和Block两个层次。
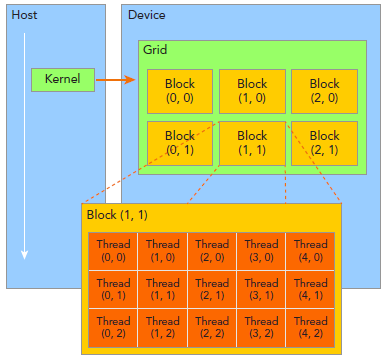
由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。一个grid由许多block组成,block由许多线程组成,grid和block都可以是一维二维或者三维,上图是一个二维grid和二维block。
这里介绍几个CUDA内置变量:
- blockIdx:block的索引,blockIdx.x表示block的x坐标。
- threadIdx:线程索引,同理blockIdx。
- blockDim:block维度,上图中blockDim.x=5.
- gridDim:grid维度,同理blockDim。
一般会把grid组织成2D,block为3D。grid和block都使用dim3作为声明,例如:
dim3 block();
// 后续博文会解释为何这样写grid
dim3 grid((nElem+block.x-)/block.x);
需要注意的是,dim3仅为host端可见,其对应的device端类型为uint3。
启动CUDA kernel
CUDA kernel的调用格式为:
kernel_name<<<grid, block>>>(argument list);
其中grid和block即为上文中介绍的类型为dim3的变量。通过这两个变量可以配置一个kernel的线程总和,以及线程的组织形式。例如:
kernel_name<<<4, 8>>>(argumentt list);
该行代码表明有grid为一维,有4个block,block为一维,每个block有8个线程,故此共有4*8=32个线程。

注意,不同于c函数的调用,所有CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。
函数类型标示符

__device__ 和__host__可以组合使用。
kernel的限制:
- 仅能获取device memory 。
- 必须返回void类型。
- 不支持可变数目参数。
- 不支持静态变量。
- 不支持函数指针。
- 异步。
代码分析
#include <cuda_runtime.h>
#include <stdio.h>
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if (error != cudaSuccess) \
{ \
printf("Error: %s:%d, ", __FILE__, __LINE__); \
printf("code:%d, reason: %s\n", error, cudaGetErrorString(error)); \
exit(); \
} \
}
void checkResult(float *hostRef, float *gpuRef, const int N) {
double epsilon = 1.0E-8;
bool match = ;
for (int i=; i<N; i++) {
if (abs(hostRef[i] - gpuRef[i]) > epsilon) {
match = ;
printf("Arrays do not match!\n");
printf("host %5.2f gpu %5.2f at current %d\n",hostRef[i],gpuRef[i],i);
break;
}
}
if (match) printf("Arrays match.\n\n");
}
void initialData(float *ip,int size) {
// generate different seed for random number
time_t t;
srand((unsigned) time(&t));
for (int i=; i<size; i++) {
ip[i] = (float)( rand() & 0xFF )/10.0f;
}
}
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int idx=; idx<N; idx++)
C[idx] = A[idx] + B[idx];
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main(int argc, char **argv) {
printf("%s Starting...\n", argv[]);
// set up device
int dev = ;
cudaSetDevice(dev);
// set up data size of vectors
int nElem = ;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, , nBytes);
memset(gpuRef, , nBytes);
// malloc device global memory
float *d_A, *d_B, *d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);
// transfer data from host to device
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
// invoke kernel at host side
dim3 block (nElem);
dim3 grid (nElem/block.x);
sumArraysOnGPU<<< grid, block >>>(d_A, d_B, d_C);
printf("Execution configuration <<<%d, %d>>>\n",grid.x,block.x);
// copy kernel result back to host side
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
// add vector at host side for result checks
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// check device results
checkResult(hostRef, gpuRef, nElem);
// free device global memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return();
}
编译指令:$nvcc sum.cu -o sum
运行: $./sum
输出:
./sum Starting...
Vector size
Execution configuration <<<, >>>
Arrays match.
代码下载:CodeSamples.zip
CUDA ---- 简介的更多相关文章
- 显卡、GPU和CUDA简介
http://blog.csdn.net/wu_nan_nan/article/details/45603299 声明: 本文部分内容来自网络.由于知识有限,有错误的地方还请指正.本帖为自己学习过程的 ...
- 【CUDA并行程序设计系列(1)】GPU技术简介
http://www.cnblogs.com/5long/p/cuda-parallel-programming-1.html 本系列目录: [CUDA并行程序设计系列(1)]GPU技术简介 [CUD ...
- centos7.0安装cuda驱动
00.CUDA简介 CUDA和GPU的并行处理能力来加速深度学习和其他计算密集型应用程序 01.CPU+GPU协同架构 02.部署环境 [docker@lab-250 ~]$ cat /etc/*re ...
- CUDA学习笔记1:第一个CUDA实例
一.cuda简介 CUDA是支持c++/c语言,一般我喜欢用c来写,他的编译是gpu部分由nvcc来进行的 一般的函数定义 void function(); cuda的函数定义 __global ...
- 【并行计算-CUDA开发】CUDA软件架构与Nvidia硬件对应关系
前面扯了很多,不过大多都是在讲CUDA 在软体层面的东西:接下来,虽然Heresy 自己也不熟,不过还是来研究一下硬体的部分吧-毕竟要最佳化的时候,好像还是要大概知道一下相关的东西的.这部分主要参考资 ...
- Windows 10下CUDA及cuDNN的安装 —— Pytorch
Windows 10下CUDA及cuDNN的安装 CUDA简介与下载地址 CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台. CU ...
- TensorFlow在Windows上的CPU版本和GPU版本的安装指南(亲测有效)
安装说明 平台:Window.Ubuntu.Mac等操作系统 版本:支持GPU版本和CPU版本 安装方式:pip方式.Anaconda方式 attention: 在Windows上目前支持python ...
- TensorFlow安装解惑
本文整理自网络,若有侵犯请告知. 1.安装环境 目前TensorFlow社区推荐的环境是Ubuntu, 但是TensorFlow同时支持Mac,Windows上的安装部署. 2.关于GPU版本 因为深 ...
- CUDA ---- CUDA库简介
CUDA Libraries简介 上图是CUDA 库的位置,本文简要介绍cuSPARSE.cuBLAS.cuFFT和cuRAND,之后会介绍OpenACC. cuSPARSE线性代数库,主要针对稀疏矩 ...
随机推荐
- Java日志框架 (commons-logging,log4j,slf4j,logback)
转自:http://blog.csdn.net/kobejayandy/article/details/17335407 如果对于commons-loging.log4j.slf4j.LogBack等 ...
- [LightOJ1004]Monkey Banana Problem(dp)
题目链接:http://lightoj.com/login_main.php?url=volume_showproblem.php?problem=1004 题意:数塔的变形,上面一个下面一个,看清楚 ...
- Ubuntu 安装vsftp软件(已测试)
首先开启Ftp端口 使用apt-get命令安装vsftp #apt-get install vsftpd -y 添加ftp帐号和目录 先检查一下nologin的位置,通常在/usr/sbin/nolo ...
- Jenkins+Maven+Git搭建持续集成和自动化部署的配置手记
前言 持续集成这个概念已经成为软件开发的主流,可以更频繁的进行测试,尽早发现问题并提示.自动化部署就更不用说了,可以加快部署速度,并可以有效减少人为操作的失误.之前一直没有把这个做起来,最近的新 ...
- css中图片的四种地址引用
URL: CSS中四种引用图片asset的方式:
- LA 3983 Robotruck
这道题感觉挺吃力的,还用到了我不熟悉的优先队列 题目中的推导也都看明白了,总之以后还要多体会才是 这里用优先对列的原因就是因为要维护一个滑动区间的最小值,比如在区间里2在1的前面,2在离开这个滑动区间 ...
- Core Text
Core Text 本文所涉及的代码你可以在这里下载到 https://github.com/kejinlu/CTTest,包含两个项目,一个Mac的NSTextView的测试项目,一个iOS的Cor ...
- 【JavaScript学习笔记】画图
<!DOCTYPE HTML> <html> <head> <script type="text/javascript"> var ...
- js模拟实现继承功能
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- ORA-00257错误
Archiver error,connect internal only,until freed 表示归档日志目录已满,用户不能再连接数据库,现有用户可继续查询数据库,但是不能执行DML语句 插删 ...